给社团同学做的R语言爬虫分享
大家好,给大家做一个关于R语言爬虫的分享,很荣幸也有些惭愧,因为我是一个编程菜鸟,社团里有很多优秀的同学经验比我要丰富的多,这次分享是很初级的,适用于没有接触过爬虫且有一些编程基础的同学,内容主要有以下几个方面:背景知识,爬取方法,数据处理和存储以及我学习编程以来的经验和教训。

背景知识一:爬虫是什么
很简单,就是写一套程序,把自己伪装成一个浏览器不断地访问目标网站,批量下载下来上面的信息。

这张图是来自人民大学新闻系的官方公众号-RUC新闻坊,他们就是通过爬虫获取了信息,这些信息经过加工分析后就有了更大的价值。不过爬虫有难有易,有的网页专门开辟API接口直接为你提供你需要的信息,比如图片里的清博大数据;有的网页没有,比如图片里的链家,需要你费很大功夫把真正包含你需要的信息的网页找到。之后我会介绍如何应对这两种情况。
我们首先应对较难的情况,就是没有提供API接口的。我以链接为例,我们的目标就是爬下小区的经纬度。这个是访问链家小区的基本步骤

在正式爬虫之前还要了解一些关于网页的基本知识,幸运的是简单的爬虫不太需要掌握复杂的网页知识。网页由信息组成,大家只要知道我们需要从哪里找到我们要的信息以及这些信息是什么格式即可。
关于第一个问题:我们要的信息在哪里,我以链家网站为例
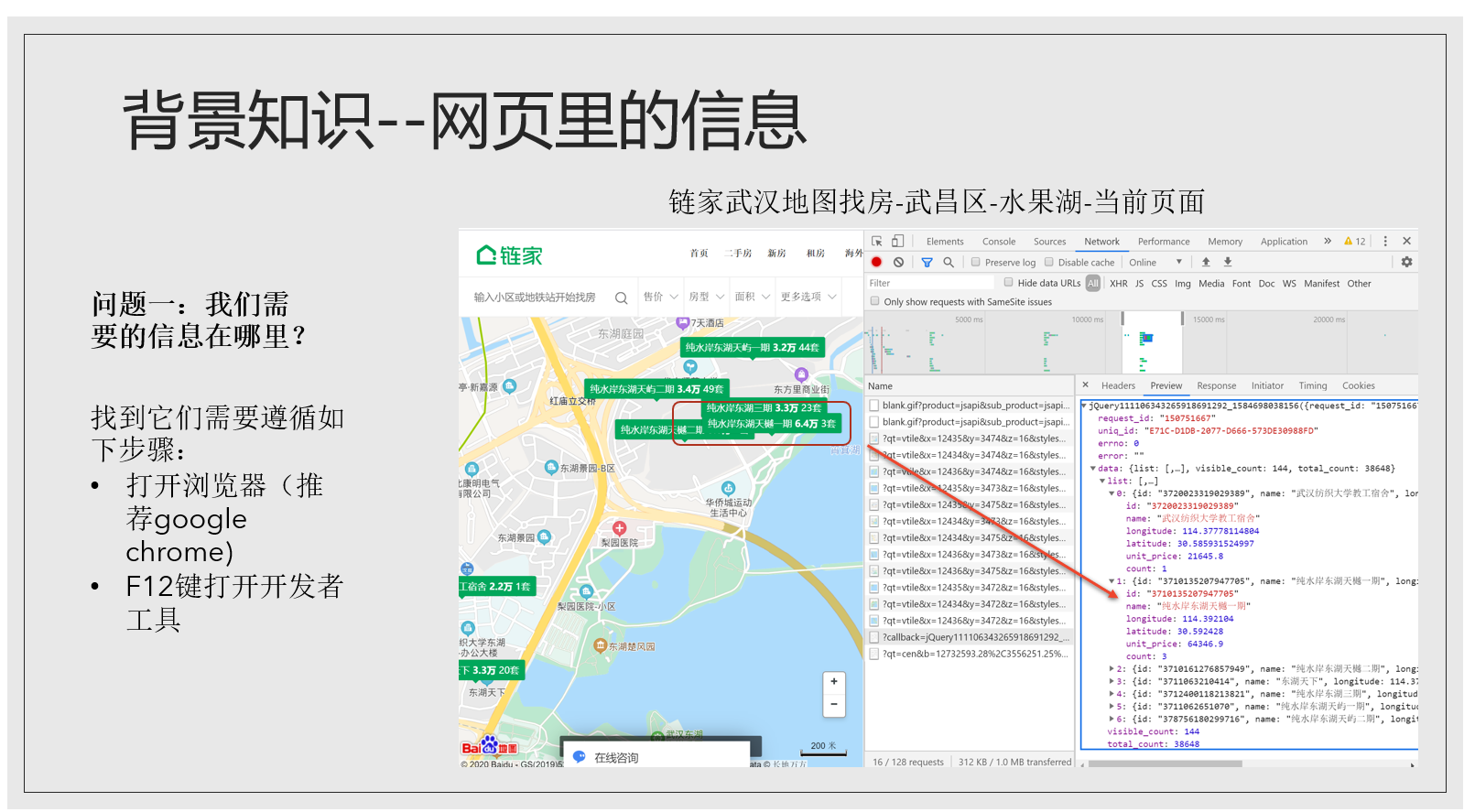
