【实战】基于OpenCV的水表字符识别(OCR)

1. USB摄像头取图
由于分辨率越高,处理的像素就越多,导致分析图像的时间变长,这里,我们设定摄像头的取图像素为(240,320):
cap = cv2.VideoCapture(0) # 根据电脑连接的情况填入摄像头序号
assert cap.isOpened()
# 以下设置显示屏的宽高
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 320)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 240)
cap.set(cv2.CAP_PROP_FOURCC, cv2.VideoWriter.fourcc('M', 'J', 'P', 'G'))
这里提几个常用的标准分辨率:
- VGA (Video Graphics Array): 640×480
- QVGA (QuarterVGA): 240×320
- QQVGA: 120×160
接下来可以捕获一帧数据看一下状态:
# %% 捕获一帧清晰的图像
def try_frame():
while True:
ret, im_frame = cap.read()
cv2.imshow("frame", im_frame) # 显示图像
# im_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 可选择转换为灰度图
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
return im_frame
im_frame = try_frame()
env.imshow(im_frame)

ps: 镜头角度会存在一定的歪斜,没有关系,我们后面会进行处理。
2. 图像预处理:获取屏幕ROI
利用屏幕的亮度,通过简单的阈值操作和轮廓操作,获取屏幕轮廓,然后将图像角度校正,最后获得正向的文字内容。
2.1. 分离提取屏幕区域
通过OTSU的阈值化操作,将图像处理为二值状态。这个很重要,因为如果直接使用彩图或灰度图,会由于外部光线的变化,导致后期字符匹配时整体灰度值与模板的差别而降低置信度,导致较大的误差。而二值图可以避免这个问题。
然后利用开运算(白底黑字,如果黑底白字则为闭运算),消除噪点。
im_latest = try_frame()
im_gray = mvlib.color.rgb2gray(image)
im_bin = mvlib.filters.threshold(im_gray, invert=False)
# im_erosion = mvlib.morphology.erosion(im_bin, (11, 11))
# im_dilation = mvlib.morphology.dilation(im_erosion, (5, 5))
im_opening = mvlib.morphology.opening(im_bin, (11, 11))
env.imshow(im_opening)

2.2. 计算屏幕区域的旋转角度
提取图像的最大轮廓,然后获取其包络矩形。
list_cnts = mvlib.contours.find_cnts(im_opening)
if len(list_cnts) != 1:
print(f"非唯一轮廓,请通过面积筛选过滤")
# assert 0
cnts_sorted = mvlib.contours.cnts_sort(list_cnts, mvlib.contours.cnt_area)
list_cnts = [cnts_sorted[0]]
box, results = mvlib.contours.approx_rect(list_cnts[0], True)
angle = results[2] # 此处的角度是向逆时针倾斜,记作:-4
if abs(angle) > 45:
angle = (angle + 45) % 90 - 45
print(angle, box)
上述过程输出:
1.432098388671875
[[282 173]
[ 29 167]
[ 32 41]
[285 47]]
2.3. 裁剪屏幕区域
至此可以丢弃im_opening以及im_bin的图像了。我们重新回到im_gray上进行操作(需要重新进行阈值化以获取文字的二值图)。
list_width = box[:,0]
list_height= box[:,1]
w_min, w_max = min(list_width), max(list_width)
h_min, h_max = min(list_height), max(list_height)
im_screen = im_gray[h_min:h_max, w_min:w_max]
env.imshow(im_screen)

2.4. 旋转图像至正向视角
im_screen_orthogonal = mvlib.transform.rotate(im_screen, angle, False)
# env.imshow(im_screen_orthogonal)
im_screen_core = im_screen_orthogonal[20:-20, 20:-20]
env.imshow(im_screen_core)

