java常用容器简要性能分析(List。Map。Set)
嗯,实习的时候看到这个,感觉蛮好,这里摘录学习,生活加油:
我曾经害怕别人嘲笑的目光,后来,发现他们的目光不会在我身上停留太久,人们更愿意把目光放在自己身上。 知乎上看到,讲给自己。
List
List和Set都属于Collection的子接口,List集合中的元素是按照插入顺序进行排列的,允许出现重复元素,
List接口下的常用实现类有ArrayList和LinkedList,对于List来讲,
元素只能是通过set更新,不能通过add更新,通过add只能在指定索引位置添加元素,不会实现元素的覆盖,通过remove移除
接口继承关系:

ArrayList :
// 查找指定位置元素的下标
public int indexOf(Object o);
// 查找指定元素最后一次出现的位置
public int lastIndexOf(Object o) ;
// 清空集合元素
public void clear();
// 等等......
ArrayList的特点: **
- ArrayList内部是使用数组来存储数据,并且是一个"动态"的数组,在添加元素时,如果发现容量不够时,会进 行扩容。
- ArrayList支持随机访问元素,随机访问元素的效率是O(1)
- ArrayList在尾部添加元素的效率为O(1),add方法默认在尾部进行添加,在使用的时候最好在尾部添加元素 效率更佳
- ArrayList在进行删除元素或者在中间、头部插入元素时会导致数组内部移动,进行数组拷贝,平均时间复杂度 为O(n)
ArrayList的迭代方式:
- 1、下标迭代
// 使用下标对List进行外部迭代
for (int i = 0; i < list.size(); i++) { System.out.println(list.get(i));}
- 2、可以使用增强for进行迭代
// 采用增强for的迭代方式其实底层是使用迭代器进行迭代,在迭代的过程中不允许对元素进行修改
for (String s : list) { System.out.println(s);}
- 3、采用内部迭代的方式
// 内部迭代forEach,在迭代的过程中仍然不允许对元素进行修改过删除操作
list.forEach(item -> System.out.println(item));
// 内部迭代还支持并行方式对元素进行迭代 如果数据量非常大的时候可以采用该方式(一般不采用)迭代出来的元素可能无序
list.parallelStream().forEach(System.out::println);
list.stream().forEach(System.out::print);
- 4、内部迭代底层实现
public void forEach(Consumer<? super E> action) { Objects.requireNonNull(action);
final int expectedModCount = modCount; @SuppressWarnings("unchecked")
final E[] elementData = (E[]) this.elementData; final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) { action.accept(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
- 5、使用迭代器进行迭代
// 直接使用迭代器进行迭代 这种迭代方式允许在迭代中对元素进行修改和删除操作
Iterator<Long> iterator = list.iterator(); while (iterator.hasNext()){
