实战:IDEA运行速度调优
序言
可能大家觉得系统调优一般都是针对服务端应用而言的,普通Java开发人员很少有机会实践。今天就通用一个Java开发人员日常工作中经常使用的开发工具开做一次调优实战。
我在日常工作中的主要IDE工具是IntelliJ IDEA,由于安装的插件较多,项目代码也比很多,所以运行速度不是特别令人满意,所以决定对其进行调优。
IDEA的运行平台是64位Windows10系统,虚拟机为HotSpot 1.8 b64。硬件为Intel i7-10510U,8GB物理内存。
初始JVM参数配置如下:
-Xmx512m
-XX:ReservedCodeCacheSize=240m
-XX:SoftRefLRUPolicyMSPerMB=80
-ea
-Dsun.io.useCanonCaches=false
-Djava.net.preferIPv4Stack=true
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow
为了方便与调优后的结果做对比,在开始前先做一组初始数据测试。
由于无法得知IDEA启动的准确耗时,我们通过VisualGC收集到的信息,总结初始配置下的测试结果:
最后一次启动的数据样本中,垃圾收集总耗时3.102秒,其中:
- FULL GC被触发了6次,共耗时1.109秒。
- Minor GC被触发了89次,共耗时1.933秒。
- 加载类41148个,耗时28.908秒。
- 虚拟机的512MB堆内存被分配为50MB的新生代(40MB的Eden区和两个5MB的Survivor区)和462MB的老年代。
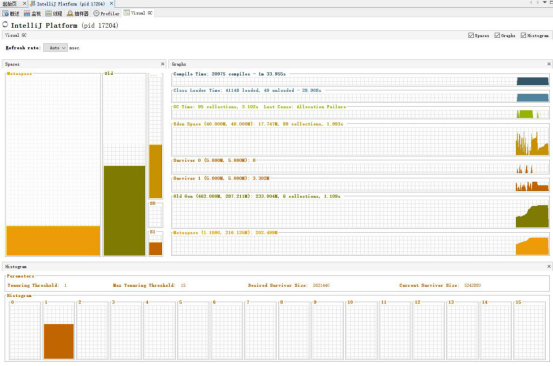
图:VisualVM监控
1、编译时间和类加载优化
通过测试数据可以看到,加载类和编译的时间非常耗时,而在其中字节码校验耗时占较大的比例。IDEA作为一款广为使用的成熟产品,它的编译代码我们可以认为是安全可靠的,不需要在加载过程中再进行字节码验证,因此可以通过-Xverify:none参数禁止掉字节码校验过程。

图:类的生命周期
在加入这个参数后,类的加载速度得到了一定的提升,加载时间缩减到19秒左右。

2、调整内存设置控制垃圾收集频率
下面我们要对“GC时间”进行调整优化,“GC时间”是最为重要的一块,这不单单是因为它消耗的时间较长,而是因为垃圾回收是一个稳定而持续的过程。在当前的测试用例中,加载类和即使编译的时间所占比例看上去比较高,但是在绝大多数的应用中,不可能出现持续的类加载和卸载过程。程序在运行了一段时间后,随着热点方法被不断的编译,新的热点方法数量也会下降,这会让类加载和即时编译所占的时间比例随着运行时间的增加而逐渐下降。但是垃圾回收却是随着程序运行而持续运作的,所以它才是对性能影响最重要的部分。
从测试的样本中来看,在IDEA启动过程中,共发生了6次FULL GC和89次Minor GC,一共95次GC造成了约3秒的停顿。
首先来分析新生代的Minor GC,尽管垃圾收集时间只有不到2秒,但是发生了89次之多。由于每次垃圾回收都需要用户线程跑到最近的安全点然后挂起来等待垃圾回收,频繁的垃圾收集必然会导致很多没有必要的线程挂起和恢复动作。
新生代垃圾收集频繁很明显是由于虚拟机分配的新生代空间太小导致的,Eden区加上一个Survivor区才45MB。所以我们通过-Xmn参数指定新生代大小为128MB。
再来看那6次FULL GC,虽然触发次数较少,但是平均每次的耗时要比较于Minor GC要高的多,所以降低垃圾收集的停顿时间的主要目标就是要降低FULL GC时间。我们从GC日志中分析得到FULL GC的原因,从GC日志中截取FULL GC部分日志。
[Full GC (Metadata GC Threshold) 2020-05-23T14:55:15.403+0800: 4.363: [Tenured: 56560K->54011K(77824K), 0.0691307 secs] 71164K->54011K(123904K), [Metaspace: 34482K->34482K(1081344K)], 0.0692415 secs] [Times: user=0.06 sys=0.00, real=0.07 secs] [Full GC (Metadata GC Threshold) 2020-05-23T14:55:15.403+0800: 4.363: [Tenured: 56560K->54011K(77824K), 0.0691307 secs] 71164K->54011K(123904K), [Metaspace: 