2.5. 提取文字图像
第二次执行阈值化操作,但这一次是在屏幕内部,排除了屏幕外复杂的背景后,可以很容易的获取到文字的内容。由于我们只关心数字,所以通过闭运算将细体字过滤掉。
im_core_bin = mvlib.filters.threshold(im_screen_core, invert=False)
im_closing = mvlib.morphology.closing(im_core_bin, (3,3))
env.imshow(im_closing)
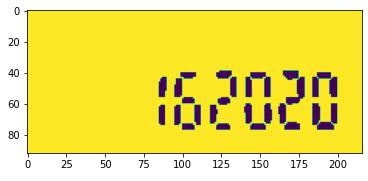
2.6. 封装上述过程
琐碎的预处理过程就告一段落了,我们可以将上述的内容封装成一个简单的函数:
def preprocess():
# 获取屏幕区域
im_latest = try_frame()
...
im_closing = mvlib.morphology.closing(im_core_bin, (3,3))
return im_closing
3. 字符分割,获取单个字符的图像
字符分割,一方面是制作模板的需要(当然,你也可以直接用画图工具裁剪出一张模板图像);另一方面是为了加速模板匹配的效率。当然,你完全可以在整张图像上利用 match_template() 查找模板,但如果进行多模板匹配,重复的扫描整张图像,效率就大打折扣了。
先提供完整的代码
char_width_min = 7
gap_height_max = 5
def segment_chars(im_core):
list_char_img = []
# 字符区域
raw_bkg = np.all(im_core, axis=0)
col_bkg = np.all(im_core, axis=1)
# 计算字高
ndarr_char_height = np.where(False == col_bkg)[0]
char_height_start = ndarr_char_height[0]
item_last = ndarr_char_height[0]
for item in ndarr_char_height:
if item - item_last > gap_height_max:
char_height_start = item
item_last = item
char_height_end = ndarr_char_height[-1] +1
print(f"字高【{char_height_end - char_height_start}】")
ndarr_chars_pos = np.where(False == raw_bkg)[0]
ndarr_chars_pos = np.append(ndarr_chars_pos,
im_core.shape[1] + char_width_min)
last_idx = ndarr_chars_pos[0]
curr_char_width = 1
for curr_idx in ndarr_chars_pos:
idx_diff = curr_idx - last_idx
# 这里应该限制最小宽度>=2,否则认为是一个粘连字
if idx_diff <= 2:
curr_char_width += idx_diff
else: # 新的字符
char_width_end = last_idx +1
char_width_start = char_width_end - curr_char_width
im_char_last = im_core[char_height_start:char_height_end,
char_width_start:char_width_end]
list_char_img.append(im_char_last)
curr_char_width = 0
last_idx = curr_idx
return list_char_img
按照行列,获取图像中的文字像素点集:
raw_bkg = np.all(im_core, axis=0)
col_bkg = np.all(im_core, axis=1)
由此,可以知道255(黑色)的区域从大约 39 到 75,那么 75 - 29 = 36 就是字高。
另外,图像中有可能存在噪点,去掉就是了(我这里只是简单粗暴的处理下,请见谅)。
行的处理同样。如果发现间隔,那么就可以分离字符。最后,输出每个字符的图像。
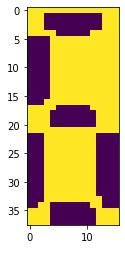
检验下效果:
list_char_imgs = segment_chars(im_core)
env.imshow(list_char_imgs[1])
4. 模板匹配:确定字符内容
利用模板匹配,实现字符识别的过程。这里不再细说OpenCV的 cv2.matchTemplate() 函数,只描述应用过程。
4.1. make_template