System.out.println(iterator.next());
}
几种迭代方式的性能比较
在数据规模为一千万的情况下内部迭代表现较好,尽管在千万级的数据量并行迭代依然速度不快,因为在线程的频换 切换和销毁等因素造成了一定的开销。
在百万数据规模的情况下,增强for的性能较好,可以根据数据量来对元素进行迭代,fori方式和增强for性能差异不是很大。

LinkedList:
LinkedList继承自AbstractSequentialList可以知道LinkedList的元素是顺序访问的,随机访问元素需要对链表进行遍历, 同样实现了克隆和序列化接口LinkedList还实现了Deque相关的方法,可以当做一个队列来使用
LinkedList的类继承关系
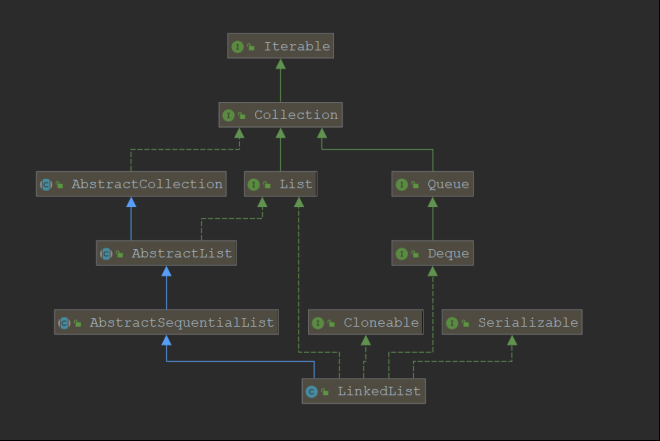
LinkedList的特点:
- LinkedList的内部数据结构是一个双向链表,有一个头结点和一个尾部节点,在头部和尾部插入的效率非常高O(1)
- LinkedList的平均查找效率为O(n)
- LinkedList的删除和修改都需要先定位元素的位置,但是对于删除操作本身只需要O(1)的时间复杂度LinkedList因为采用了链表结构,所以理论空间是没有限制的,不需要扩容
- LinkedList在使用下标访问元素的时候使用了折半查找,但是在数据量大的情况下,查找效率依然很慢 便于用作LRU
LinkedList的迭代方式
- LinkedList的迭代方式其实和ArrayList大同小异,但是ArrayList在进行get(index)的操作只需要O(1)的时间复杂度
所以我们在使用LinkedList的时候不采用fori形式的遍历
- 增强for方式进行遍历,其实相当于使用迭代器进行访问,增强for反编译以后其实就是iterator
- 使用迭代器对链表进行迭代,Linked的迭代器内部就是从头节点开始依次向下寻找节点
- 使用内部迭代forEach方式
几种迭代方式的比较:
- LinkedList使用增强for方式进行遍历速度较快,使用该fori进行遍历时候,在百万级数据量程序直接卡死,所以LinkedList严禁使用fori遍历
- 在千万级别数据量的情况下,速度和ArrayList差不多,但ArrayList较快,因为ArrayList数据空间是连续的


ArrayList和LinkedList的区别
- 是否保证线程安全: ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
- 底层数据结构: Arraylist 底层使用的是Object数组;LinkedList 底层使用的是双向链表数据结构(JDK1.6之前为循环链表,JDK1.7取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!)
- 插入和删除是否受元素位置的影响:
- ① ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行add(E e)方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element))时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。
- ② LinkedList 采用链表存储,所以插入,删除元素时间复杂度不受元素位置的影响,都是近似 O(1)而数组为近似 O(n)。
- 是否支持快速随机访问: LinkedList 不支持高效的随机元素访问,而 ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index)方法)。
