Spark调优(二) 数据本地化
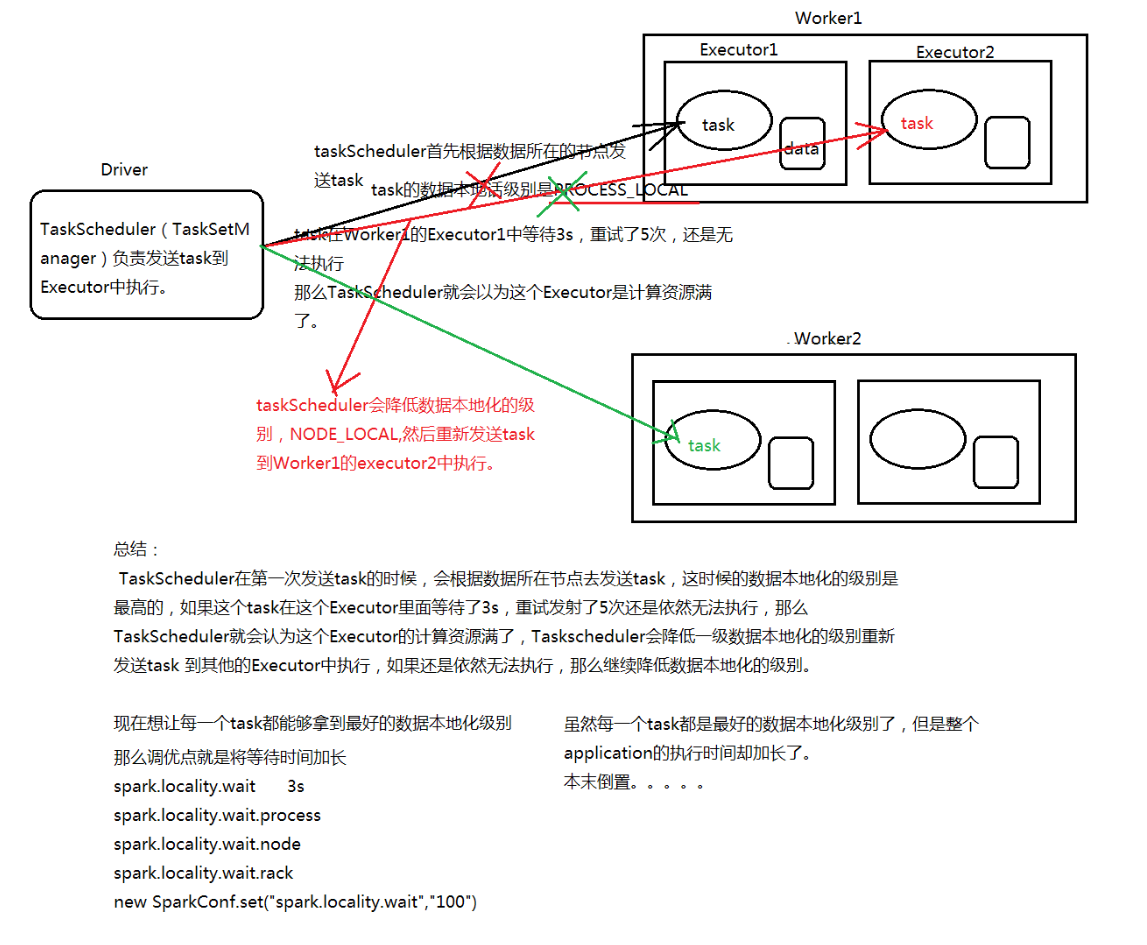
Application任务执行流程: 在Spark Application提交后,Driver会根据action算子划分成一个个的job,然后对每一 个job划分成一个个的stage,stage内部实际上是由一系列并行计算的task组成的,然后 以TaskSet的形式提交给你TaskScheduler,TaskScheduler在进行分配之前都会计算出 每一个task最优计算位置。Spark的task的分配算法优先将task发布到数据所在的节点上 ,从而达到数据最优计算位置。
一、数据本地化级别:
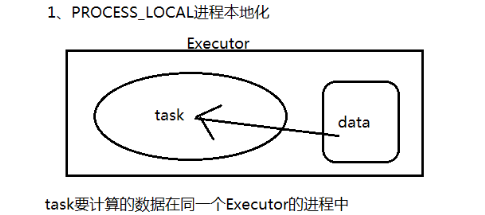
PROCESS_LOCAL 进程本地化
NODE_LOCA 节点本地化

NO_PREF 没有最佳位置这个说法 比如用到SparkSQl读取mysql数据库里的数据
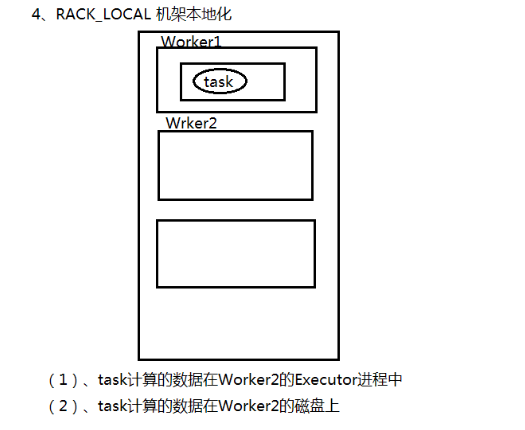
RACK_LOCAL 机架本地化
ANY 随机安排 跨机架
二、实际场景:

三、总结:
Spark调优(二) 数据本地化的更多相关文章
- 【Spark调优】数据本地化与参数调优
数据本地化对于Spark Job性能有着巨大的影响,如果数据以及要计算它的代码是在一起的,那么性能当然会非常高.但是,如果数据和计算它的代码是分开的,那么其中之一必须到另外一方的机器上.移动代码到其匹 ...
