Kafka与Logstash的数据采集
Kafka与Logstash的数据采集
基于Logstash跑通Kafka还是需要注意很多东西,最重要的就是理解Kafka的原理。
Logstash工作原理
由于Kafka采用解耦的设计思想,并非原始的发布订阅,生产者负责产生消息,直接推送给消费者。而是在中间加入持久化层——broker,生产者把数据存放在broker中,消费者从broker中取数据。这样就带来了几个好处:
- 1 生产者的负载与消费者的负载解耦
- 2 消费者按照自己的能力fetch数据
- 3 消费者可以自定义消费的数量
另外,由于broker采用了主题topic-->分区的思想,使得某个分区内部的顺序可以保证有序性,但是分区间的数据不保证有序性。这样,消费者可以以分区为单位,自定义读取的位置——offset。
Kafka采用zookeeper作为管理,记录了producer到broker的信息,以及consumer与broker中partition的对应关系。因此,生产者可以直接把数据传递给broker,broker通过zookeeper进行leader-->followers的选举管理;消费者通过zookeeper保存读取的位置offset以及读取的topic的partition分区信息。
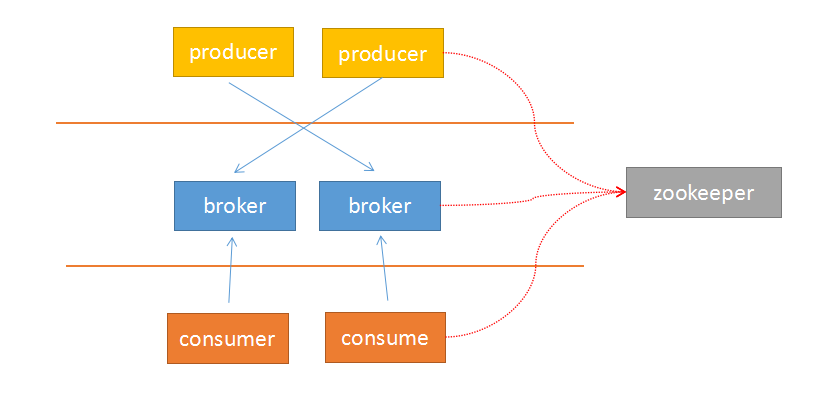
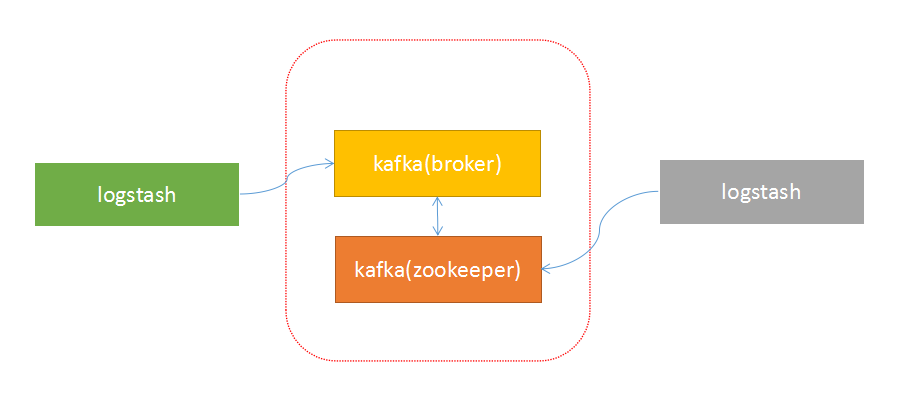
由于上面的架构设计,使得生产者与broker相连;消费者与zookeeper相连。有了这样的对应关系,就容易部署logstash-->kafka-->logstash的方案了。
接下来,按照下面的步骤就可以实现logstash与kafka的对接了。
启动kafka
启动zookeeper:
$zookeeper/bin/zkServer.sh start启动kafka:
$kafka/bin/kafka-server-start.sh $kafka/config/server.properties &创建主题
创建主题:
$kafka/bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --create --topic hello --replication-factor 1 --partitions 1查看主题:
$kafka/bin/kafka-topics.sh --zookeeper 127.0.0.1:2181 --describe测试环境
执行生产者脚本:
$kafka/bin/kafka-console-producer.sh --broker-list 10.0.67.101:9092 --topic hello执行消费者脚本,查看是否写入:
$kafka/bin/kafka-console-consumer.sh --zookeeper 127.0.0.1:2181 --from-beginning --topic hello输入测试
input{
stdin{}
}
output{
kafka{
topic_id => "hello"
bootstrap_servers => "192.168.0.4:9092" # kafka的地址
batch_size => 5
}
stdout{
codec => rubydebug
}
}读取测试
logstash配置文件:
input{
kafka {
codec => "plain"
group_id => "logstash1"
auto_offset_reset => "smallest"
reset_beginning => true
topic_id => "hello"
#white_list => ["hello"]
#black_list => nil
zk_connect => "192.168.0.5:2181" # zookeeper的地址
}
}
output{
stdout{
codec => rubydebug
}
}Kafka与Logstash的数据采集的更多相关文章
- Kafka与Logstash的数据采集对接 —— 看图说话,从运行机制到部署
基于Logstash跑通Kafka还是需要注意很多东西,最重要的就是理解Kafka的原理. Logstash工作原理 由于Kafka采用解耦的设计思想,并非原始的发布订阅,生产者负责产生消息,直接推送 ...