- 内存空间占用: ArrayList的空 间浪费主要体现在在list列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱以及数据)
Map:
Map是双列集合,即存储元素的时候是键值对的形式在Map中存储的,一个Entry<K,V>结构的键值对映射,一个键对 应一个值,不允许出现重复的键,
HashMap
HashMap的类继承关系:
- HashMap继承自AbstractMap同样一个抽象类的出现是为了实现一些子类通用的方法,一些个性化的方法还需要子类 去实现

- HashMap内部是使用了散列表+红黑树进行存储数据的,即数组+链表+红黑树
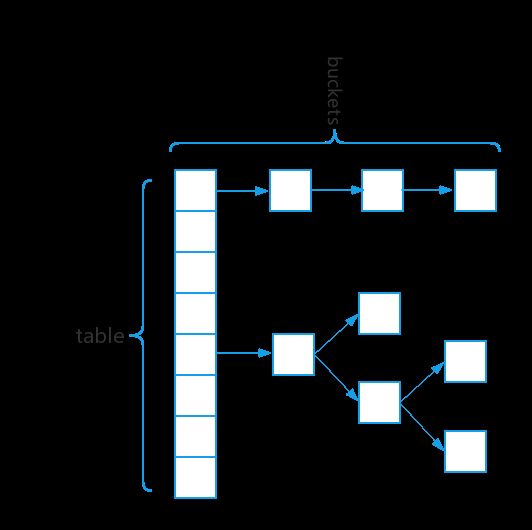
HashMap的特点
- HashMap使用位运算将HashMap中数组的大小一定是2的N次方,保证了在取出元素时候通过与运算能更高效 和更精确的定位数组下标
-
- 即使两个不一样的元素也可能会出现同样的hashCode,HashMap使用拉链法设计解决了Hash冲突问题,同一个散列槽(在我们这里就是数组的每一个槽)中的所有元素放到一个链表中
- HashMap在某一个槽上的链表长度大于等于8的时候并且HashMap中数组的长度大于等于64会进行树化,将 链表转换成红黑树以提升查询效率
- 在增删改查元素的时候平均时间复杂度为O(1)非常高效
- HashMap在插入的时候允许空键空值
- HashMap是非同步的,多线程同时操作的时候会发生并发修改异常

HashMap的迭代方式
- 通过keySet||valueSet进行遍历
// 获取到所有的key然后依次进行获取
Set<Integer> keySet = map.keySet(); Integer val = 0;
for (Integer key : keySet) { val = map.get(key);
System.out.print("");
}
- 通过entrySet对map进行遍历
Set<Map.Entry<Integer, Integer>> entrySet = map.entrySet();
for (Map.Entry<Integer, Integer> entry : entrySet) {
System.out.print("");
}
- 使用内部迭代
Map<Object,Object> objectObjectMap = new HashMap<>();
objectObjectMap.forEach( (o1, o2) ->System.out.println(o1.toString()+o2));
// 内部迭代底层依然是使用entrySet进行迭代,效率不如直接使用外部迭代
default void forEach(BiConsumer<? super K, ? super V> action) { Objects.requireNonNull(action);
for (Map.Entry<K, V> entry : entrySet()) { K k;
V v; try {
k = entry.getKey();
v = entry.getValue();
} catch(IllegalStateException ise) {
// this usually means the entry is no longer in the map. throw new ConcurrentModificationException(ise);
}
action.accept(k, v);
}
}
几种迭代方式的性能差异

LinkedHashMap:
LinkedHashMap是HashMap的一个子类,内部维护了一个双向链表保证了元素插入的顺序
HashMap的类继承关系
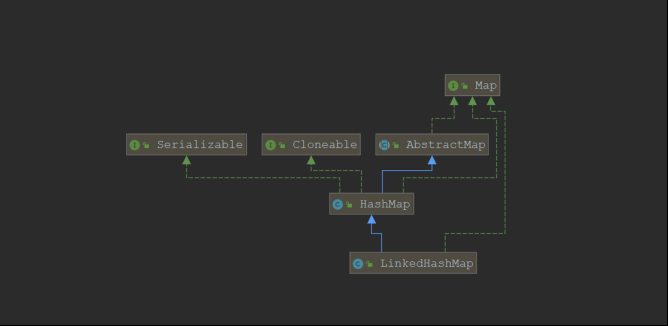
