Spark调优(二) 数据本地化
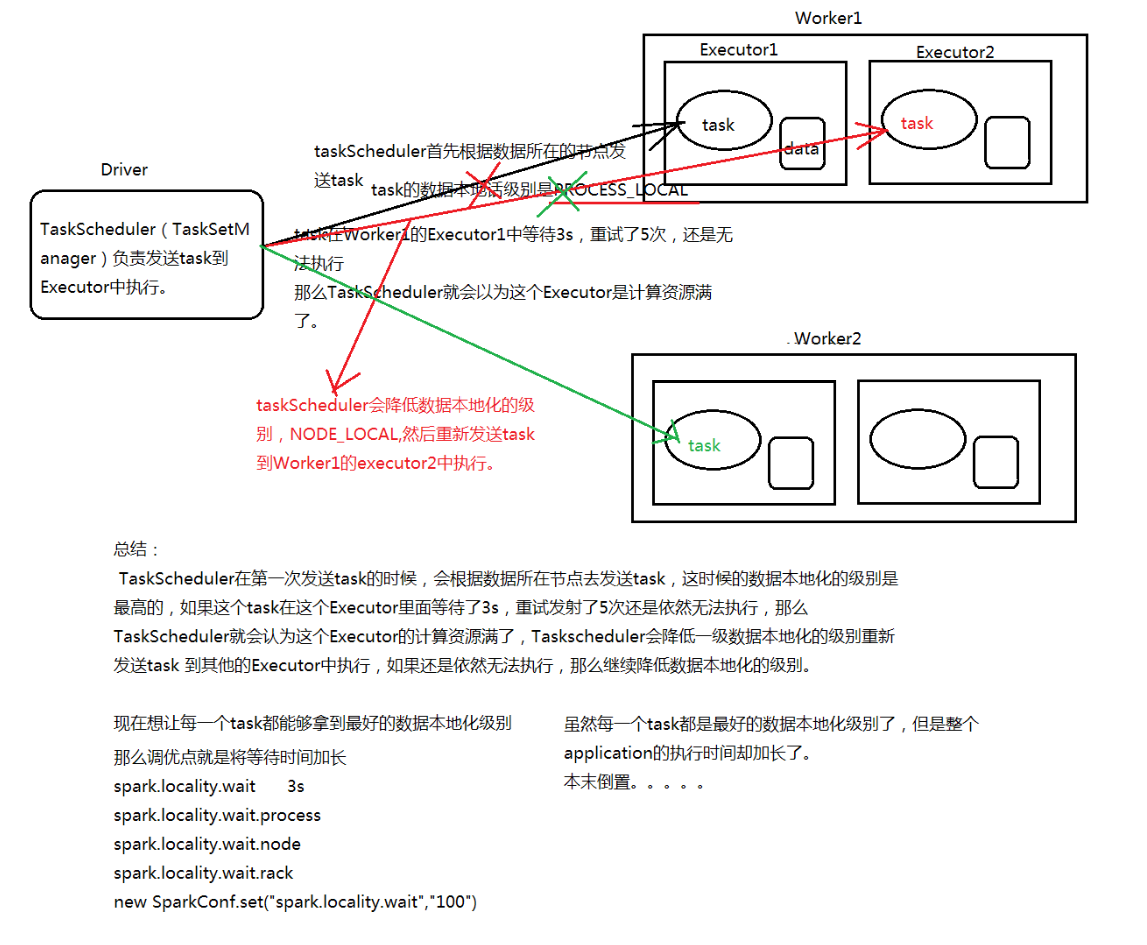
Application任务执行流程: 在Spark Application提交后,Driver会根据action算子划分成一个个的job,然后对每一 个job划分成一个个的stage,stage内部实际上是由一系列并行计算的task组成的,然后 以TaskSet的形式提交给你TaskScheduler,TaskScheduler在进行分配之前都会计算出 每一个task最优计算位置。Spark的task的分配算法优先将task发布到数据所在的节点上 ,从而达到数据最优计算位置。
一、数据本地化级别:
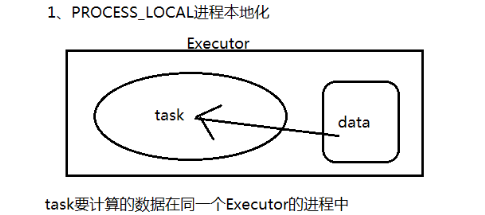
PROCESS_LOCAL 进程本地化
NODE_LOCA 节点本地化

NO_PREF 没有最佳位置这个说法 比如用到SparkSQl读取mysql数据库里的数据
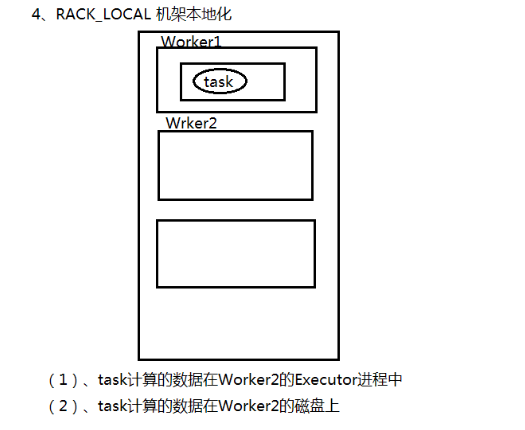
RACK_LOCAL 机架本地化
ANY 随机安排 跨机架
二、实际场景:

三、总结:
Spark调优(二) 数据本地化的更多相关文章
- 【Spark调优】数据本地化与参数调优
数据本地化对于Spark Job性能有着巨大的影响,如果数据以及要计算它的代码是在一起的,那么性能当然会非常高.但是,如果数据和计算它的代码是分开的,那么其中之一必须到另外一方的机器上.移动代码到其匹 ...