34482K->34482K(1081344K)], 0.0692415 secs] [Times: user=0.06 sys=0.00, real=0.07 secs] [Full GC (Metadata GC Threshold) 2020-05-23T14:55:17.319+0800: 6.279: [Tenured: 67919K->65602K(90020K), 0.1222525 secs] 78376K->65602K(136100K), [Metaspace: 55927K->55927K(1099776K)], 0.1224057 secs] [Times: user=0.13 sys=0.00, real=0.12 secs] [Full GC (Metadata GC Threshold) 2020-05-23T14:55:19.520+0800: 8.480: [Tenured: 81857K->76282K(109340K), 0.1617177 secs] 105366K->76282K(155420K), [Metaspace: 91958K->91958K(1132544K)], 0.1618629 secs] [Times: user=0.19 sys=0.00, real=0.16 secs] [GC (Allocation Failure) 2020-05-23T14:55:29.399+0800: 18.360: [DefNew: 46080K->3039K(46080K), 0.0338515 secs]2020-05-23T14:55:29.433+0800: 18.394: [Tenured: 129641K->112262K(129828K), 0.3193513 secs] 170759K->112262K(175908K), [Metaspace: 147845K->147845K(1183744K)], 0.3535963 secs] [Times: user=0.36 sys=0.00, real=0.35 secs] [GC (Allocation Failure) 2020-05-23T14:55:40.032+0800: 28.992: [DefNew: 46080K->5120K(46080K), 0.0528825 secs]2020-05-23T14:55:40.085+0800: 29.044: [Tenured: 198033K->176461K(198052K), 0.4157306 secs] 231627K->176461K(244132K), [Metaspace: 194691K->194691K(1224704K)], 0.4690424 secs] [Times: user=0.48 sys=0.00, real=0.47 secs]
日志中加粗的部分代表着老年代的容量,几乎每一次FULL GC的原因都是老年代空间耗尽,每一次FULL GC都伴随着老年代空间的扩容:77824K → 90020K → 109340K → 129828K → 198052K。
日志中还显示有些时候内存回收效果不理想,空间扩容成了获取可用内存的最主要手段,比如这一句:[Tenured: 81857K->76282K(109340K), 0.1617177 secs]
代表在老年代当前容量为109340KB,内存使用到81857K时发生了FULL GC,花费了0.3193513秒时间把内存使用降低到76282K,回收了5575KB的内存空间。但是这次垃圾回收未达到效果,触发了空间扩容。扩容相比起回收过程可以看做基本不需要花费时间,所以这0.3193513秒时间几乎是浪费了。
由上述分析可以得到一个结论,FULL GC大多数是由于老年代容量扩展而导致的。那怎样避免扩容时的性能浪费呢,可以把-Xms参数设置为-Xmx参数值一样。将堆栈的空间固定下来,避免了运行时的自动扩展。
由于元空间(Metaspace)的扩展也占据了一部分的垃圾收集时间,我们可以通过设置一个元空间初始值来避免掉一部分扩展。(由于元空间的默认最大值是不受限制的,即只受限于本地内存大小,故只调整初始空间大小)
注:截取的GC日志,显示元空间的扩展也消耗了部分GC时间。
[Metaspace: 55927K->55927K(1099776K)], 0.1224057 secs]
[Metaspace: 91958K->91958K(1132544K)], 0.1618629 secs]
根据以上的分析,优化方案如下:
- 新生代空间提升到128MB(-Xmn128m)
- Java堆容量固定为512MB(-Xms512m、-Xmx512m)
