StormDRPC流程解读
Storm 的编程模型是一个有向无环图,模型角度决定了 Storm 的 Spout 接收到外部系统的请求,将请求数据分发给下游的 bolt 进行处理后,spout 并不能得到 bolt 的处理结果并将结果返回给外部请求。所以应用场景中 Storm 对外部系统的调用都是采用回调的方式:
- 接收外部系统的请求,将请求得到的数据发到消息队列中,就立马响应给外部系统。
- 然后 Storm 实时平台去消息队列中拉取数据并进行分布式并行处理,再将运算完的结果存入第三方存储介质(外部系统直接通过读取该介质获取结果)或者调用外部系统的接口将处理的结果推送出去(以回调的方式实现伪同步请求)。
但假如有一个需求:项目要接入各大银行的系统中,通过要求对方提供一个回调接口来实现同步是不可能的。必须依靠自己去实现同步请求响应,外部系统将消息发往storm实时平台,然后外部系统会阻塞,等待storm实时平台处理完后将结果返回给外部系统。这就要用到 DRPC了。
Strom DRPC
DRPC设计目的是为了充分利用Storm的计算能力实现高密度的并行实时计算。通过一个 DRPC Server 负责接收 RPC 请求,并将该请求发送到 Storm 中运行的 Topology,等待接收 Topology 发送的处理结果,并将该结果返回给发送请求的客户端。
一个 DRPC请求过程:客户端程序向 DRPC Server 发送要执行的函数名称和该函数的参数。DRPC Server 将函数调用放到队列中,并用一个惟一的id标记,具备 DRPC功能的拓扑会使用一个 DRPCSpout 拉取 。Topo 计算好结果后会由一个名为 ReturnResults 的 bolt 去 连接 DRPC Server 给出对应函数调用id的结果,然后 DRPC Serve 根据 ID 找到等待中的客户端,为等待中的客户端消除阻塞,并发送结果给客户端。具体工作流程如下图所示:
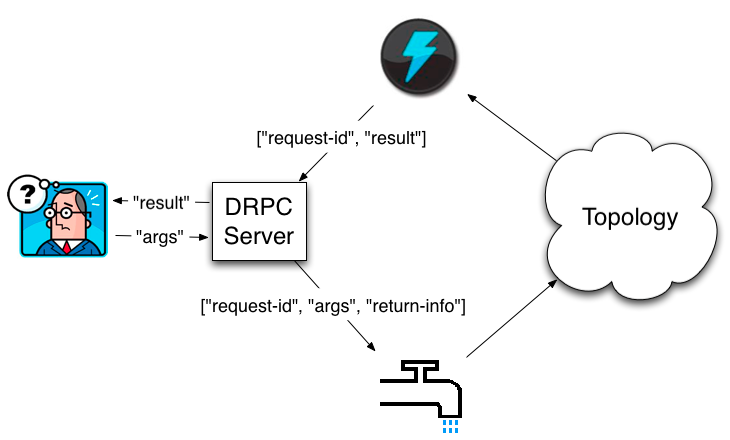
从一个客户端的角度来看,一个分布式RPC调用就像是一个常规的RPC调用。只需要传输服务名和请求参数即可。
实际就是个同步的、向远程系统发送socket请求并得到远程系统处理的结果的分布式调用而已。
DRPC请求流程
由上面的架构图可以发现,DRPC Server 相当于一个第三方服务:
- 负责接收外部系统的请求,将外部请求的参数存入一个先进先出的队列中,阻塞等待 Storm Topo 处理的结果。
- Storm Topo 的 spout 中创建 socket 去连接中转程序,spout 不断拿队列中请求参数来处理。
- spout获取到请求参数后,将参数传给下游的bolt去计算,下游的最后一层bolt计算完也创建socke去连接中转程序并将结果发送给中转程序。
- 中转程序中阻塞的地方轮询得到结果后,就结束轮询响应给外部系统了。
DRPC Server 要同时协调三个不同的程序的请求,通过源码可知其通过定义 Thrift 接口完成了进程间的通信,下面来详解每个过程。
0. Thrift接口
由于 Strom 的 drpc 是通过 thrift 框架 进行 rpc调用的,所以先查看 strom.thrift。有两个 thrift 接口: DistributedRPC 和 DistributedRPCInvocations 。
- DistributedRPC:定义 DRPC客户端 和 DRPC Server端 之间的调用方法 execute(),暴露给 业务客户端使用;
- DistributedRPCInvocations:定义 DRPC Server端 和 服务端逻辑处理Topo 之间的 拉取请求参数 以及 返回结果的 方法;
service DistributedRPC {
// 请求 drpc 方法
string execute(1: string functionName, 2: string funcArgs) throws (1: DRPCExecutionException e, 2: AuthorizationException aze);
}
service DistributedRPCInvocations {
// 返回 业务topo 处理结果给 DRPCServer
void result(1: string id, 2: string result) throws (1: AuthorizationException aze);
// 业务topo 拉取 DRPCServer从客户端接收到的请求
DRPCRequest fetchRequest(1: string functionName) throws (1: AuthorizationException aze);
void failRequest(1: string id) throws (1: AuthorizationException aze);
void failRequestV2(1: string id, 2: DRPCExecutionException e) throws (1: AuthorizationException aze);
}
struct DRPCRequest {
1: required string func_args;
2: required string request_id;
}
需要查看对两个 thrift 接口的具体实现逻辑,只要查看接口的实现类即可,DRPC Server 中的具体实现类是 DRPCThrift,它同时实现了两个接口中的方法,即处理 DRPC客户端的请求,又处理 DRPC业务Topo拉请求的请求。
