【Flume】安装与测试
1.下载安装包http://archive.apache.org/dist/flume/
2.解压命令tar -zxvf 压缩包 -C 路径
3.配置环境变量
export FLUME_HOME=/opt/programs/apache-flume-1.6.0-bin
export PATH=$PATH:$FLUME_HOME/bin
source /etc/profile
4.在conf/目录下,修改flume-env.sh
cp flume-env.ps1.template flume-env.sh
vi flume-env.sh
在最下面添加java_home就行了
export JAVA_HOME=/usr/java/jdk1.8.0_25
注意:
如果你的hadoop集群是HA模式,需要把core-site.xml、hdfs-site.xml复制到flume的conf/文件夹下
5.在conf/目录下,新建测试配置文件example.conf
http://flume.apache.org/FlumeUserGuide.html#avro-sink
vi example.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger=INFO,console
8.安装telnet
yum -y install telnet
9.测试连接
telnet localhost 44444
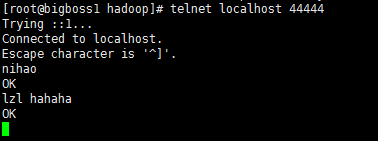

10.单节点配置ok了,复制到其他节点。
测试:用Flume收集文件夹中的数据
1.创建一个即将要被“监视”的文件夹
[root@bigboss1 opt]# mkdir flume-dir
[root@bigboss1 opt]# ll
total 16
-rw-r--r--. 1 root root 23 Oct 15 15:56 exam.csv
drwxr-xr-x. 2 root root 6 Oct 22 18:49 flume-dir
drwxr-xr-x. 8 root root 4096 Oct 22 11:34 programs
drwxr-xr-x. 2 root root 4096 Oct 22 11:33 targz
drwxr-xr-x. 4 root root 32 Sep 27 09:43 tasks
drwxr-xr-x. 2 root root 4096 Sep 28 08:40 txts
[root@bigboss1 opt]# cd flume-dir/
[root@bigboss1 flume-dir]# pwd
/opt/flume-dir
2.在flume的conf/下创建文件example-dir.conf文件
a1.channels = ch1
a1.sources = src1
a1.sinks = k1
a1.sources.src1.type = spooldir
a1.sources.src1.channels = ch1
a1.sources.src1.spoolDir = /opt/flume-dir
a1.sources.src1.fileHeader = true
a1.sources.src1.ignorePattern = ([^ ]*\.tmp)
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = ch1
a1.sinks.k1.hdfs.path = hdfs://bigboss1:9000/test/flume-events1/%y-%m-%d/%H
a1.sinks.k1.hdfs.filePrefix = events1-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 60
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.rollInterval = 600
a1.sinks.k1.hdfs.rollSize = 134217700
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.minBlockReplicas = 1
a1.channels.ch1.type = memory
a1.channels.ch1.capacity = 1000
a1.channels.ch1.transactionCapacity = 100
a1.sources.src1.channels = ch1
3.运行flume agent
flume-ng agent --conf conf --name a1 --conf-file example-dir.conf &
提示:& 表示将任务放在后台
4.在被‘监视’的文件夹下创建文件
[root@bigboss1 flume-dir]# vi mytxt.txt
You have new mail in /var/spool/mail/root
[root@bigboss1 flume-dir]# vi mytmp.tmp
[root@bigboss1 flume-dir]# ll
total 8
-rw-r--r--. 1 root root 14 Oct 22 19:11 mytmp.tmp
-rw-r--r--. 1 root root 20 Oct 22 19:11 mytxt.txt.COMPLETED
我在mytxt.txt里写了
i am ok
are you ok?
在mytmp.tmp里写了
hello flume!
.tmp文件会被ignore,因为a1.sources.src1.ignorePattern = ([^ ]*\.tmp)
此时flume会有变化
19/10/22 19:11:21 INFO avro.ReliableSpoolingFileEventReader: Preparing to move file /opt/flume-dir/mytxt.txt to /opt/flume-dir/mytxt.txt.COMPLETED
19/10/22 19:11:22 INFO hdfs.HDFSDataStream: Serializer = TEXT, UseRawLocalFileSystem = false
19/10/22 19:11:22 INFO hdfs.BucketWriter: Creating hdfs://bigboss1:9000/test/flume-events1/19-10-22/19/events1-.1571742682004.tmp
19/10/22 19:21:24 INFO hdfs.BucketWriter: Closing hdfs://bigboss1:9000/test/flume-events1/19-10-22/19/events1-.1571742682004.tmp
5.在hdfs查看文件
[root@bigboss1 flume-dir]# hdfs dfs -cat /test/flume-events1/19-10-22/19/events1-.1571742682004.tmp
i am ok
are you ok?
[root@bigboss1 flume-dir]#
嗯,结束啦
【Flume】安装与测试的更多相关文章
- flume入门之一:flume 安装及测试
http://flume.apache.org/ flume下载:http://mirror.bit.edu.cn/apache/flume/1.7.0/apache-flume-1.7.0-bin. ...
