【cs224w】Lecture 6 - 消息传递 及 节点分类
转自本人:https://blog.csdn.net/New2World/article/details/105410276
前面几课时讲的主要是图的性质、一些基本结构和针对结构的算法。而从现在开始就要涉及到具体的 learning 任务了。这一讲要解决的主要问题是:给定一个网络以及网络里一部分节点的标签,我们如何为其它节点分类。(semi-supervised)
我们使用的模型叫 collective classification model,其中有三种近似推断的方法,它们都是迭代型算法。
- relational classification
- iterative classification
- belief propagation
exact inferencevs.approximate inference
例如在一个图里每个节点都是离散的随机变量,而所有节点的类别的联合分布为 \(p\)。那么我们要得到某个节点的类别的分布就是求 \(p\) 在该节点上的边沿分布。而边沿分布需要累加其它所有节点,这个计算量爆炸,因此需要近似推断。
近似推断其实就是缩小传播范围的过程,与其考虑所有节点,我们只关心目标节点的邻接点。这里涉及到信息传递,就是类似 GNN 里的 aggregation,后面会说到。
Node Classification
给节点分类,我们的第一想法是节点间通过边的连接存在着相关性,那我们直接通过相关性对节点进行分类。关联性主要有三种
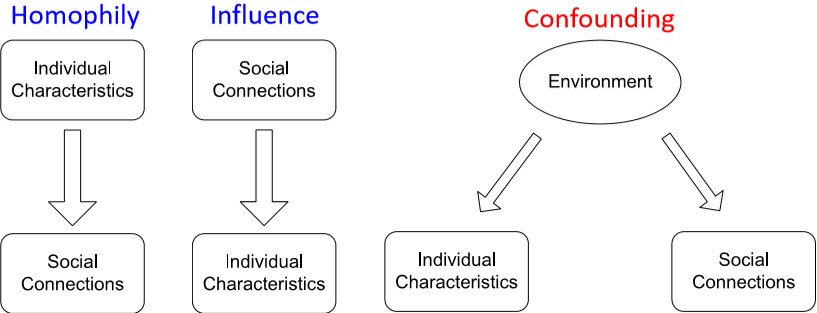
- homophily:“物以类聚,人以群分”,有相同性质的节点间可能存在更密切的联系
- influence:“近朱者赤,近墨者黑”,一个个体有可能会受其它个体的影响而具有某种性质
- confounding:大环境可能会对个体性质和个体间的联系产生影响
那么将这种关联性的特点应用在节点分类里,相似的节点间一般会有直接的联系,互相连接的点很有可能属于同一类别,这就是 guilt-by-association (关联推断)。而节点类别的判断可以基于节点的特征以及邻接节点的类别和特征。
由于做的是近似推断,所以这里需要做出马尔可夫假设,即节点 \(i\) 的类别 \(Y_i\) 只取决于它的邻接节点 \(N_i\)。因此有 \(P(Y_i|i)=P(Y_i|N_i)\)
Collective classification 大体分为三步:
- local classifier:就像一般的分类任务一样,只依赖节点自己的特征信息而不牵扯任何网络信息
- relational classifier:考虑邻接点的标签和特征
- collective inference:迭代地将 relational classifier 应用在每个节点上,相当于拓展了节点的“感知野”
Probabilistic Relational Classifier
基本思路很简单,每个节点类别的概率是其邻接节点的加权平均。
首先将有标签的点的类别初始化为标签,没有标签的点初始化为随机。然后按随机顺序进行邻接节点类别加权,直到整个网络收敛或达到最大迭代次数。但这样做有两个问题,第一不保证收敛;其次这样的模型并没有用到节点的特征。
\]
Iterative Classification
其实就是加上节点特征后的迭代过程。(1) Bootstrap phase,通过训练集训练两个分类器,一个针对节点本身的特征,一个针对节点和网络连接特征 (数据来自其它网络),比如 SVM 什么的。然后对每个节点提取特征并用第一个分类器来初始化标签。因为分类器并没有考虑网络信息,因此还需要 (2) Iteration phase 对网络中的关联进行迭代,即使用第二个分类器每个节点根据其邻接点更新特征和标签,直到收敛或达到最大迭代次数。然而这个方法依然无法保证收敛。
slide 里给了一个用 word-bag 作为特征的网页分类的例子,感兴趣可以去看看。
接下来是一个 iterative classification 的应用,对 fake reviewer/review 进行分类。它将 reviewer 和网页作为二分图处理,虽然也可以加上 reviewer 间的关系,但那样做会破坏这个方法的两个优点:(1) 迭代次数有上界;(2) 时间复杂度和边的条数成线性。
论文里给 reviewer,review 和网页都定义了 quality score。然后大致按照上面讲的方法对这些值进行迭代更新。
- reviewer: \(F(u)=\frac{\sum\limits_{(u,p)\in Out(u)}R(u,p)}{|Out(u)|}\)
- review: \(R(u,p)=\frac1{\gamma_1+\gamma_2}(\gamma_1F(u)+\gamma_2(1-\frac{|score(u,p)-G(p)|}2))\)
- 网页: \(G(p)=\frac{\sum\limits_{(u,p)\in In(p)}R(u,p)\cdot score(u,p)}{|In(p)|}\)
有学生问到一个问题:如果一个人对所有网页都给 good review,那他算不算 fake?