1. execute( ) 接收客户端请求
进行 DRPC调用的第一步是 客户端调用 execute(name, args) ,DRPC Server 的 execute( ) 会对该请求做如下处理:
- 将请求封装成 BlockingOutstandingRequest req,然后 req.getResult() 使用 req 内部的一个Semaphore 实现 acquire() 请求阻塞,直到 DRPC Server 端接到 业务topo 的结果才 release。
- 将请求添加到队列中,等待 业务 topo进行拉取消费。
public class DRPCThrift implements DistributedRPC.Iface, DistributedRPCInvocations.Iface {
// 构造方法注入
private final DRPC drpc;
//请求队列 <requestName, request queue>,将请求排队给业务topo消费,Waiting to be fetched
ConcurrentHashMap<String, ConcurrentLinkedQueue<OutstandingRequest>> _queues =
new ConcurrentHashMap<>();
//结果map <requestId, request>,用来接收结果返回给客户端,Waiting to be returned
_requests = new ConcurrentHashMap<>();
@Override
public String execute(String functionName, String funcArgs)
throws DRPCExecutionException, AuthorizationException {
return drpc.executeBlocking(functionName, funcArgs);
}
}
public class DRPC implements AutoCloseable {
public String executeBlocking(String functionName, String funcArgs) throws DRPCExecutionException, AuthorizationException {
String id = nextId();
T req = BlockingOutstandingRequest
.FACTORY
.mkRequest(functionName, new DRPCRequest(funcArgs, id));
_requests.put(id, req);
ConcurrentLinkedQueue<OutstandingRequest> q = getQueue(functionName);
q.add(req);
try {
return req.getResult();
} finally {
cleanup(req.getRequest().get_request_id());
}
}
}
2. DRPCSpout 拉取请求
DRPCSpout 作为 thrift客户端 通过调用 fetchRequest() 拉取请求,这里需要转换一下思维,DRPCThrift 依然作为 thrift 服务端,所以 DRPCThrift 要实现两个接口。
因此 DRPCSpout 使用的是 DRPCInvocationsClient extends ThriftClient implements DistributedRPCInvocations.Iface,在 nextTuple() 中不断调用 client.fetchRequest(function); 得到 DRPC客户端 的请求来处理。
3. 业务Topo链路
后面的流程就进入我们编写的业务 Topo 中了,通过 LinearDRPCTopologyBuilder 的builder.createRemoteTopology() 来构建线性的drpc topo,该topo的链路为:spout -> PrepareRequest Bolt-> 用户bolt1 -> 用户bolt2 -> JoinResult Bolt -> ReturnResults Bolt
其中 JoinResult Bolt ,用两个 Map 分别记录 PrepareRequest 收到的请求 Id,最后一个业务Topo处理后的请求 Id,这两个Id是一样的,当两个Id都在 Map中时就认为该 DRPC请求完成,则继续发送给 ReturnResults Bolt 。
最后 ReturnResults Bolt 通过调用 client.result(id, result); 用于返回 Topo 处理结果,在 DRPC 类中 returnResult() 的具体实现:
- 从 _requests Map 拿出对应的请求,然后将 result 注入进去,同时 _sem.release(); 将信号量释放,去掉对请求的阻塞;
- 在 DRPC 中的 req.getResult(); 将不再被阻塞,立刻将 DRPC Server 请求返回给客户端。
# DRPC类
public void returnResult(String id, String result) {
OutstandingRequest req = _requests.get(id);