首先,有必要把字符先作为模板存储下来。
def make_tpls(list_tpl_imgs, dir_save, dict_tpl=None):
if not dict_tpl:
dict_tpl = {}
str_items = input("请输入模板上的文本内容,用于校对(例如215801): ")
assert len(str_items) == len(list_tpl_imgs)
for i, v in enumerate(str_items):
filename = v
if v in dict_tpl:
filename = v + "_" + str(random.random())
else:
dict_tpl[v] = list_tpl_imgs[i]
path_save = os.path.join(dir_save, filename + ".jpg")
mvlib.io.imsave(path_save, list_tpl_imgs[i])
return dict_tpl
这里,同一字符有必要多存储几张,最后择优(或者一个字符通过多个模板匹配的结果来确定)。
4.2. 模板修复
这个过程,虽然没啥子技术含量,但却对结果影响很大。在前一步骤中,我们每一个字符都收集了多张模板图像。现在,从中择优录取。还有,可以手动编辑模板的图片,去除模板多余的白边(边并不是文字内容的一部分,而且会降低字符的匹配度)。
4.3. 重新加载模板数据
def load_saved_tpls(dir_tpl):
saved_tpls = os.listdir(dir_tpl)
dict_tpl = {} # {"1": imread("mvdev/tmp/tpl/1.jpg"), ...}
for i in saved_tpls:
filename = os.path.splitext(i)[0]
path_tpl = os.path.join(dir_tpl, i)
im_rgb = cv2.imread(path_tpl)
im_gray = mvlib.color.rgb2gray(im_rgb)
dict_tpl[filename] = im_gray
return dict_tpl
dir_tpl = "tpl/"
dict_tpls = load_saved_tpls(dir_tpl)
4.4. 模板匹配
def number_ocr_matching(im_char):
most_likely = [1, ""]
for key, im_tpl in dict_tpls.items():
try:
pos, similarity = mvlib.feature.match_template(im_char, im_tpl, way="most")
if similarity < most_likely[0]:
most_likely = [similarity, key]
except:
im_char_old = im_char.copy()
h = max(im_char.shape[0], im_tpl.shape[0])
w = max(im_char.shape[1], im_tpl.shape[1])
im_char = np.ones((h,w), dtype="uint8") * 255
# im_char2 = mvlib.pixel.bitwise_and(z, im_char)
im_char[:im_char_old.shape[0], :im_char_old.shape[1]] = im_char_old
pos, similarity = mvlib.feature.match_template(im_char, im_tpl, way="most")
if similarity < most_likely[0]:
most_likely = [similarity, key]
print(f"字符识别为【{most_likely[1]}】相似度【{most_likely[0]}】")
return most_likely[1]
def application(list_char_imgs):
str_ocr = ""
for im_char in list_char_imgs:
width_img = im_char.shape[1]
# 判断字符
match_char = number_ocr_matching(im_char)
str_ocr += match_char
return str_ocr
str_ocr2 = application(list_char_imgs)
print(str_ocr2)
过程中,opencv出现了报错,是由于模板的shape大于当前分割字符的shape。这个很正常,采集图像时由于距离的微调(注意,距离变化不能太大,OpenCV的默认算子不支持模板缩放)可能导致字符尺寸更小。解决方案也很简单,直接把字符图像拓展到大于模板的状态就OK了。