我把截图放大并标记了5个重要的位置:
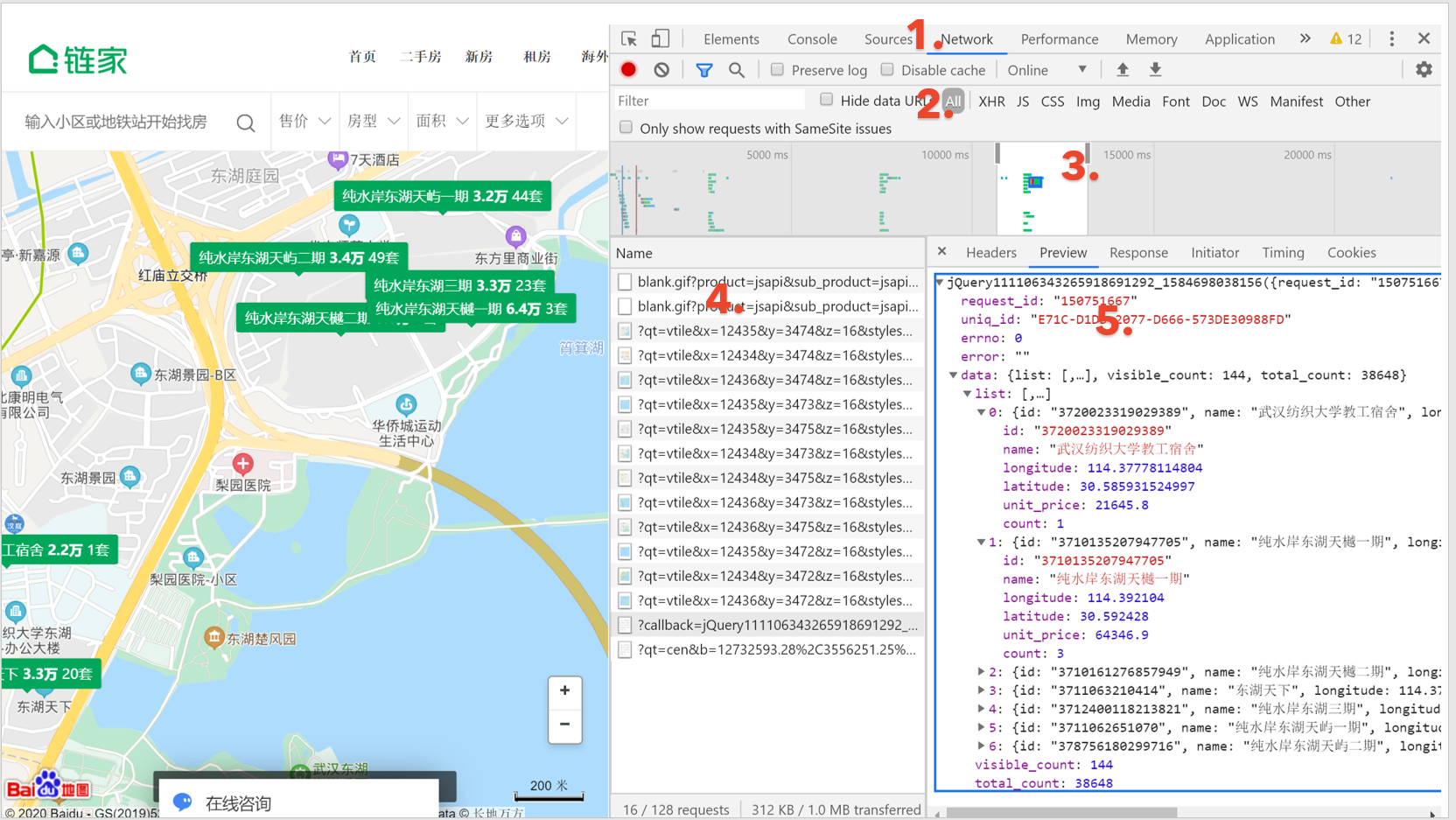
开发者工具的顶部有一些标签,1这里标记的network标签对于爬虫来说是最重要的,其它像Elements,Console等我们不太需要去看。2这里标记的是网页的数据格式标签。我这张图选的是ALL,就是包括所有的文件格式。我爬过的网站中XHR,JS,DOC格式的文件比较多。 3这里是时间轴,你的每一次点击都会显示在时间轴上,比如链家的地图有放缩的功能,每次放缩会出现新的小区信息。当你只需要某一次放缩出现的信息时,时间轴就派上用场,你可以选定那次放缩对应的时间区域,就像我图中显示的那样只有中间这一小部分时间段内的信息会出现在4所标记的信息栏里面。所以4也就顺便介绍了,可以看到4的区域里有很多文件,名字都很长,有qt开头的,也有callback开头的,这里我们需要的小区信息在callback开头的文件里。5就是文件所包含信息的展示区域。图片里选中了preview标签,也就是预览的意思,我们在这里预览了文件里的信息。
到此为止我们就回答了第一个问题:信息在哪里
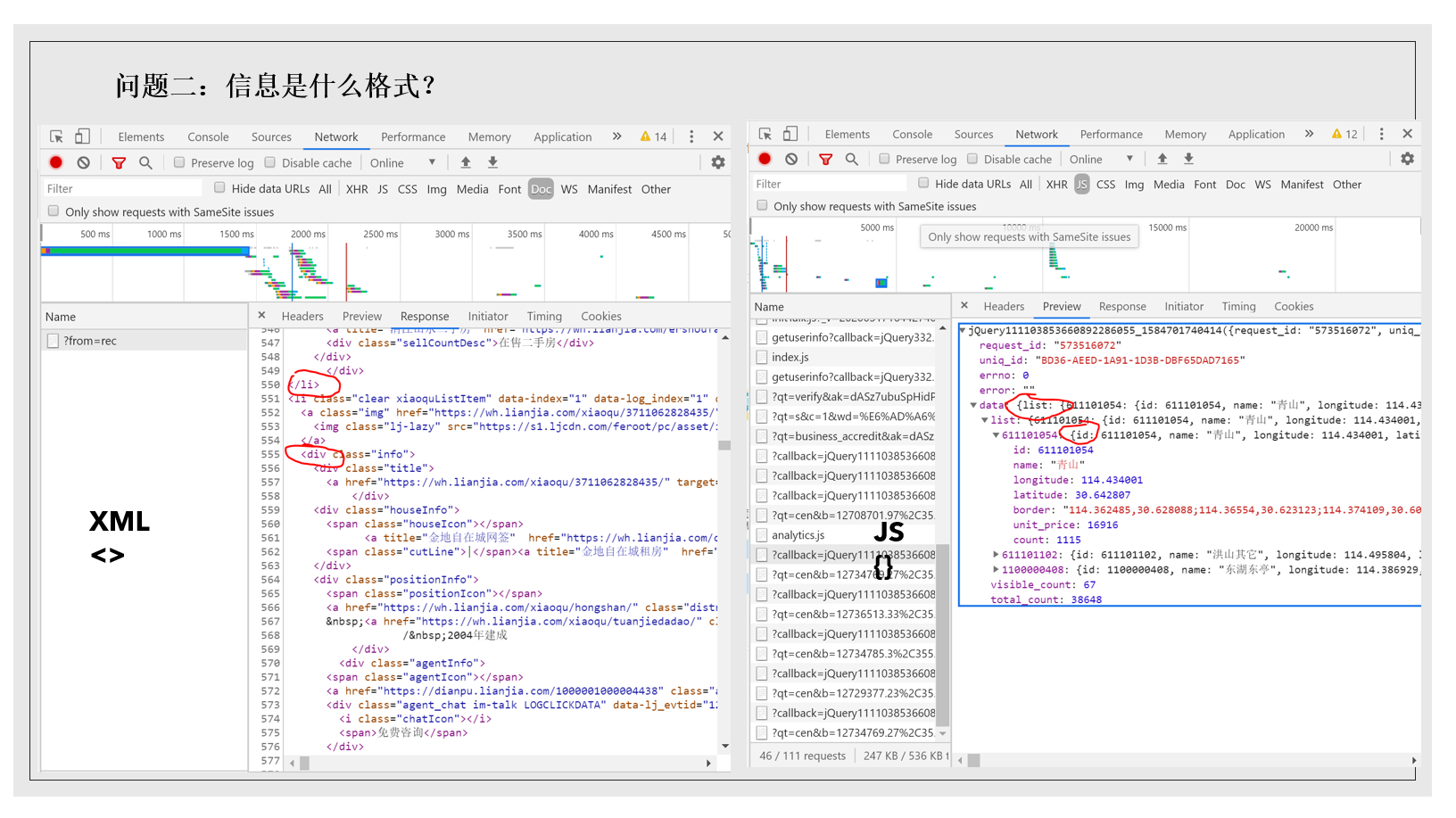
第二个问题是信息的格式。
为什么信息的格式这么重要?因为格式决定了我们处理它们的方式。有两个格式很重要:XML和JSON,下面两张图左边是XML格式,右边是JSON格式,XML呈现阶梯状,用尖括号包起来,JSON则是以花括号为标志。