if (req != null) {
req.returnResult(result);
}
}
}
# BlockingOutstandingRequest 类
public void returnResult(String result) {
_result = result;
_sem.release();
}
需要注意的问题
相关类职责
- DRPCServer:DRPC Server上帝类,启动用于执行 DRPC 请求的 ThriftServer 端实例,会启动两个 ThriftServer
- handlerServer 用于接收 DRPC客户端的请求;
- invokeServer 用于接收 求经过Topo进行业务处理后的 result,然后返回给 handlerServer;
- ThriftServer:对 Thrift 框架 服务端 启动、停止 操作的封装;
- DRPCThrift:DRPC Server 的业务类,包装 DRPC类的调用;
- DRPC:DRPC Server 的业务类
thrift客户端到服务端调用链路问题
阅读源码的过程中对 DRPCSput 的 client.fetchRequest(function);链路不清楚,想看它的服务端业务是怎么实现的,点进去看到的是 DRPCInvocationsClient 的 fetchRequest() ,这里c.fetchRequest(func);居然是直接又用 thrift客户端调 fetchRequest()?看:
public class DRPCInvocationsClient extends ThriftClient implements DistributedRPCInvocations.Iface {
// 构造方法
client.set(new DistributedRPCInvocations.Client(protocol));
// # DRPCInvocationsClient
@Override
public DRPCRequest fetchRequest(String func) {
DistributedRPCInvocations.Client c = client.get();
if (c == null) {
throw new TException("Client is not connected...");
}
// 这里是真正的客户端请求,DistributedRPCInvocations.Client 是 thrift 抽象的客户端
return c.fetchRequest(func);
}
}
小伙子,你会以为fetchRequest(func)是重复的 thrift客户端调用,说明你对 DRPCInvocationsClient 类不熟,对设计模式也不熟啊!!首先,DRPCInvocationsClient 和DistributedRPCInvocations.Client一样,都实现 DistributedRPCInvocations.Iface,你就根据仅有的thrift知识,以为实现了DistributedRPCInvocations.Iface接口的都是要写服务端业务逻辑的;其实这里DRPCInvocationsClient只是用了静态代理模式,对 DistributedRPCInvocations.Client的代理而已,对各方法多了异常处理啊,真正的客户端请求确实是c.fetchRequest(func);
既然这样,那就看还有什么类是实现了 DistributedRPCInvocations.Iface接口的,就是c.fetchRequest(func);对应的服务端相应逻辑,就在DRPCThrift implements DistributedRPC.Iface, DistributedRPCInvocations.Iface,同时实现了两个 drpc 的接口进行全部方法实现,具体逻辑在DRPCThrift的成员变量DRPC类中!
class DRPC {
// DRPCSpout 中调用的 fetchRequest,实际调用的是这里。
public DRPCRequest fetchRequest(String functionName) throws AuthorizationException {
meterFetchRequestCalls.mark();
checkAuthorizationNoLog("fetchRequest", functionName);
ConcurrentLinkedQueue<OutstandingRequest> q = getQueue(functionName);
OutstandingRequest req = q.poll();
if (req != null) {
//Only log accesses that fetched something
logAccess("fetchRequest", functionName);
req.fetched();
DRPCRequest ret = req.getRequest();
return ret;
}
return NOTHING_REQUEST;
}
}
参考
StormDRPC流程解读的更多相关文章
- Dockerfile与Docker构建流程解读
摘要 本文主要讨论了对docker build的源码流程进行了梳理和解读,并分享了在制作Dockerfile过程中的一些实践经验,包括如何调试.优化和build中的一些要点.另外,还针对现有Docke ...