- Kafka与Logstash的数据采集对接
Logstash工作原理 由于Kafka采用解耦的设计思想,并非原始的发布订阅,生产者负责产生消息,直接推送给消费者.而是在中间加入持久化层--broker,生产者把数据存放在broker中,消费者从 ...
- kafka(logstash) + elasticsearch 构建日志分析处理系统
第一版:logstash + es 第二版:kafka 替换 logstash的方案
- Kafka、Logstash、Nginx日志收集入门
Nginx作为网站的第一入口,其日志记录了除用户相关的信息之外,还记录了整个网站系统的性能,对其进行性能排查是优化网站性能的一大关键. Logstash是一个接收,处理,转发日志的工具.支持系统日志, ...
- 海量日志分析方案--logstash+kibnana+kafka
下图为唯品会在qcon上面公开的日志处理平台架构图.听后觉得有些意思,好像也可以很容易的copy一个,就动手尝试了一下. 目前只对flume===>kafka===>elacsticSea ...
- ELK架构下利用Kafka Group实现Logstash的高可用
系统运维的过程中,每一个细节都值得我们关注 下图为我们的基本日志处理架构 所有日志由Rsyslog或者Filebeat收集,然后传输给Kafka,Logstash作为Consumer消费Kafka里边 ...
- elk快速入门-Logstash
Logstash1.功能:数据输入,数据筛选,数据输出2.特性:数据来源中立性,支持众多数据源:如文件log file,指标,网站服务日志,关系型数据库,redis,mq等产生的数据3.beats:分 ...
- 实战之elasticsearch集群及filebeat server和logstash server
author:JevonWei 版权声明:原创作品 实战之elasticsearch集群及filebeat server和logstash server 环境 elasticsearch集群节点环境为 ...
- ELK 架构之 Logstash 和 Filebeat 安装配置
上一篇:ELK 架构之 Elasticsearch 和 Kibana 安装配置 阅读目录: 1. 环境准备 2. 安装 Logstash 3. 配置 Logstash 4. Logstash 采集的日 ...
随机推荐
- [HDU] 2795 Billboard [线段树区间求最值]
Billboard Time Limit: 20000/8000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total ...
- [UVA] 11991 - Easy Problem from Rujia Liu? [STL应用]
11991 - Easy Problem from Rujia Liu? Time limit: 1.000 seconds Problem E Easy Problem from Rujia Liu ...
- php爬虫的两种思路
写php爬虫可能最大的问题就是php脚本执行时间的问题了,对于这个问题,我找到了两种解决方法. 第一种通过代码set_time_limit(0)或者ini_set("max_executio ...
- VBS 操作注册表 十六进制
使用VBS操作注册表,通常使用RegRead/RegWrite/RegDelete方法,如: RegRead: 'read.vbs(将以下代码存为read.vbs文件) Dim OperationRe ...
- logstash 中的贪婪匹配
logstash 中的贪婪匹配: 10.252.142.174 - - [06/Sep/2016:08:41:36 +0800] "GET /api/validate/code/send?m ...
- Linux下core文件产生的一些注意问题
前面转载了一篇文章关于core文件的产生和调试使用的设置,但在使用有一些需要注意的问题,如 在什么情况 才会正确地产生core文件. 列出一些常见问题: 一,如何使用core文件 1. 使用core文 ...
- bzoj1755 [Usaco2005 qua]Bank Interest
Description Farmer John made a profit last year! He would like to invest it well but wonders how muc ...
- libeXosip2(1-2) -- How-To initiate, modify or terminate calls.
How-To initiate, modify or terminate calls. The eXtented eXosip stack eXosip2 offers a flexible API ...
- Linux服务器SNMP常用OID (转)
原文地址:http://www.haiyun.me/archives/linux-snmp-oid.html 收集整理一些Linux下snmp常用的OID,用做服务器监控很不错. 服务器负载: 1 2 ...
- Node.js 和Socket.IO 实现chat WEBIM
socket官方: http://socket.io/ 需求:实现WEB IM功能,数据从服务器PUSH 不是PULL websocket是基于HTML5的新特性,不兼容IE6,7,8 .. ...