背景知识讲完就开始爬虫了。大家有的用python有的用R,R爬虫需要加载程序包,常用的有Rcurl,httr,rvest,rjson等,python我知道beautifulsoup比较有名。两种编程语言在函数语法上有区别,但爬虫的思路框架是一样的,我以R和刚才的链家网站为例。我们的目标是爬取武汉小区的经纬度。爬虫第一步是伪装成浏览器,我们在访问链家网站时首先要输入网址,然后点击地图找房-武昌区-再到武昌区里的水果湖板块,才能看到这个板块里的所有小区,如果通过程序的话,可以直接进入小区的界面,但前提是找到小区界面所在的网址,它和浏览器地址栏里的大网址已经不一样了。在前面我们找到了小区信息所在的文件,所以关键就是找到这个文件所在的网址。大家看到这时ppt上的这张图的network标签已经切换成headers标签,headers标签里就有这个callback文件的网址。

下面是伪装成浏览器部分的代码。
getURL就是请求网页信息的函数,它使用了我们上面提供的URL和request headers获取了callback文件里的小区信息并把它传递到webpage这个变量中。

这就是webpage里的信息,非常眼花缭乱,可以看到我们要的经纬度、小区名都在里面,我们想把它整理成清晰的形式,就像下面这个二维表。怎么做?