LinkedHashMap的数据结构
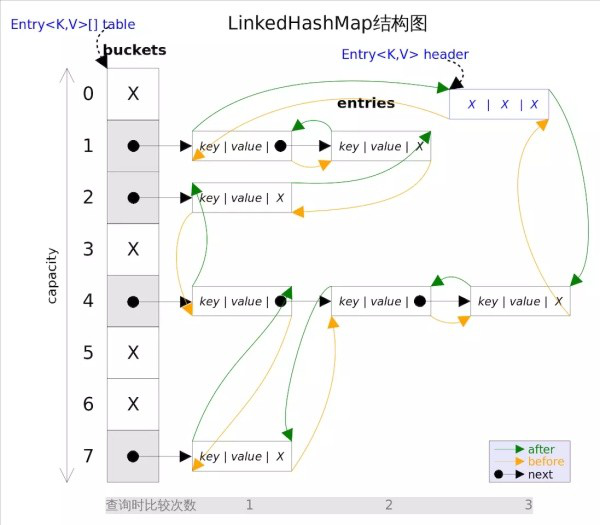
LinkedHashMap的特点
- LinkedHashMap是HashMap的子类,其增删改查的平均时间复杂度依然是O(1)
- LinkedHashMap的节点占用了更多的空间,包括指向前一个节点的指针before和指向后一个节点的after指针
- LinkedHashMap默认使用插入顺序进行遍历,也可以使用访问顺序,将accessOrder置为true即可
LinkedHashMap的迭代方式
- 使用keySet进行遍历,keySet返回的是一个LinkedKeySet,LinkedKeySet的遍历方式是按照插入时候的顺序
- 使用entrySet进行遍历,返回LinkedEntrySet
- 使用内部迭代forEach
public void forEach(BiConsumer<? super K, ? super V> action) { if (action == null)
throw new NullPointerException(); int mc = modCount;
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) action.accept(e.key, e.value);
if (modCount != mc)
throw new ConcurrentModificationException();
}
TreeMap
TreeMap中的元素默认按照keys的自然排序排列。(对Integer来说,其自然排序就是数字的升序;对String来说,其自然排序就是按照字母表排序)
TreeMap的定义如下:
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
TreeMap继承AbstractMap,实现NavigableMap、Cloneable、Serializable三个接口。其中AbstractMap表明TreeMap为一个Map即支持key-value的集合, NavigableMap(更多)则意味着它支持一系列的导航方法,具备针对给定搜索目标返回最接近匹配项的导航方法 。
TreeMap中同时也包含了如下几个重要的属性:
//比较器,因为TreeMap是有序的,通过comparator接口我们可以对TreeMap的内部排序进行精密的控制
private final Comparator<? super K> comparator;
//TreeMap红-黑节点,为TreeMap的内部类
private transient Entry<K,V> root = null;
//容器大小
private transient int size = 0;
//TreeMap修改次数
private transient int modCount = 0;
//红黑树的节点颜色--红色
private static final boolean RED = false;
//红黑树的节点颜色--黑色
private static final boolean BLACK = true;
对于叶子节点Entry是TreeMap的内部类,它有几个重要的属性:
//键
K key;
//值
V value;
//左孩子
Entry<K,V> left = null;
//右孩子
Entry<K,V> right = null;
//父亲
Entry<K,V> parent;
//颜色
boolean color = BLACK;
数据结构:基于红黑树的一种实现,红黑树是自平横的二叉搜索树。二叉搜索树是排序好的二叉树。
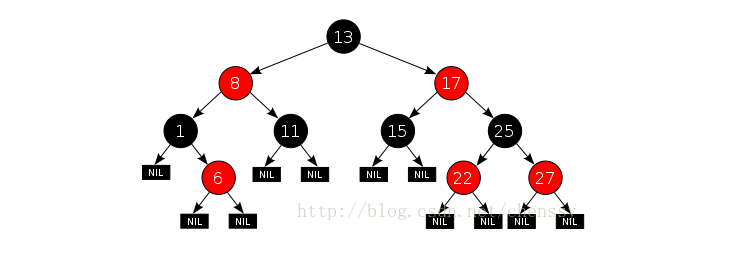