额,忘了删除debug信息了……再来一次~

【实战】基于OpenCV的水表字符识别(OCR)的更多相关文章
- 使用Python基于OpenCV和Tesseract的OCR
OCR OCR(Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗.亮的模式确定其形状,然后用字符识别方法将形 ...
- 基于opencv的手写数字字符识别
摘要 本程序主要参照论文,<基于OpenCV的脱机手写字符识别技术>实现了,对于手写阿拉伯数字的识别工作.识别工作分为三大步骤:预处理,特征提取,分类识别.预处理过程主要找到图像的ROI部 ...
- selenium2自动化测试实战--基于Python语言
自动化测试基础 一. 软件测试分类 1.1 根据项目流程阶段划分软件测试 1.1.1 单元测试 单元测试(或模块测试)是对程序中的单个子程序或具有独立功能的代码段进行测试的过程. 1.1.2 集成测试 ...
- 字符识别OCR原理及应用实现
字符识别OCR原理及应用实现 文本是人类最重要的信息来源之一,自然场景中充满了形形色色的文字符号.光学字符识别(OCR)相信大家都不陌生,就是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过 ...
- 图像矫正-基于opencv实现
一.引言 上篇文章中四种方法对图像进行倾角矫正都非常有效.Hough变换和Radon相似,其抗干扰能力比较强,但是运算量大,程序执行慢,其改进方法为:我们可以不对整幅图像进行操作,可以在图像中选取一块 ...
- 基于BP神经网络的字符识别研究
基于BP神经网络的字符识别研究 原文作者:Andrew Kirillov. http://www.codeproject.com/KB/cs/neural_network_ocr.aspx 摘要:本文 ...
- 字符识别OCR研究一(模板匹配&BP神经网络训练)
摘 要 在MATLAB环境下利用USB摄像头採集字符图像.读取一帧保存为图像.然后对读取保存的字符图像,灰度化.二值化,在此基础上做倾斜矫正.对矫正的图像进行滤波平滑处理,然后对字符区域进行提取切割出 ...
- 基于 opencv 的图像处理入门教程
前言 虽然计算机视觉领域目前基本是以深度学习算法为主,但实际上很多时候对图片的很多处理方法,并不需要采用深度学习的网络模型,采用目前成熟的图像处理库即可实现,比如 OpenCV 和 PIL ,对图片进 ...
- [转载]卡尔曼滤波器及其基于opencv的实现
卡尔曼滤波器及其基于opencv的实现 源地址:http://hi.baidu.com/superkiki1989/item/029f65013a128cd91ff0461b 这个是维基百科中的链接, ...
随机推荐
- 关于MySQL数据被删除后空间重用的问题实验
以前知道,MySQL在通过delete语句删除数据后,空间并不会被腾出,而只是在数据文件中被标记为已删除,除非执行optimize table.前两天听说,虽然delete数据后硬盘空间不会被腾出,但 ...
- 【漫画】ES原理 必知必会的倒排索引和分词
倒排索引的初衷 倒排索引,它也是索引.索引,初衷都是为了快速检索到你要的数据. 我相信你一定知道mysql的索引,如果对某一个字段加了索引,一般来说查询该字段速度是可以有显著的提升. 每种数据库都有自 ...
- 软链接 vs. 硬链接
链接大家都用过,比如 Windows 中的快捷方式就是一种链接,可是 Linux 里又分硬链接和软链接,它们表示什么意思,又有什么区别呢,本文来给大家做一个解释. Inode 索引节点 要想理解硬链 ...
- 官网下载Java连接MySql驱动jar包
官网地址:http://dev.mysql.com/downloads/connector/ 1.选择下载驱动 2.选择下载 3.可以不登录直接下载 4.下载下来的是zip压缩包,解压之后,文件夹中有 ...
- pycharm安装Numba失败问题
相关环境变量: pycharm Python 3.8 pip 19.3.1 Numba各个版本都不行 报错内容: Looking in indexes: https://pypi.tuna.tsing ...
- go模板-代码生成器
能用程序去做的事,就不要用手,编写自己的代码生成器就是用来解放你的双手,替你做一些重复性的工作. 上篇帖子写了模板的基础 go模板详说 ,有了基础就要做点什么东西,把所学到的东西应用起来才能更好的进步 ...
- 【JavaScript数据结构系列】03-队列Queue
[JavaScript数据结构系列]03-队列Queue 码路工人 CoderMonkey 转载请注明作者与出处 1. 认识队列Queue结构 队列,跟我们的日常生活非常贴近,我们前面举例了食堂排队打 ...
- [SD心灵鸡汤]002.每月一则 - 2015.06
1.用最多的梦面对未来 2.自己要先看得起自己,别人才会看得起你 3.一个今天胜过两个明天 4.要铭记在心:每天都是一年中最美好的日子 5.乐观者在灾祸中看到机会:悲观者在机会中看到灾祸 6.有勇气并 ...
- jchdl - RTL Data Types
https://mp.weixin.qq.com/s/hWYW1Bn---WhpwVu2e98qA 一. Bit 类结构如下: 主要属性: value: bit的值,只支持0,1, ...
- 一文带你了解js数据储存及深复制(深拷贝)与浅复制(浅拷贝)
背景 在日常开发中,偶尔会遇到需要复制对象的情况,需要进行对象的复制. 由于现在流行标题党,所以,一文带你了解js数据储存及深复制(深拷贝)与浅复制(浅拷贝) 理解 首先就需要理解 js 中的数据类型 ...