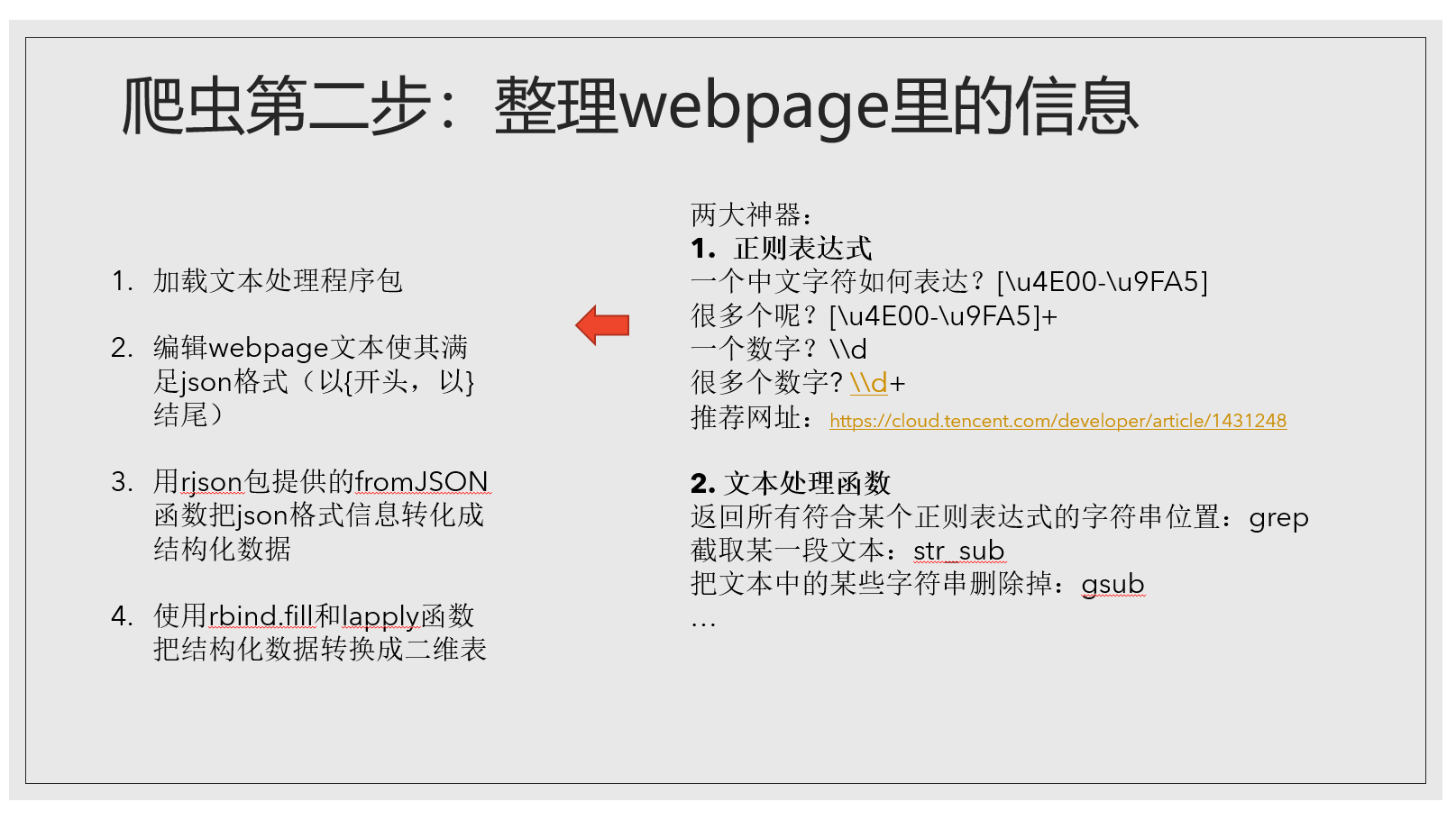
这里文本处理程序闪亮登场!