- 元空间容量初始值设置为(-XX:MetaspaceSize=250m)
调整后的JVM配置
-Xms512m
-Xmx512m
-Xmn128m
-XX:MetaspaceSize=250m
-Xverify:none
在这个配置下再次测试,垃圾收集的次数已经大幅降低,只发生了34次Minor GC和1次FULL GC,总耗时1.823秒。
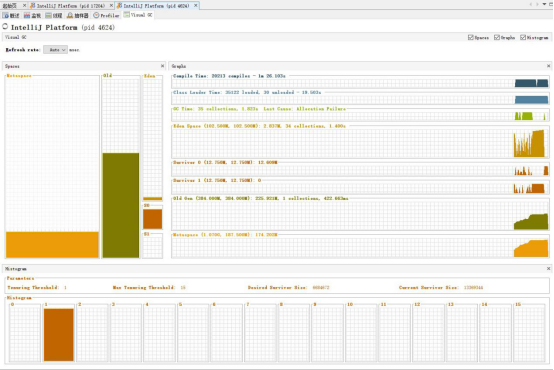
图:调整后的JVM运行数据
从结果看,优化效果很明显,但是有一点疑问,从Old Gen的曲线上来看,老年代的空间直接固定在384MB,而内存使用量还不足以触发FULL GC。那一次FULL GC是怎么来的呢?查看GC日志来查明原因。
2020-05-23T16:02:56.546+0800: 21.430: [Full GC (System.gc()) 2020-05-23T16:02:56.546+0800: 21.430: [Tenured: 160328K->152291K(393216K), 0.4226741 secs] 221862K->152291K(511232K), [Metaspace: 143107K->143107K(1181696K)], 0.4228607 secs] [Times: user=0.42 sys=0.00, real=0.42 secs]
原来是代码中显示的调用了System.gc()触发了垃圾收集,在内存设置调整后,这种显式的垃圾收集不符合我们的期望。在JVM参数中加入-XX:DisableExplicitGC屏蔽掉System.gc()。
3、选择收集器降低延迟
通过查看启动期间的CPU使用情况,我们可以看到CPU的平均使用率并不高,垃圾收集的处理器使用率就更低了,几乎和横坐标紧贴在一起。这说明处理器资源还很富足。
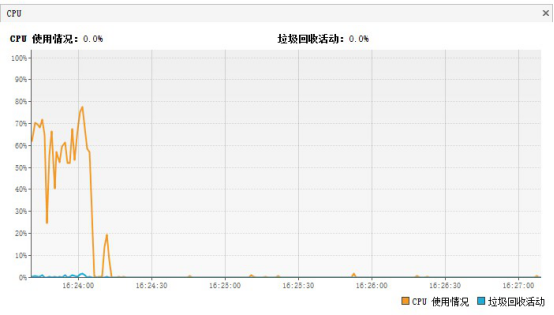
Java虚拟机提供了多种垃圾收集器的组合,很容易想到CMS是最符合当前场景的选择。
在JVM配置中加入这两个参数:
-XX:+UseParNewGC、-XX:+UseConcMarkSweepGC;
要求虚拟机在新生代和老年代分别使用ParNew和CMS收集器来进行垃圾回收。

图:指定ParNew和CMS收集器后的GC数据
再次测试后,新生代停顿553毫秒,老年代停顿96毫秒,总耗时降低为649毫秒。相比较于调整垃圾收集器前快了将近三倍之多。
当然,由于CMS的停顿时间只是整个收集过程中的一小部分,大部分收集行为都是和用户线程并发执行的。所以这里并不是真的将收集时间降低到649毫秒了。
到此为止,对于IDEA的JVM调优就结束了,我们终于可以愉快的使用IDEA进行工作了!最终的配置清单如下所示。
# custom IntelliJ IDEA VM options
-Xms512m
-Xmx512m
-Xmn128m
-XX:MetaspaceSize=250m
-Xverify:none
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=85
-XX:+DisableExplicitGC-XX:ReservedCodeCacheSize=240m
-XX:SoftRefLRUPolicyMSPerMB=80
-ea
-Dsun.io.useCanonCaches=false
-Djava.net.preferIPv4Stack=true
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow
链接: 文章首发地址
实战:IDEA运行速度调优的更多相关文章
- 素小暖讲JVM:Eclipse运行速度调优
本系列是用来记录<深入理解Java虚拟机>这本书的读书笔记.方便自己查看,也方便大家查阅. 欲速则不达,欲达则欲速! 这两天看了JVM的内存优化,决定尝试一下,对Eclipse进行内存调优 ...
- Netty实战之性能调优与设计模式
设计模式在Netty 中的应用(回顾): 单例模式要点回顾: 一个类在任何情况下只有一个对象,并提供一个全局访问点. 可延迟创建. 避免线程安全问题. 在我们利用netty自带的容器来管理客户端链接的 ...
- 《深入理解Java虚拟机》-----第5章 jvm调优案例分析与实战
案例分析 高性能硬件上的程序部署策略 例 如 ,一个15万PV/天左右的在线文档类型网站最近更换了硬件系统,新的硬件为4个CPU.16GB物理内存,操作系统为64位CentOS 5.4 , Resin ...