- 【Spark篇】---Spark调优之代码调优,数据本地化调优,内存调优,SparkShuffle调优,Executor的堆外内存调优
一.前述 Spark中调优大致分为以下几种 ,代码调优,数据本地化,内存调优,SparkShuffle调优,调节Executor的堆外内存. 二.具体 1.代码调优 1.避免创建重复的RDD,尽 ...
- 【Spark调优】数据倾斜及排查
[数据倾斜及调优概述] 大数据分布式计算中一个常见的棘手问题——数据倾斜: 在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或j ...
- spark调优篇-数据倾斜(汇总)
数据倾斜 为什么会数据倾斜 spark 中的数据倾斜并不是说原始数据存在倾斜,原始数据都是一个一个的 block,大小都一样,不存在数据倾斜: 而是指 shuffle 过程中产生的数据倾斜,由于不同的 ...
- Spark 调优之数据倾斜
什么是数据倾斜? Spark 的计算抽象如下 数据倾斜指的是:并行处理的数据集中,某一部分(如 Spark 或 Kafka 的一个 Partition)的数据显著多于其它部分,从而使得该部分的处理速度 ...
- 【Spark调优】Broadcast广播变量
[业务场景] 在Spark的统计开发过程中,肯定会遇到类似小维表join大业务表的场景,或者需要在算子函数中使用外部变量的场景(尤其是大变量,比如100M以上的大集合),那么此时应该使用Spark的广 ...
- 【Spark调优】大表join大表,少数key导致数据倾斜解决方案
[使用场景] 两个RDD进行join的时候,如果数据量都比较大,那么此时可以sample看下两个RDD中的key分布情况.如果出现数据倾斜,是因为其中某一个RDD中的少数几个key的数据量过大,而另一 ...
- 【Spark调优】小表join大表数据倾斜解决方案
[使用场景] 对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中的一个RDD或表的数据量比较小(例如几百MB或者1~2GB),比较适用此方案. [解决方案] ...
- Spark调优_性能调优(一)
总结一下spark的调优方案--性能调优: 一.调节并行度 1.性能上的调优主要注重一下几点: Excutor的数量 每个Excutor所分配的CPU的数量 每个Excutor所能分配的内存量 Dri ...
- 【Spark学习】Apache Spark调优
Spark版本:1.1.0 本文系以开源中国社区的译文为基础,结合官方文档翻译修订而来,转载请注明以下链接: http://www.cnblogs.com/zhangningbo/p/4117981. ...
随机推荐
- 线上学习-语言模型 language model
chain rule markov assumption 评估语言模型 平滑方法
- springboot集成拦截器
一.首先对HandlerInterceptor进行封装,封装为MappingInterceptor.封装的方法里添加拦截器起作用的路径addPathPatterns(),及需要排除路径的方法exclu ...
- 知乎模拟登录,支持验证码和保存 Cookies
import requests import time import re import base64 import hmac import hashlib import json import ma ...
- Tomcat认识
Tomcat目录结构: bin:存放启动和关闭的一些脚本 common:共享(部署在该服务器上的一些)jar包 conf:存放服务器的一些配置文件 webapps:部署文件 work:服务器运行时,产 ...
- Spring学习(二)
IoC 1.Inverse of Control ,控制反转(控制权的翻转) 2.控制:对对象的创建.对对象的属性赋值等一系列操作本来应该是我们做的事情 Java Application : Date ...
- C 语言入门---第十一章---C语言重要知识点补充
====C语言typedef 的用法==== 1. C语言允许为一个数据类型起一个新的别名,就像给人起绰号一样. typedef OldName newName; typedef 和 #define ...
- FiBiNET-学习
Our main contributions are listed as follows: • Inspired by the success of SENET in the computer vis ...
- 第2节 Scala中面向对象编程:7、继承的概念以及override和super关键字;8、isInstanceOf 和 asInstanceOf关键字
6.3. Scala面向对象编程之继承 6.3.1. Scala中继承(extends)的概念 Scala 中,让子类继承父类,与 Java 一样,也是使用 extends 关键字: 继承 ...
- Android。WebView加载UR请求使用Cookie储存User_Id记录用户是否登陆过
1.WebView初始化的时候用倒如下代码: if (Build.VERSION.SDK_INT >= 21) { CookieManager.getInstance().setAcceptTh ...
- [POI 2014]PTA-Little Bird
Description 题库连接 给你 \(n\) 棵树,第 \(i\) 棵树的高度为 \(d_i\).有一只鸟从 1 号树出发,每次飞跃不能超过 \(k\) 的距离.若飞到下一棵树的高度大于等于这一 ...