文本处理里大家需要了解正则表达式和一些基本的文本处理函数。学习R语言的文本处理强烈推荐这个网址的文章,讲得很清晰。我只列举了几个正则表达式和函数,如果大家感兴趣想多了解一些可以看那个文章。整理webpage信息的步骤我列举了出来…
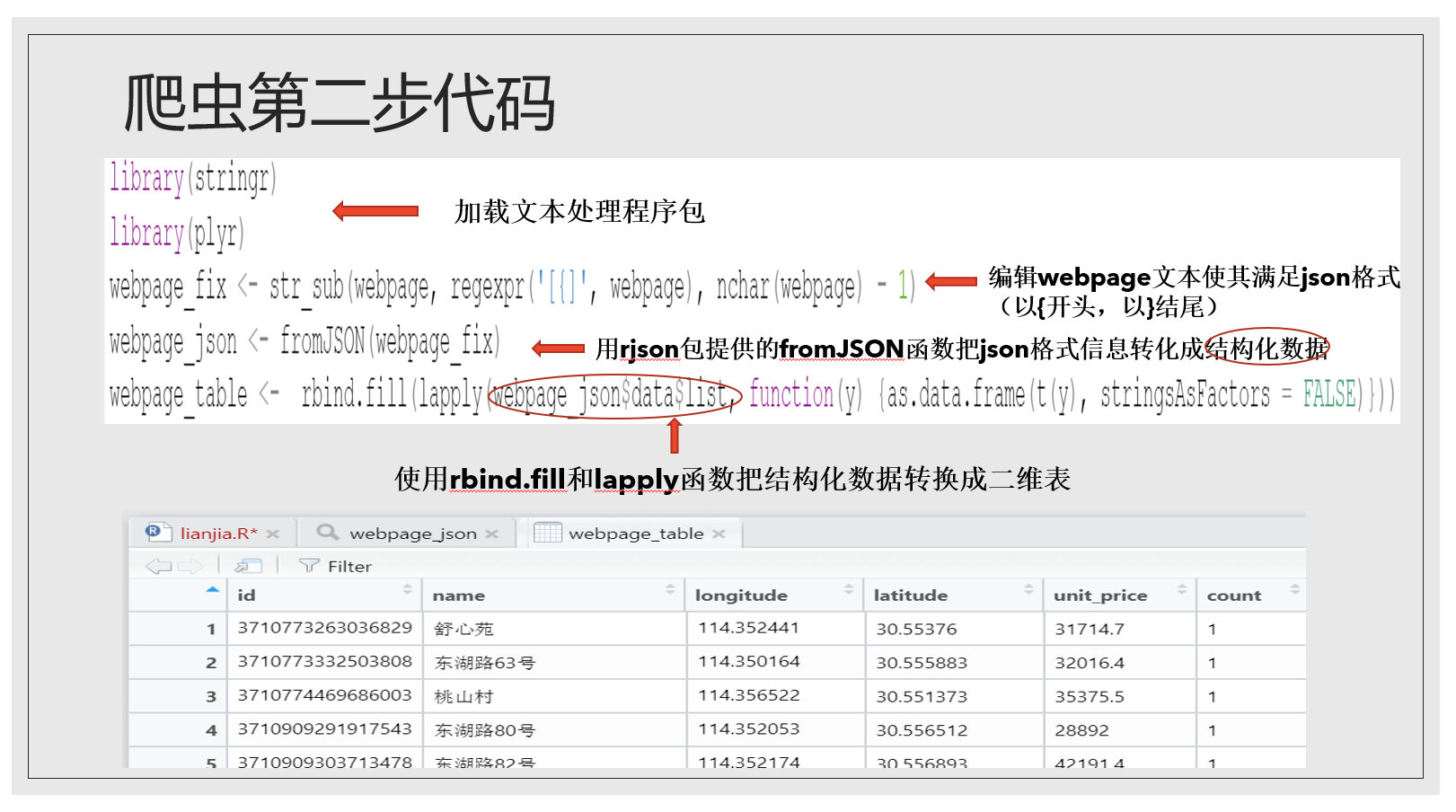
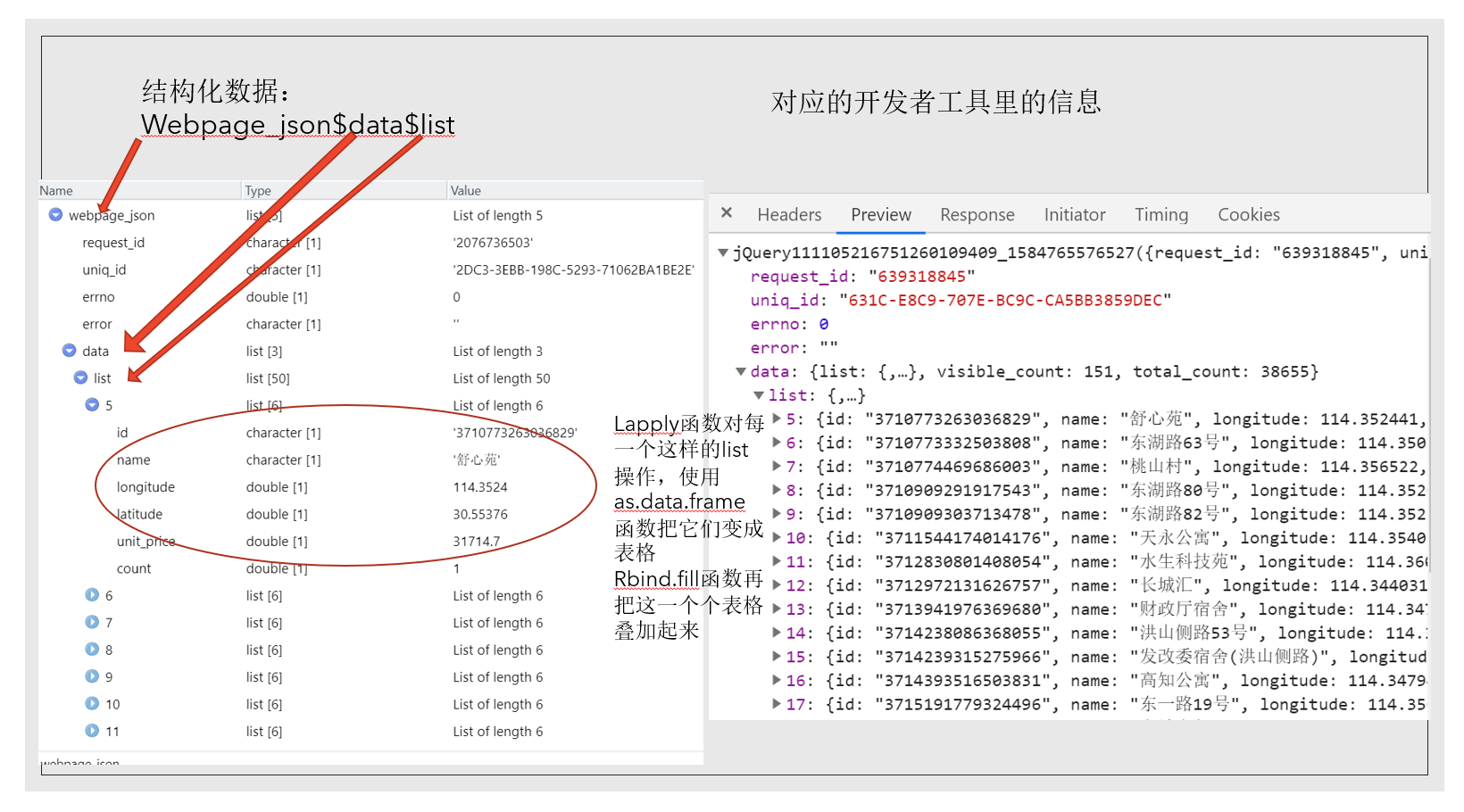
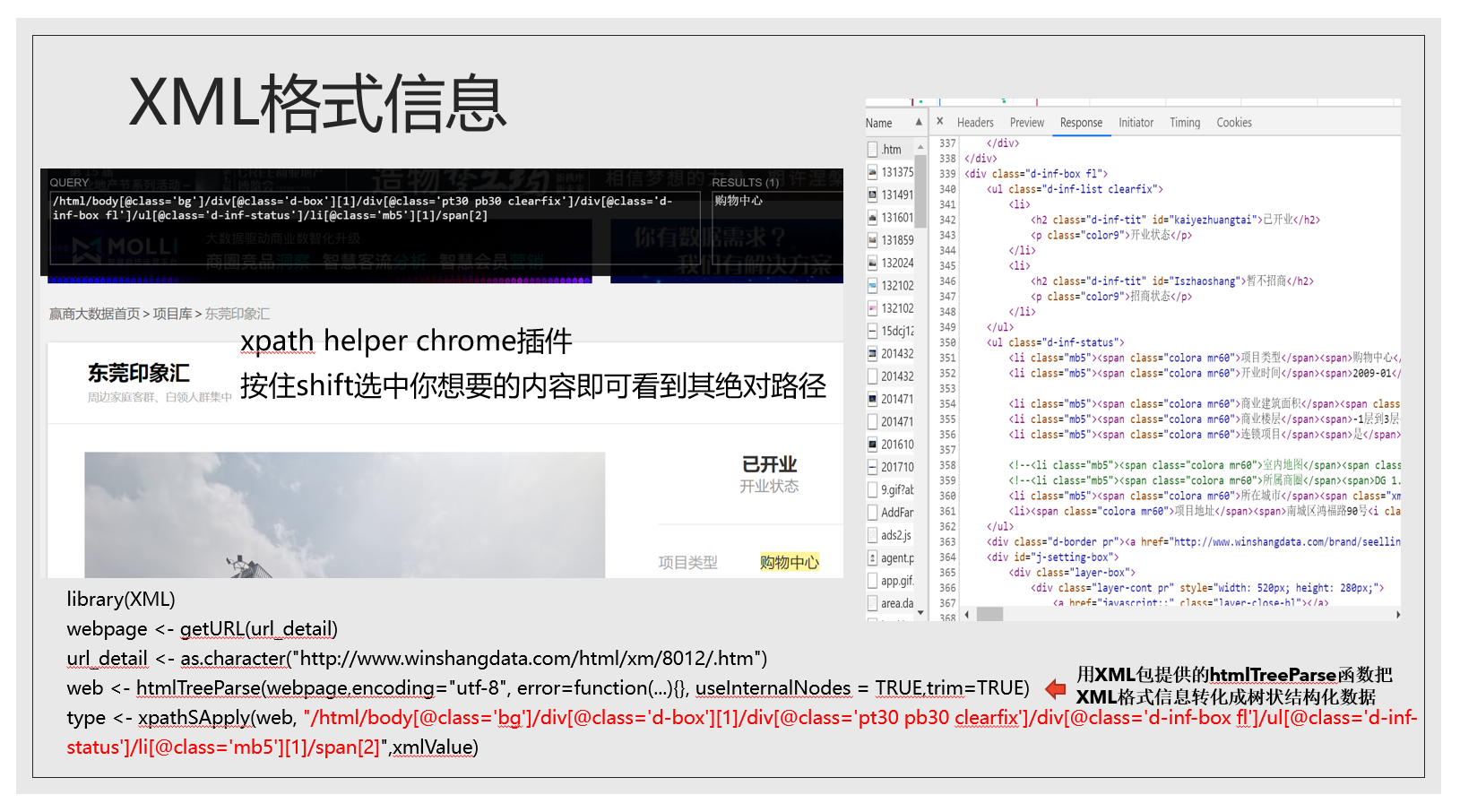
到此为止我们已经爬取下来武昌区水果湖板块的部分小区信息,链家的例子就暂且讲解到这里。目前我们只将了使用GET方式处理JSON格式信息的情况,但还有post方式和XML格式信息的情况没有讲,我这里只把部分代码放在这里,感兴趣的同学可以了解一下。
