基于flink和drools的实时日志处理
1、背景
日志系统接入的日志种类多、格式复杂多样,主流的有以下几种日志:
- filebeat采集到的文本日志,格式多样
- winbeat采集到的操作系统日志
- 设备上报到logstash的syslog日志
- 接入到kafka的业务日志
以上通过各种渠道接入的日志,存在2个主要的问题:
- 格式不统一、不规范、标准化不够
- 如何从各类日志中提取出用户关心的指标,挖掘更多的业务价值
为了解决上面2个问题,我们基于flink和drools规则引擎做了实时的日志处理服务。
2、系统架构
架构比较简单,架构图如下:
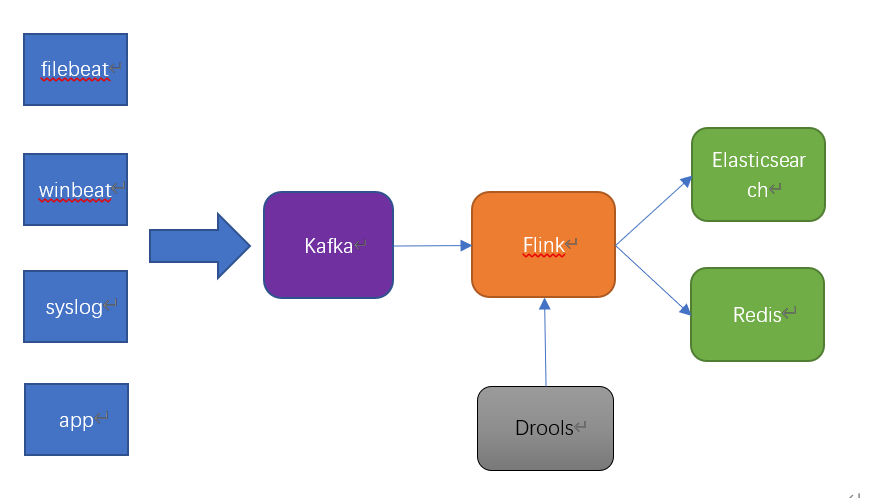
各类日志都是通过kafka汇总,做日志中转。
flink消费kafka的数据,同时通过API调用拉取drools规则引擎,对日志做解析处理后,将解析后的数据存储到Elasticsearch中,用于日志的搜索和分析等业务。
为了监控日志解析的实时状态,flink会将日志处理的统计数据,如每分钟处理的日志量,每种日志从各个机器IP来的日志量写到Redis中,用于监控统计。
3、模块介绍
系统项目命名为eagle。
eagle-api:基于springboot,作为drools规则引擎的写入和读取API服务。
eagle-common:通用类模块。
eagle-log:基于flink的日志处理服务。
重点讲一下eagle-log:
对接kafka、ES和Redis
对接kafka和ES都比较简单,用的官方的connector(flink-connector-kafka-0.10和flink-connector-elasticsearch6),详见代码。
对接Redis,最开始用的是org.apache.bahir提供的redis connector,后来发现灵活度不够,就使用了Jedis。
在将统计数据写入redis的时候,最开始用的keyby分组后缓存了分组数据,在sink中做统计处理后写入,参考代码如下:
String name = "redis-agg-log";
DataStream<Tuple2<String, List<LogEntry>>> keyedStream = dataSource.keyBy((KeySelector<LogEntry, String>) log -> log.getIndex())
.timeWindow(Time.seconds(windowTime)).trigger(new CountTriggerWithTimeout<>(windowCount, TimeCharacteristic.ProcessingTime))
.process(new ProcessWindowFunction<LogEntry, Tuple2<String, List<LogEntry>>, String, TimeWindow>() {
@Override
public void process(String s, Context context, Iterable<LogEntry> iterable, Collector<Tuple2<String, List<LogEntry>>> collector) {
ArrayList<LogEntry> logs = Lists.newArrayList(iterable);
if (logs.size() > 0) {
collector.collect(new Tuple2(s, logs));
}
}
}).setParallelism(redisSinkParallelism).name(name).uid(name);
后来发现这样做对内存消耗比较大,其实不需要缓存整个分组的原始数据,只需要一个统计数据就OK了,优化后:
String name = "redis-agg-log";
DataStream<LogStatWindowResult> keyedStream = dataSource.keyBy((KeySelector<LogEntry, String>) log -> log.getIndex())
.timeWindow(Time.seconds(windowTime))
.trigger(new CountTriggerWithTimeout<>(windowCount, TimeCharacteristic.ProcessingTime))
.aggregate(new LogStatAggregateFunction(), new LogStatWindowFunction())
.setParallelism(redisSinkParallelism).name(name).uid(name);
这里使用了flink的聚合函数和Accumulator,通过flink的agg操作做统计,减轻了内存消耗的压力。
使用broadcast广播drools规则引擎
1、drools规则流通过broadcast map state广播出去。
2、kafka的数据流connect规则流处理日志。
//广播规则流
env.addSource(new RuleSourceFunction(ruleUrl)).name(ruleName).uid(ruleName).setParallelism(1)
.broadcast(ruleStateDescriptor); //kafka数据流
FlinkKafkaConsumer010<LogEntry> source = new FlinkKafkaConsumer010<>(kafkaTopic, new LogSchema(), properties);
env.addSource(source).name(kafkaTopic).uid(kafkaTopic).setParallelism(kafkaParallelism); //数据流connect规则流处理日志
BroadcastConnectedStream<LogEntry, RuleBase> connectedStreams = dataSource.connect(ruleSource);
connectedStreams.process(new LogProcessFunction(ruleStateDescriptor, ruleBase)).setParallelism(processParallelism).name(name).uid(name);
具体细节参考开源代码。
4、小结
本系统提供了一个基于flink的实时数据处理参考,对接了kafka、redis和elasticsearch,通过可配置的drools规则引擎,将数据处理逻辑配置化和动态化。
对于处理后的数据,也可以对接到其他sink,为其他各类业务平台提供数据的解析、清洗和标准化服务。
项目地址:
https://github.com/luxiaoxun/eagle
基于flink和drools的实时日志处理的更多相关文章
- Lyft 基于 Flink 的大规模准实时数据分析平台(附FFA大会视频)
摘要:如何基于 Flink 搭建大规模准实时数据分析平台?在 Flink Forward Asia 2019 上,来自 Lyft 公司实时数据平台的徐赢博士和计算数据平台的高立博士分享了 Lyft 基 ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
- 趣头条基于 Flink 的实时平台建设实践
本文由趣头条实时平台负责人席建刚分享趣头条实时平台的建设,整理者叶里君.文章将从平台的架构.Flink 现状,Flink 应用以及未来计划四部分分享. 一.平台架构 1.Flink 应用时间线 首先是 ...