- 【Spark篇】---Spark调优之代码调优,数据本地化调优,内存调优,SparkShuffle调优,Executor的堆外内存调优
一.前述 Spark中调优大致分为以下几种 ,代码调优,数据本地化,内存调优,SparkShuffle调优,调节Executor的堆外内存. 二.具体 1.代码调优 1.避免创建重复的RDD,尽 ...
- 【Spark调优】数据倾斜及排查
[数据倾斜及调优概述] 大数据分布式计算中一个常见的棘手问题——数据倾斜: 在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或j ...
- spark调优篇-数据倾斜(汇总)
数据倾斜 为什么会数据倾斜 spark 中的数据倾斜并不是说原始数据存在倾斜,原始数据都是一个一个的 block,大小都一样,不存在数据倾斜: 而是指 shuffle 过程中产生的数据倾斜,由于不同的 ...
- Spark 调优之数据倾斜
什么是数据倾斜? Spark 的计算抽象如下 数据倾斜指的是:并行处理的数据集中,某一部分(如 Spark 或 Kafka 的一个 Partition)的数据显著多于其它部分,从而使得该部分的处理速度 ...
- 【Spark调优】Broadcast广播变量
[业务场景] 在Spark的统计开发过程中,肯定会遇到类似小维表join大业务表的场景,或者需要在算子函数中使用外部变量的场景(尤其是大变量,比如100M以上的大集合),那么此时应该使用Spark的广 ...
- 【Spark调优】大表join大表,少数key导致数据倾斜解决方案
[使用场景] 两个RDD进行join的时候,如果数据量都比较大,那么此时可以sample看下两个RDD中的key分布情况.如果出现数据倾斜,是因为其中某一个RDD中的少数几个key的数据量过大,而另一 ...
- 【Spark调优】小表join大表数据倾斜解决方案
[使用场景] 对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中的一个RDD或表的数据量比较小(例如几百MB或者1~2GB),比较适用此方案. [解决方案] ...
- Spark调优_性能调优(一)
总结一下spark的调优方案--性能调优: 一.调节并行度 1.性能上的调优主要注重一下几点: Excutor的数量 每个Excutor所分配的CPU的数量 每个Excutor所能分配的内存量 Dri ...
- 【Spark学习】Apache Spark调优
Spark版本:1.1.0 本文系以开源中国社区的译文为基础,结合官方文档翻译修订而来,转载请注明以下链接: http://www.cnblogs.com/zhangningbo/p/4117981. ...
随机推荐
- js里常见的三种请求方式$.ajax、$.post、$.get分析
$.post和$.get是$.ajax的一种特殊情况: $.post和$.get请求都是异步请求,回调函数里写return来返回值是无意义的, 回调函数里对外部变量进行赋值也是无意义的. 即使是$.a ...
- 【原】Google浏览器刷新
- vue.js ②
1.Vue实例的生命周期钩子 每个 Vue 实例在被创建时都要经过一系列的初始化过程——例如,需要设置数据监听.编译模板.将实例挂载到 DOM 并在数据变化时更新 DOM 等.同时在这个过程中也会运行 ...
- nginx、apache和tomcat之间的关系和区别
Apache/Nginx 应该叫做 HTTP Server,即安装后生成httpd服务. Tomcat 则是一个 Application Server,或者更准确的来说,是一个「Servlet/JSP ...
- mysql 官方读写分离方案
mysql 8.0 集群模式下的自动读写分离方案 问题 多主模式下的组复制,看起来挺好,起始问题和限制很多.而且中断一个复制就无法配置了 多主模式下,innodbcluster 等于是无用的,不需要自 ...
- 误删Django的model中的表解决办法
误删Django的model中的表解决办法 1.model里面的表格实际的操作都在migrations文件夹中,里面记录了操作过程,当在database和model中删除表格时要注意初始化数据库时会报 ...
- VM player无法联网问题
情况就是vmplayer不能联网,能联网的话右上角会显示Wired Connected的 在VM里面看了网络设置,是和主机共享IP(常用)没错.那问题就在PC上了,在win+r输入services.m ...
- 吴裕雄 Bootstrap 前端框架开发——Bootstrap 排版:可滚动
<!DOCTYPE html> <html> <head> <title>菜鸟教程(runoob.com)</title> <meta ...
- Simple English
Simple English 1. Basic English 1.1 设计原则: 1.2 基本英语单词列表850个 1.3 规则: 1.4 质疑 1.5 维基百科:基本英语组合词表 1.6 简单英文 ...
- 63 滑动窗口的最大值 &&front(),back()操作前一定要判断容器的尺寸不能为0
给定一个数组和滑动窗口的大小,找出所有滑动窗口里数值的最大值.例如,如果输入数组{2,3,4,2,6,2,5,1}及滑动窗口的大小3,那么一共存在6个滑动窗口,他们的最大值分别为{4,4,6,6,6, ...