Michele 的回答是这样做只会让这个人的评分趋近 \(0.5\) 而不会像那种给好网页评负分的真正的 fake reviewer 那样得分趋近 \(0\)
另一个有意思的问题是,如果某个人口味独特,给某些奇怪的网站评了高分,会不会被认为是 fake?
我很好奇口味有多独特,奇怪的网页指什么。但实际上世界很大,网络规模也很大,有独特癖好的不止你一个,因此你不孤单。总有那么一群人给这些奇怪的网页评高分,相对来说也就不会被分为 fake。不过这个问题也得看实际情况。
Belief Propagation
信念传播是一个动态规划的过程,主要用于解决图模型中的条件概率问题。不过在看它到底是什么东西前我们先了解下信息传递是怎么回事。想象一群高度近视的人不戴眼镜在操场上排了个纵队,他们只能看到前面和后面一个人。这种情况下如何让他们知道自己在第几个?很简单,第一个人告诉第二个人“你前面有一个人(就是第一个人自己)”,第二个人告诉第三个人“你前面俩人”,依次类推所有人都知道自己第几了。同理,如果从最后一个人开始往前,那么就能知道队伍的总人数了(正数和倒数第几都有了)。这个道理用到网络里其实差不多,每个节点能知道自己的大概位置。但是一旦遇到环,这个方法就没完了……这个我们待会儿再说。该介绍信念传播的算法了:Loopy Belief Propagation
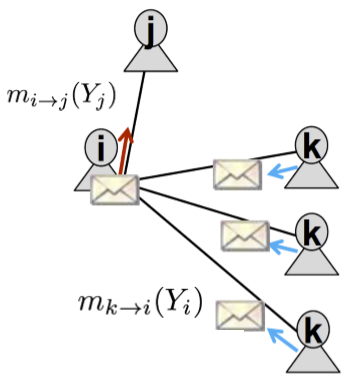
在上图的简单网络结构中,节点 \(i\) 发给 \(j\) 的信息包含了节点 \(k\) 发给 \(i\) 的信息。因此先做如下定义
- label-label potential matrix \(\psi(Y_i,Y_j)\):表示节点 \(i\) 是类别 \(Y_i\) 的条件下,其邻接节点 \(j\) 为类别 \(Y_j\) 的概率
- prior belief \(\phi_i(Y_i)\):表示节点 \(i\) 为类别 \(Y_i\) 的先验概率
- \(m_{i\rightarrow j}(Y_j)\):节点 \(i\) 在多大程度上认为其邻接节点 \(j\) 是类别 \(Y_j\) (不知道这里能不能算作是一个概率)
\]
这个式子应该很好理解:节点 \(i\) 为 \(Y_i\) 时,有个先验 \(\phi\),同时它会收到节点 \(k\) 的信息 \(m_{k\rightarrow i}(Y_i)\),然后根据类似转移矩阵的 \(\psi\) 得到节点 \(j\)。这里的 \(\alpha\) 类似于学习率。
老规矩,随机顺序迭代,直到收敛,然后就得到了节点 \(i\) 是类别 \(Y_i\) 的信念。
\]
好,信念传播的过程和模型介绍了,需要来解决环的问题了。在传播过程中,环的存在可能会导致信念的重复累加,但这样对结果不会造成太大影响,因为它无非就是让节点更加确信结果而已。其最主要的问题是可能会导致原本相关的信息被作为独立信息来处理,如下图中圈出的两个信息。这两条信息其实是同一条,但因为信念传播是局部算法,因此它会将这两条信息作为相互独立的两条信息来对待。那我们怎么解决呢?我没理解错的话 Michele 的意思是不用处理……因为这个例子很极端,而实际中环的影响很弱,比如有些环很~长,而大多数环存在至少一种弱相关性[1]。
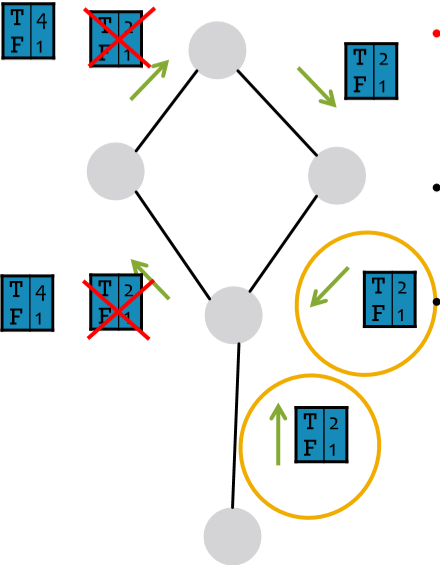
图里那两个
T4F1应该是T4F2
核心算法已经讲了,后面还举了个栗子,自己看 slide 吧。
这里的 weak correlation 不太明白是什么意思。弱相关能解环?还是说这里的 correlation 就是 link 的意思,然后 weak 代表传播的概率在这里很小? ↩︎
【cs224w】Lecture 6 - 消息传递 及 节点分类的更多相关文章
- 【图机器学习】cs224w Lecture 7 - 节点的表示
目录 Node Embedding Random Walk node2vec TransE Embedding Entire Graph Anonymous Walk Reference 转自本人:h ...
