Lucene学习总结之二:Lucene的总体架构
Lucene总的来说是:
- 一个高效的,可扩展的,全文检索库。
- 全部用Java实现,无须配置。
- 仅支持纯文本文件的索引(Indexing)和搜索(Search)。
- 不负责由其他格式的文件抽取纯文本文件,或从网络中抓取文件的过程。
在Lucene in action中,Lucene 的构架和过程如下图,
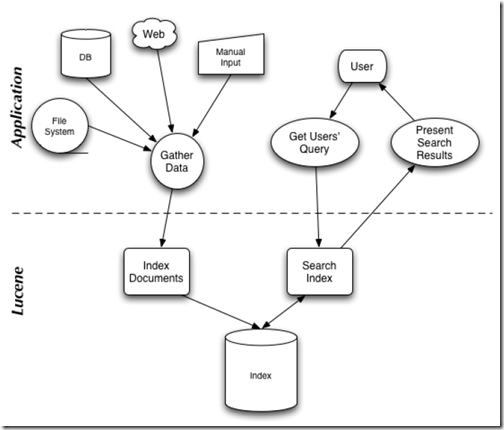
说明Lucene 是有索引和搜索的两个过程,包含索引创建,索引,搜索三个要点。
让我们更细一些看Lucene的各组件:
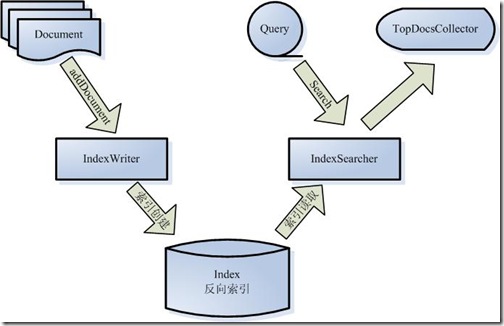
- 被索引的文档用Document对象 表示。
- IndexWriter 通过函数addDocument 将文档添加到索引中,实现创建索引的过程。
- Lucene 的索引是应用反向索引。
- 当用户有请求时,Query 代表用户的查询语句。
- IndexSearcher 通过函数search 搜索Lucene Index 。
- IndexSearcher 计算term weight 和score 并且将结果返回给用户。
- 返回给用户的文档集合用TopDocsCollector 表示。
那么如何应用这些组件呢?
让我们再详细到对Lucene API 的调用实现索引和搜索过程。
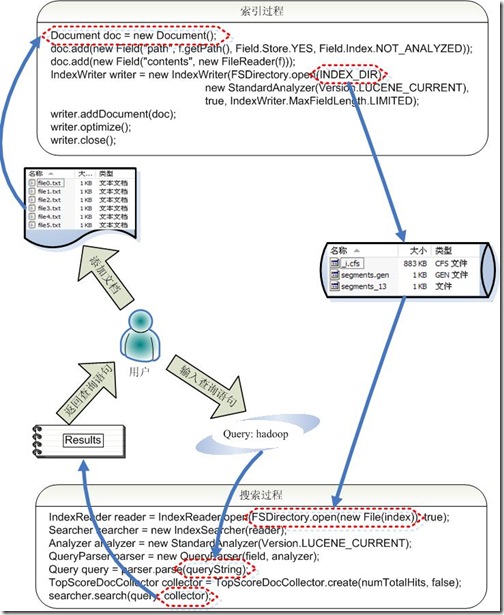
- 索引过程如下:
- 创建一个IndexWriter 用来写索引文件,它有几个参数,INDEX_DIR 就是索引文件所存放的位置,Analyzer 便是用来对文档进行词法分析和语言处理的。
- 创建一个Document 代表我们要索引的文档。
- 将不同的Field 加入到文档中。我们知道,一篇文档有多种信息,如题目,作者,修改时间,内容等。不同类型的信息用不同的Field 来表示,在本例子中,一共有两类信息进行了索引,一个是文件路径,一个是文件内容。其中FileReader 的SRC_FILE 就表示要索引的源文件。
- IndexWriter 调用函数addDocument 将索引写到索引文件夹中。
- 搜索过程如下:
- IndexReader 将磁盘上的索引信息读入到内存,INDEX_DIR 就是索引文件存放的位置。
- 创建IndexSearcher 准备进行搜索。
- 创建Analyer 用来对查询语句进行词法分析和语言处理。
- 创建QueryParser 用来对查询语句进行语法分析。
- QueryParser 调用parser 进行语法分析,形成查询语法树,放到Query 中。
- IndexSearcher 调用search 对查询语法树Query 进行搜索,得到结果TopScoreDocCollector 。
以上便是Lucene API函数的简单调用。
然而当进入Lucene的源代码后,发现Lucene有很多包,关系错综复杂。
然而通过下图,我们不难发现,Lucene的各源码模块,都是对普通索引和搜索过程的一种实现。
此图是上一节介绍的全文检索的流程对应的Lucene实现的包结构。(参照http://www.lucene.com.cn/about.htm 中文章《开放源代码的全文检索引擎Lucene》)
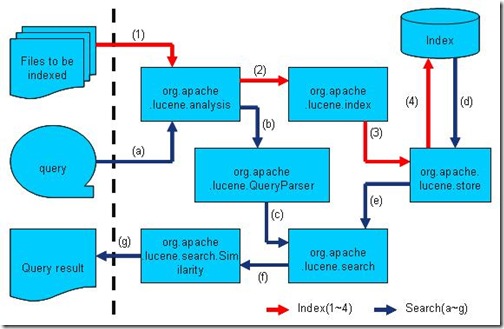
- Lucene 的analysis 模块主要负责词法分析及语言处理而形成Term 。
- Lucene 的index 模块主要负责索引的创建,里面有IndexWriter 。
- Lucene 的store 模块主要负责索引的读写。
- Lucene 的QueryParser 主要负责语法分析。
- Lucene 的search 模块主要负责对索引的搜索。
- Lucene 的similarity 模块主要负责对相关性打分的实现。
Lucene学习总结之二:Lucene的总体架构的更多相关文章
- Lucene学习总结之七:Lucene搜索过程解析
一.Lucene搜索过程总论 搜索的过程总的来说就是将词典及倒排表信息从索引中读出来,根据用户输入的查询语句合并倒排表,得到结果文档集并对文档进行打分的过程. 其可用如下图示: 总共包括以下几个过程: ...