Set
Set集合存储元素的特点就是,set存储元素都是无序并且不可重复的,比较常用的两种有HashSet和TreeSet
HashSet:
HashSet的类继承关系
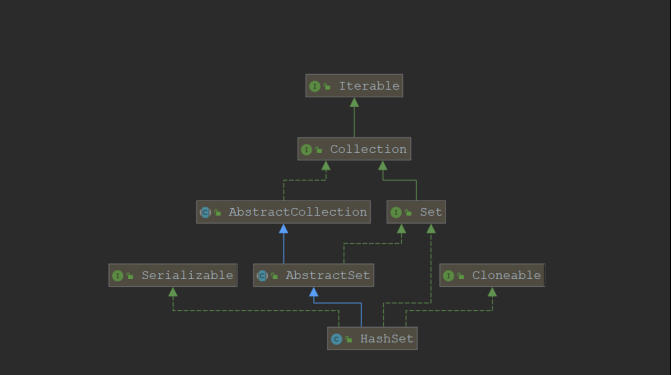
Hashset的顶级接口是Collection接口,属于单列集合,即每次存储一个元素
HashSet的数据结构
private transient HashMap<E,Object> map;// 内部维护了一个map,其底层实现靠的就是HashMap,键用于存放值 // Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();// 这个空的Object对象作为所有的默认Value /**
*Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
*default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
map = new HashMap<>();
} // add方法其实就是调用了map的put,并传入一个空的value
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
因为Set的元素和HashMap中的键是有相同的特征的,HashSet充分利用了HashMap的功能
HashSet的特点:
- 存储元素时会去重,即集合中的元素都是不可重复的
- HashSet没有get方法,其实道理也很显而易见,因为元素是无序的所以不能根据下标来访问元素
- HashSet的本质就是HashMap
HashSet的迭代方式:
- 使用迭代器进行迭代,其实本质上返回的就是HashMap的keySet
public Iterator<E> iterator() { return map.keySet().iterator();
}
- 使用forEach进行内部迭代,性能不如直接使用迭代器
set.forEach(k->System.out.println(k));
TreeSet
TreeSet是基于TreeMap实现的,TreeSet的元素支持2种排序方式:自然排序或者根据提供的Comparator进行排序。
继承关系:
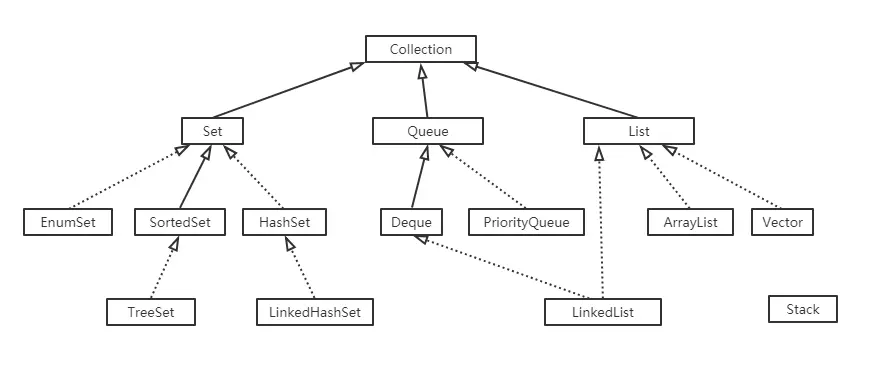
TreeSet的特点
- TreeSet中存储的元素是有序且不可重复的,所谓有序就是按照元素自身的排序顺序,或者使用者自定义比较 方式
- 和HashSet类似TreeSet的底层实现就是TreeMap
public TreeSet() {
this(new TreeMap<E,Object>());
}
java常用容器简要性能分析(List。Map。Set)的更多相关文章
- JAVA常用数据结构及原理分析
JAVA常用数据结构及原理分析 http://www.2cto.com/kf/201506/412305.html 前不久面试官让我说一下怎么理解java数据结构框架,之前也看过部分源码,balaba ...
- (6)Java数据结构-- 转:JAVA常用数据结构及原理分析
JAVA常用数据结构及原理分析 http://www.2cto.com/kf/201506/412305.html 前不久面试官让我说一下怎么理解java数据结构框架,之前也看过部分源码,balab ...
- 软件性能测试分析与调优实践之路-Java应用程序的性能分析与调优-手稿节选
Java编程语言自从诞生起,就成为了一门非常流行的编程语言,覆盖了互联网.安卓应用.后端应用.大数据等很多技术领域,因此Java应用程序的性能分析和调优也是一门非常重要的课题.Java应用程序的性能直 ...