下面再看API的例子,许多个人、政府机构等都为新冠肺炎开发了API数据接口,政府如山东省、贵州省都有数据开放平台,还有之前的清博大数据都是需要注册账号申请接入的,比较麻烦,所以我这里就以一个个人开发的接口为例。访问这个网站,可以看到它特地标注了是GET请求,我们刚刚爬取链家数据也是get请求。
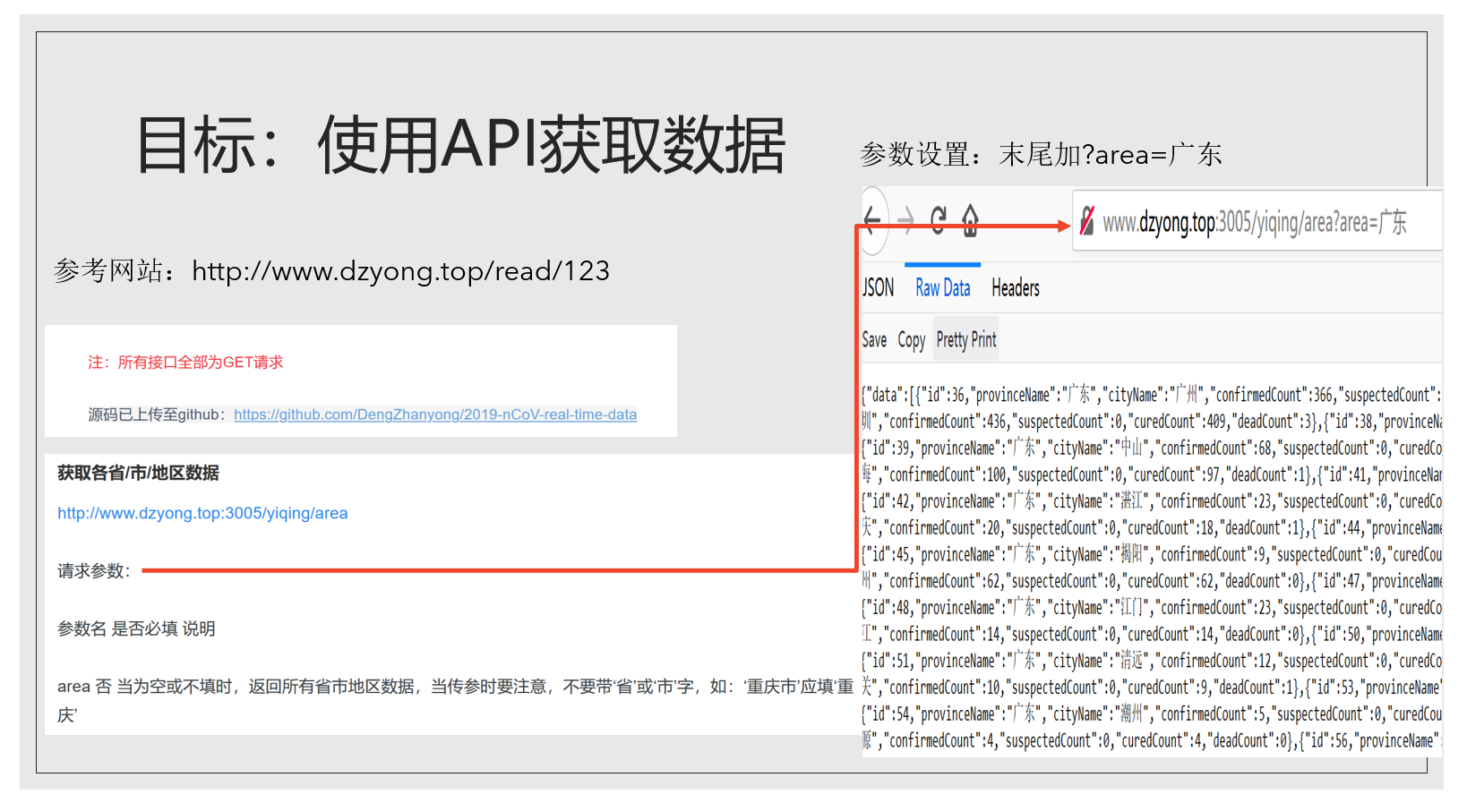
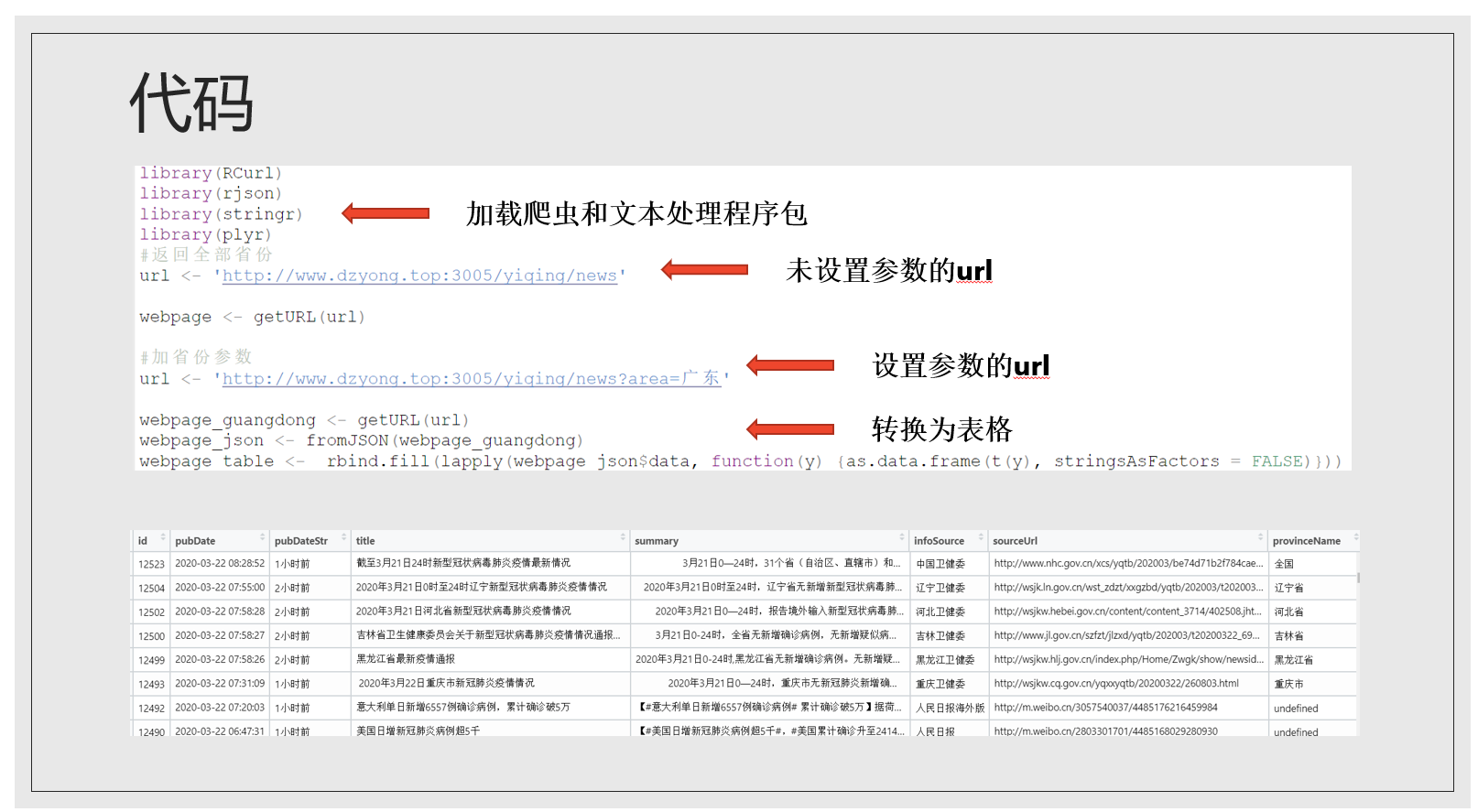
post请求和XML格式我就不细讲了。



给社团同学做的R语言爬虫分享的更多相关文章
- R语言爬虫初尝试-基于RVEST包学习