- Lucene学习总结之七:Lucene搜索过程解析 2014-06-25 14:23 863人阅读 评论(1) 收藏
一.Lucene搜索过程总论 搜索的过程总的来说就是将词典及倒排表信息从索引中读出来,根据用户输入的查询语句合并倒排表,得到结果文档集并对文档进行打分的过程. 其可用如下图示: 总共包括以下几个过程: ...
- python源码学习(一)——python的总体架构
python源码学习(一)——python的总体架构 学习环境: 系统:ubuntu 12.04 STLpython版本:2.7既然要学习python的源码,首先我们要在电脑上安装python并且下载 ...
- Lucene学习总结之二:Lucene的总体架构 2014-06-25 14:12 622人阅读 评论(0) 收藏
Lucene总的来说是: 一个高效的,可扩展的,全文检索库. 全部用Java实现,无须配置. 仅支持纯文本文件的索引(Indexing)和搜索(Search). 不负责由其他格式的文件抽取纯文本文件, ...
- lucene学习笔记:二,Lucene的框架
Lucene总的来说是: 一个高效的,可扩展的,全文检索库. 全部用Java实现,无须配置. 仅支持纯文本文件的索引(Indexing)和搜索(Search). 不负责由其他格式的文件抽取纯文本文件, ...
- Lucene学习总结之三:Lucene的索引文件格式(1)
Lucene的索引里面存了些什么,如何存放的,也即Lucene的索引文件格式,是读懂Lucene源代码的一把钥匙. 当我们真正进入到Lucene源代码之中的时候,我们会发现: Lucene的索引过程, ...
- Lucene学习总结之三:Lucene的索引文件格式(1) 2014-06-25 14:15 1124人阅读 评论(0) 收藏
Lucene的索引里面存了些什么,如何存放的,也即Lucene的索引文件格式,是读懂Lucene源代码的一把钥匙. 当我们真正进入到Lucene源代码之中的时候,我们会发现: Lucene的索引过程, ...
- Lucene学习之一:使用lucene为数据库表创建索引,并按关键字查询
最近项目中要用到模糊查询,开始研究lucene,期间走了好多弯路,总算实现了一个简单的demo. 使用的lucene jar包是3.6版本. 一:建立数据库表,并加上测试数据.数据库表:UserInf ...
- Lucene学习总结之六:Lucene打分公式的数学推导
在进行Lucene的搜索过程解析之前,有必要单独的一张把Lucene score公式的推导,各部分的意义阐述一下.因为Lucene的搜索过程,很重要的一个步骤就是逐步的计算各部分的分数. Lucene ...
随机推荐
- 记“debug alipay”一事
背景:客户支付成功,无法返回支付结果 ===================================== 查找原因,追踪代码: verified = AlipayNotify.verify(p ...
- css3之gradient
radial-gradient The CSS radial-gradient() function creates an <image> which represents a gradi ...
- Js与Jq 获取浏览器和对象值的方法
JS and Jquery 都能获取页面元素的宽度,高度和相对位移等数值,那他们之间能相互转换或替代吗,写法又有哪些差异呢?本文将详细为你介绍. 1.Js获取浏览器高度和宽度document.docu ...
- Project Euler #80: Square root digital expansion
from decimal import getcontext, Decimal def main(): n = int(raw_input()) p = int(raw_input()) getcon ...
- Jasper_mainReport_excel html pdf 主报表中常用属性
jasper中,excel , html, pdf 一般可以使用相同的主报表和子报表.需要在主报表中添加不同格式对应的属性.导出不同格式的报表,编译器会将相应的属性应用到对应的报表格式中. 常用属性如 ...
- Google谷歌推出goo.gl缩短网址服务 - Blog透视镜
Blog部落格文章的网址,例如本篇文章:http://blog.openyu.org/2014/01/google-goo.gl.html,通常都很冗长,分享到社群网站上,容易使得讯息内容过多,同时也 ...
- linux xargs 使用
xargs是一条Unix和类Unix操作系统的常用命令.它的作用是将参数列表转换成小块分段传递给其他命令,以避免参数列表过长的问题[1]. 例如,下面的命令: rm `find /path -type ...
- [置顶] Android学习系列-Android中解析xml(7)
Android学习系列-Android中解析xml(7) 一,概述 1,一个是DOM,它是生成一个树,有了树以后你搜索.查找都可以做. 2,另一种是基于流的,就是解析器从头到尾解析一遍xml文件. ...
- Shell函数返回值、删除函数、在终端调用函数
Shell 也支持函数.Shell 函数必须先定义后使用. Shell 函数的定义格式如下: function_name () { list of commands [ return value ] ...
- Sum Root to Leaf Numbers 解答
Question Given a binary tree containing digits from 0-9 only, each root-to-leaf path could represent ...