- Java 容器源码分析之 Map
ava.util 中的集合类包含 Java 中某些最常用的类.最常用的集合类是 List 和 Map.List 的具体实现包括 ArrayList 和 Vector,它们是可变大小的列表,比较适合构建 ...
- java 常用集合list与Set、Map区别及适用场景总结
转载请备注出自于:http://blog.csdn.net/qq_22118507/article/details/51576319 list与Set.Map区别及 ...
- Java常用的几种集合, Map集合,Set集合,List集合
Java中 Object是所有类的根 Java集合常用的集合List集合.Set集合.Map集合 Map接口常用的一些方法 size() 获取集合中名值对的数量 put(key k, value v ...
- Java常用Json库性能对比
Java对于处理JSON数据的序列化与反序列化目前常用的类库有Gson.FastJSON.Jackson.jettison以及json-lib.在这里我们将对这些类库在json序列化与反序列化方面的性 ...
- Java集合--ArrayList,LinkedList性能分析
转载请注明出处:http://www.cnblogs.com/skywang12345/p/3308900.html 第1部分 List概括 先回顾一下List的框架图 (01) List 是一个接口 ...
- 几种常见 容器 比较和分析 hashmap, map, vector, list ...hash table
list支持快速的插入和删除,但是查找费时; vector支持快速的查找,但是插入费时. map查找的时间复杂度是对数的,这几乎是最快的,hash也是对数的. 如果我自己写,我也会用二叉检索树,它在 ...
随机推荐
- Python 列表[::-1]翻转
b = a[i:j:s]: i为起始索引(缺省为0), j为结束索引(不包括,缺省为len(a)), s为步进(缺省为1). 所以a[i:j:1]相当于a[i:j]. 当s<0时: i缺省时,默 ...
- http://yuedu.baidu.com/ebook/36edd3d7ba1aa8114531d911
本书概述: 全面深入自动化测试技术,包括接口自动化测试.app自动化测试.性能自动化测试技术:实践,理论结合,方案,环境,代码 java语言,python语言,自动化测试开发 ...
- 码海拾遗:Linux多线程mutex锁
多线程计数,每个线程累加10个数. 实现: #include <stdio.h> #include <stdlib.h> #include <string.h> # ...
- OpenGL Panorama Player
JMGL_PANO star_war_eve source 1 star_war_eve source 2 1. 介绍 JMGL_PANO 是Justin开源的一个全景视频播放器(Github).基于 ...
- 服务治理与RPC · 跬步
以前写过Django中使用zerorpc的方法,但是由于我们的Django是运行在gevent下,而zeromq需要启动一个后台进程处理消息,与gevent使用的greenlet携程是冲突的. 在Ja ...
- Haproxy的应用
如上图所示,在 192.168.1.0/24 这个网段的客户端想要访问在 172.20.0.0/20 网段内的服务器,所有的通信又不想暴露在互联网上,因此可以在这两个网段内分别都放一台 Haproxy ...
- 用java实现的微信公众号爬虫
Published: 2016-11-23 In Spider. tags: Spider 版权声明:本文为博主原创文章,未经博主允许不得转载. 思路: 直接从chuansong.me爬取,由于微信公 ...
- 【原创】从零开始搭建Electron+Vue+Webpack项目框架(五)预加载和Electron自动更新
导航: (一)Electron跑起来(二)从零搭建Vue全家桶+webpack项目框架(三)Electron+Vue+Webpack,联合调试整个项目(四)Electron配置润色(五)预加载及自动更 ...
- Mysql5.7.25安装步骤
安装步骤 在官网下载mysql-5.7.25-winx64.zip压缩包到本地,解压到非中文目录. 列如(D:\Program Files\mysql-5.7.25-winx64). 在环境变量中添加 ...
- cocoapods iOS类库管理工具的安装与使用
CocoaPods是一个管理Swift和Objective-C的Cocoa项目的依赖工具.他可以优雅地帮助你扩展你的项目.简单的说,就是替你管理Swift和Objective-C的Cocoa项目的第三 ...