- 简述HTML DOM及其节点分类
在JavaScript中,document这个对象大家一定很熟悉,哪怕是刚刚开始学习的新人,也会很快接触到这个对象.而document对象不仅仅是一个普通的JavaScript内置对象,它还是一个巨大 ...
- 【图机器学习】cs224w Lecture 16 - 图神经网络的局限性
目录 Capturing Graph Structure Graph Isomorphism Network Vulnerability to Noise 转自本人:https://blog.csdn ...
- 【图机器学习】cs224w Lecture 8 & 9 - 图神经网络 及 深度生成模型
目录 Graph Neural Network Graph Convolutional Network GraphSAGE Graph Attention Network Tips Deep Gene ...
- 【图机器学习】cs224w Lecture 13 & 14 - 影响力最大化 & 爆发检测
目录 Influence Maximization Propagation Models Linear Threshold Model Independent Cascade Model Greedy ...
- 【图机器学习】cs224w Lecture 15 - 网络演变
目录 Macroscopic Forest Fire Model Microscopic Temporal Network Temporal PageRank Mesoscopic 转自本人:http ...
- GCN python 实现2:利用GCN进行节点分类
参考:https://www.baidu.com/link?url=5oU-O_YQV8DdSTtRkgzsQ_vuwjJHyUOxqeAKhq98ZA5XtvKW8PNQwXgSlr5GpESRqh ...
- 【图机器学习】cs224w Lecture 10 - PageRank
目录 PageRank Problems Personalized PageRank 转自本人:https://blog.csdn.net/New2World/article/details/1062 ...
- 【图机器学习】cs224w Lecture 11 & 12 - 网络传播
目录 Decision Based Model of Diffusion Large Cascades Extending the Model Probabilistic Spreading Mode ...
随机推荐
- angular的开始历程
开始写angular了,抑制不住的开心,比react差点开心,vue开始太虐 喜欢一个人要不要表个白?其实也没啥资格喜欢~!!考虑一段时间吧 9.29表白了,嗯,被拒绝的干脆利落 为他写了一首小诗歌, ...
- iview的render函数使用
render渲染函数详解 https://www.cnblogs.com/weichen913/p/9676210.html iview表格的render函数作用是自定义渲染当前列,权限高于key,所 ...
- Linux学习--4.用户和组的管理
用户和组的管理 前言 本篇文章主要讲Linux系统下用户和组的概念,还有添加用户和组,修改用户和组的基本操作,会涉及不少与之相关的配置文件与命令的介绍,几乎所有 正文 首先,简单提下概念,用户是操作系 ...
- Jira使用说明文档
1 建立项目 1.1 权限归属 Jira系统管理员 1.2 执行内容 建立项目.工作流分配调整.制定项目负责人及默认经办人 1.3 建立项目过程 登录使用Jira系统管理员 ...
- C语言程序设计(二) C数据类型
第二章 C数据类型 八进制整数由数字0开头,后跟0~7的数字序列组成. 十六进制整数由数字0加字母x(或X)开头,后跟0~9,a~f(或A~F)的数字序列组成. 整型常量: 默认的int型定义为有符号 ...
- (转)GNU风格ARM汇编语法指南(非常详细)4
原文地址:http://zqwt.012.blog.163.com/blog/static/12044684201011148226622/ 4.GNU汇编语言定义入口点 汇编程序的缺省入口是_sta ...
- StormDRPC流程解读
Storm 的编程模型是一个有向无环图,模型角度决定了 Storm 的 Spout 接收到外部系统的请求,将请求数据分发给下游的 bolt 进行处理后,spout 并不能得到 bolt 的处理结果并将 ...
- 第三届上海市大学生网络安全大赛 流量分析 WriteUp
题目链接: https://pan.baidu.com/s/1Utfq8W-NS4AfI0xG-HqSbA 提取码: 9wqs 解题思路: 打开流量包后,按照协议进行分类,发现了存在以下几种协议类型: ...
- 3000字编程入门--附带Java学习路线及视频
Title: 编程入门 GitHub: BenCoper Reference: 尚硅谷-2019 Study: 文字版+视频+实战(第一个自学的网站) Explain: 文末附带Java学习视频以及项 ...
- 使用new Image()可以针对单单请求,不要返回数据的情况
使用new Image()可以针对单单请求,不要返回数据的情况,比如我这里写了一个Demo,请求百度的Logo一个示例: <html> <head> </head> ...