- 大数据笔记(十九)——数据采集引擎Sqoop和Flume安装测试详解
一.Sqoop数据采集引擎 采集关系型数据库中的数据 用在离线计算的应用中 强调:批量 (1)数据交换引擎: RDBMS <---> Sqoop <---> HDFS.HBas ...
- sqoop、flume 安装
sqoop安装步骤 1.上传解压tar包 tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz 2.修改配置文件 进入 sqoop/conf/ c ...
- Flume简介与使用(一)——Flume安装与配置
Flume简介与使用(一)——Flume安装与配置 Flume简介 Flume是一个分布式的.可靠的.实用的服务——从不同的数据源高效的采集.整合.移动海量数据. 分布式:可以多台机器同时运行采集数据 ...
- flume安装及入门实例
1. 如何安装? 1)将下载的flume包,解压到/home/hadoop目录中 2)修改 flume-env.sh 配置文件,主要是JAVA_HOME变量设置 root@m1:/home/hadoo ...
- Apache Flume 安装文档、日志收集
简介: 官网 http://flume.apache.org 文档 https://flume.apache.org/FlumeUserGuide.html hadoop 生态系统中,flume 的职 ...
- CentOS6安装各种大数据软件 第七章:Flume安装与配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- Flume安装部署
Flume安装部署 Flume的安装(非常简单) 上传安装包到数据源所在节点上,实际上不是数据源节点也是可以的,只要运行Flume的这台机器与数据源节点的这台机器能够通过某种协议进行通信即可. 然后解 ...
- 大数据学习day35----flume01-------1 agent(关于agent的一些问题),2 event,3 有关agent和event的一些问题,4 transaction(事务控制机制),5 flume安装 6.Flume入门案例
具体见文档,以下只是简单笔记(内容不全) 1.agent Flume中最核心的角色是agent,flume采集系统就是由一个个agent连接起来所形成的一个或简单或复杂的数据传输通道.对于每一个Age ...
- my SQL下载安装,环境配置,以及密码忘记的解决,以及navicat for mysql下载,安装,测试连接
一.下载 在百度上搜索"mysql-5.6.24-winx64下载" 二.安装 选择安装路径,我的路径“C:\Soft\mysql-5.6.24-winx64” 三.环境配置 计算 ...
随机推荐
- 面试官:你说你懂动态代理,那你知道为什么JDK中的代理类都要继承Proxy吗?
之前我已经写过了关于动态代理的两篇文章,本来以为这块应该没啥问题,没想到今天又被难住了- 太难了!!! 之前文章的链接: 动态代理学习(一)自己动手模拟JDK动态代理. 动态代理学习(二)JDK动态代 ...
- Spring Cloud学习 之 Spring Cloud Hystrix(断路器原理)
断路器定义: public interface HystrixCircuitBreaker { // 每个Hystrix都通过它判断是否被执行 public boolean allowRequest( ...
- redis 集群安装
redis集群安装 1.下载redis源码 2.解压并进入解压后的文件夹redis内 3.make,生成一系列的文件(mkreleasehdr.sh, redis-benchmark, redis-c ...
- [USACO07DEC]Best Cow Line G 字符串hash || 后缀数组
[USACO07DEC]Best Cow Line G [USACO07DEC]Best Cow Line G 小声哔哔:字符串hash牛逼 题意 给出一个字符串,每次可以从字符串的首尾取出一个字符, ...
- Mysql 常用函数(1)- 常用函数汇总
Mysql常用函数的汇总,可看下面系列文章 Mysql常用函数有哪几类 数值型函数 字符串型函数 日期时间函数 聚合函数 流程控制函数 数值型函数 函数名称 作用 ABS 求绝对值 SQRT 求二次方 ...
- Mysql 常用函数(13)- right 函数
Mysql常用函数的汇总,可看下面系列文章 https://www.cnblogs.com/poloyy/category/1765164.html right 的作用 返回字符串 str 中最右边的 ...
- mysql连表查空,查询第二张表中没有第一张表中的数据
select consumer_id,user_name,mobile,invite_code from csr_consumer where invite_count<(select coun ...
- angular前端框架简单小案例
一.angular表达式 <head> <meta charset="UTF-8"> <title>Title</title> &l ...
- JavaScript(对象的创建模式)
JavaScript和其他语言略有不同,在JavaScript中,引用数据类型都是对象(包括函数).不过,在JavaScript中并没有“类”的概念,这决定了在JavaScript中不能直接来定义“类 ...
- Java开发架构篇:领域驱动设计架构基于SpringCloud搭建微服务
作者:小傅哥 博客:https://bugstack.cn 沉淀.分享.成长,让自己和他人都能有所收获! 一.前言介绍 微服务不是泥球小单体,而是具备更加清晰职责边界的完整一体的业务功能服务.领域驱动 ...