- 【JVM.4】调优案例分析与实战
之前已经介绍过处理Java虚拟机内存问题的知识与工具,在处理实际项目的问题时,除了知识与工具外,经验同样是一个很重要的因素.本章会介绍一些具有代表性的案例. 本章的内容推荐还是原文全篇看完的好,实在不 ...
- Spark Shuffle调优原理和最佳实践
对性能消耗的原理详解 在分布式系统中,数据分布在不同的节点上,每一个节点计算一部份数据,如果不对各个节点上独立的部份进行汇聚的话,我们计算不到最终的结果.我们需要利用分布式来发挥Spark本身并行计算 ...
- Linux操作系统性能调优的方法
http://www.cnblogs.com/L-H-R-X-hehe/p/3963442.html Linux是一套免费使用和自由传播的类Unix操作系统,Linux不同的发行版本和不同的内核对各项 ...
- Java性能调优攻略全分享,5步搞定!(附超全技能图谱)
对于很多研发人员来说,Java 性能调优都是很头疼的问题,为什么这么说?如今,一个简单的系统就囊括了应用程序.数据库.容器.操作系统.网络等技术,线上一旦出现性能问题,就可能要你协调多方面组件去进行优 ...
- JVM调优实战
JVM调优实战 文档修订记录 版本 日期 撰写人 审核人 批准人 变更摘要 & 修订位置 ...
- 《深入理解Java虚拟机》调优案例分析与实战
上节学习回顾 在上一节当中,主要学习了Sun JDK的一些命令行和可视化性能监控工具的具体使用,但性能分析的重点还是在解决问题的思路上面,没有好的思路,再好的工具也无补于事. 本节学习重点 在书本上本 ...
随机推荐
- Hadoop Yarn REST API未授权漏洞利用
Hadoop Yarn REST API未授权漏洞利用 Hadoop是一个由Apache基金会所开发的分布式系统基础架构,YARN是hadoop系统上的资源统一管理平台,其主要作用是实现集群资源的统一 ...
- 使用 git add -p 整理 patch
背景 当我们修改了代码准备提交时,本地的改动可能包含了不能提交的调试语句,还可能需要拆分成多个细粒度的 pactch. 本文将介绍如何使用 git add -p 来交互式选择代码片段,辅助整理出所需的 ...
- win服务器管理软件巧利用——如何让服务器管理事半功倍
那些服务器管理大牛估计看到这个标题会笑了,服务器怎么管理,靠自带的远程桌面肯定是远远不够的,要实现上千台服务器同时登陆,没有一个好程序管理,估计得三餐不食为其颠倒. 那么,有什么好的服务器推荐呢?站长 ...
- Rocket - regmapper - RegMapper
https://mp.weixin.qq.com/s/aXxgzWwh6unuztjgyVX0iQ 简单介绍RegMapper的实现. 1. 简单介绍 RegMapper使用指定的输入接口,为一组寄存 ...
- 获取<input type="radio">被选中的内容
背景: <input type="radio">,该标签表示的是单选按钮,这个类型相对于其他类型的获取,比较特殊,特此记录一下. 获取方式: 1. 使用选择器直接获取( ...
- display有哪些值?说明他们的作用?
inline(默认)— 内联 none — 隐藏 block — 显示.块级元素(单独占一行) inline-block — 行内块元素(不占整行) table — 表格显示 list-item — ...
- 使用锚点定位不改变url同时平滑的滑动到锚点位置,不会生硬的直接到锚点位置
使用锚点定位不改变url同时平滑的滑动到锚点位置,不会生硬的直接到锚点位置 对前端来说锚点是一个很好用的技术,它能快速定位到预先埋好的位置. 但是美中不足的是它会改变请求地址url,当用户使用了锚点的 ...
- Java中输入时IO包与Scanner的区别
最常用的一个IO控制台输入的 import java.io.BufferedReader; import java.io.IOException; import java.io.InputStream ...
- Java实现 蓝桥杯 算法训练 二进制数数
试题 算法训练 二进制数数 资源限制 时间限制:1.0s 内存限制:256.0MB 问题描述 给定L,R.统计[L,R]区间内的所有数在二进制下包含的"1"的个数之和. 如5的二进 ...
- ASP.NET Core Blazor WebAssembly实现一个简单的TODO List
基于blazor实现的一个简单的TODO List 最近看到一些大佬都开始关注blazor,我也想学习一下.做了一个小的demo,todolist,仅是一个小示例,参考此vue项目的实现http:// ...