- 轻装上阵Flink--在IDEA上开发基于Flink的实时数据流程序
前言 本文介绍如何在IDEA上快速开发基于Flink框架的DataStream程序.先直接上手! 环境清单 案例是在win7运行.安装VirtualBox,在VirtualBox上安装Centos操作 ...
- OPPO数据中台之基石:基于Flink SQL构建实数据仓库
小结: 1. OPPO数据中台之基石:基于Flink SQL构建实数据仓库 https://mp.weixin.qq.com/s/JsoMgIW6bKEFDGvq_KI6hg 作者 | 张俊编辑 | ...
- 基于Flink构建全场景实时数仓
目录: 一. 实时计算初期 二. 实时数仓建设 三. Lambda架构的实时数仓 四. Kappa架构的实时数仓 五. 流批结合的实时数仓 实时计算初期 虽然实时计算在最近几年才火起来,但是在早期也有 ...
- 腾讯新闻基于 Flink PipeLine 模式的实践
摘要 :随着社会消费模式以及经济形态的发展变化,将催生新的商业模式.腾讯新闻作为一款集游戏.教育.电商等一体的新闻资讯平台.服务亿万用户,业务应用多.数据量大.加之业务增长.场景更加复杂,业务对实时 ...
- 字节跳动流式数据集成基于Flink Checkpoint两阶段提交的实践和优化
背景 字节跳动开发套件数据集成团队(DTS ,Data Transmission Service)在字节跳动内基于 Flink 实现了流批一体的数据集成服务.其中一个典型场景是 Kafka/ByteM ...
- 【转】ELK(ElasticSearch, Logstash, Kibana)搭建实时日志分析平台
[转自]https://my.oschina.net/itblog/blog/547250 摘要: 前段时间研究的Log4j+Kafka中,有人建议把Kafka收集到的日志存放于ES(ElasticS ...
随机推荐
- jchdl - GSL值的传播
https://mp.weixin.qq.com/s/jgMljoca-Cwe9x0NaTLzZg GSL的拓扑模型是线和节点连接的模型,值的传播,即是值在线和节点之间传播和转化的过程. 值的 ...
- jchdl - 门和开关层(GSL)
https://mp.weixin.qq.com/s/dcBfMLOuaFtrk6i149vIVQ 第一部分 静态建模:拓扑模型 GSL层拓扑建模相对简单,由线和节点组成: 线连接各个节点: ...
- Java实现 LeetCode 374 猜数字大小 II
375. 猜数字大小 II 我们正在玩一个猜数游戏,游戏规则如下: 我从 1 到 n 之间选择一个数字,你来猜我选了哪个数字. 每次你猜错了,我都会告诉你,我选的数字比你的大了或者小了. 然而,当你猜 ...
- Java实现 蓝桥杯VIP 算法训练 新生舞会
问题描述 新生舞会开始了.n名新生每人有三个属性:姓名.学号.性别.其中,姓名用长度不超过20的仅由大小写字母构成的字符串表示,学号用长度不超过10的仅由数字构成的字符串表示,性别用一个大写字符'F' ...
- java实现显示为树形
** 显示为树形** 树形结构应用十分广泛. 下面这段代码根据用户添加的数据,在内存中构建一个逻辑上等价的树形结构. 通过ShowTree() 可以把它显示为控制中的样子. 其中: a.add('a' ...
- java实现第四届蓝桥杯空白格式化
空白格式化 本次大赛采用了全自动机器测评系统. 如果你的答案与标准答案相差了一个空格,很可能无法得分,所以要加倍谨慎! 但也不必过于惊慌.因为在有些情况下,测评系统会把你的答案进行"空白格式 ...
- 【工作Vlog】Jmeter响应结果乱码解决方案
资料:https://blog.51cto.com/ydhome/1864340 方法一:使用后置控制器"Beanshell PostProcessor"(动态修改,灵活) 添加后 ...
- SQL手工注入绕过过滤
1.考虑闭合:单引号 --> %27 空格-->%20 井号--> %23 : 构造闭合函数 %27teacher%23 2.判断过滤内容:union --> uniu ...
- 还在用SimpleDateFormat格式化时间?小心经理锤你
还在用SimpleDateFormat格式化时间?小心经理锤你 场景 本来开开心心的周末时光,线上突然就疯狂报错,以为程序炸了,截停日志,发现是就是类似下述一段错误 java.lang.NumberF ...
- 高效开发(James)
1.对自己的要求 定位自己Level,清晰自己的目标. 学一个点,明确自己通过学习,需要达到的程度 怎么学一门技术 比如: Spring Cloud 它为什么出现? 它解决了什么问题? 它是怎么解决的 ...