- StageFright框架流程解读
1. StageFright介绍 Android froyo版本号多媒体引擎做了变动,新加入�了stagefright框架,而且默认情况android选择stagefright,并没有全 ...
- 使用Application Loader上传APP流程解读[APP公布]
本文仅仅是提供一个公布流程的总体思路.假设没有公布经验.建议阅读苹果官方公布文档或者Google搜索具体教程. 1.申请开发人员账号:99美金的(须要信用卡支付),详细流程网上有非常多样例.自行搜索. ...
- HashMap之put方法流程解读
说明:本文中所谈论的HashMap基于JDK 1.8版本源码进行分析和说明. HashMap的put方法算是HashMap中比较核心的功能了,复杂程度高但是算法巧妙,同时在上一版本的基础之上优化了存储 ...
- RocketMQ之九:RocketMQ消息发送流程解读
在讨论这个问题之前,我们先看一下Client的整体架构. Producer与Consumer类体系 从下图可以看出以下几点:(1)Producer与Consumer的共同逻辑,封装在MQClientI ...
- MySQL Update执行流程解读
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. 一.update跟踪执行配置 使用内部程序堆栈跟踪工具path_viewer,跟踪mysql update 一行数据的执行 ...
- WebRTC学习之 Intel® Collaboration Suite for WebRTC源码流程解读
年后回来,因为新项目的需求,开始了解WebRTC相关的知识.目前接触的是Intel® Collaboration Suite for WebRTC.刚开始看SDK发现很多概念是我目前不知道的,于是恶补 ...
- Netty引导流程解读
Channel的生命周期状态[状态转换将变为相应的事件,转发给ChannelPipeline中的ChannelHandler进行处理] ChannelUnregistered:Channel已经被创建 ...
- 【Away3D代码解读】(三):渲染核心流程(渲染)
还是老样子,我们还是需要先简略的看一下View3D中render方法的渲染代码,已添加注释: //如果使用了 Filter3D 的话会判断是否需要渲染深度图, 如果需要的话会在实际渲染之前先渲染深度图 ...
随机推荐
- SHELL用法六(Find语句)
1.SHELL编程Find语句案例实战 1)SHELL编程四剑客工具:Find.Grep.Sed.Awk,通过四剑客可以完成常规Linux指令无法完成或者比较复杂的功能,学好SHELL编程四剑客有助于 ...
- miracle|
N-COUNT 奇迹;出人意料的事If you say that a good event is a miracle, you mean that it is very surprising and ...
- 使用fiddler盖楼评论
使用fiddler盖楼评论:使用replay重复请求某接口
- PHP PSR-2 代码风格规范
代码风格规范 本篇规范是 PSR-1 基本代码规范的继承与扩展. 本规范希望通过制定一系列规范化PHP代码的规则,以减少在浏览不同作者的代码时,因代码风格的不同而造成不便. 当多名程序员在多个项目中合 ...
- 吴裕雄--天生自然python编程:turtle模块绘图(4)
import turtle bob = turtle.Turtle() for i in range(1,5): bob.fd(100) bob.lt(90) turtle.mainloop() im ...
- 由生到死10个月!做App中的“二”有多难
十月,原本是怀胎过程的喜悦时光,但这段个时光,如今却是绝大多数App从生到死的所有时间.在App市场表面形式一片大好,彻底主宰我们生活.工作.娱乐的当下,绝大多数用户只是在App海洋中只取一瓢饮,其他 ...
- maven创建Java项目命令
1.maven创建普通Java项目的命令 mvn archetype:create -DgroupId=packageName -DartifactId=projectName 2.maven创建Ja ...
- centos上安装python环境
1.安装python-pip 首先安装epel扩展源: yum -y install epel-release 更新完成之后,安装pip: yum -y install python- ...
- git push 时不用每次都输入密码的方法
在本地克隆下来的git仓库中找到 .git 目录 (.git 目录是隐藏文件夹 在组织->文件夹和搜索选项-> 查看选项卡 -> 隐藏文件和文件夹 -> 显示隐藏的文件.文件夹 ...
- App自动化测试方案
App自动化测试方案 1.1 概述 什么是App自动化?为什么要做App自动化? App自动化是指给 Android或iOS上的软件应用程序做的自动化测试. 手工测试和自动化测试的对比如下: 手工测 ...