注意:这文章是2月份写的,拉勾网早改版了,代码已经失效了,大家意思意思就好,主要看代码的使用方法吧.. 最近一直在用且有维护的另一个爬虫是KINDLE 特价书爬虫,blog地址见此: http://w ...
- 简单R语言爬虫
R爬虫实验 R爬虫实验 PeRl 简单的R语言爬虫实验,因为比较懒,在处理javascript翻页上用了取巧的办法. 主要用到的网页相关的R包是: {rvest}. 其余的R包都是常用包. libra ...
- R 语言爬虫 之 cnblog博文爬取
Cnbolg Crawl a). 加载用到的R包 ##library packages needed in this case library(proto) library(gsubfn) ## Wa ...
- R语言爬虫 rvest包 html_text()-html_nodes() 原理说明
library(rvest) 例子网页:http://search.51job.com/jobsearch/search_result.php?fromJs=1&jobarea=010000% ...
- R语言爬虫:使用R语言爬取豆瓣电影数据
豆瓣排名前25电影及评价爬取 url <-'http://movie.douban.com/top250?format=text' # 获取网页原代码,以行的形式存放在web 变量中 web & ...
- R语言爬虫:穿越表单
使用rvest包实现实现穿越表单以及页面的跳转 formurl <- "http://open.xmu.edu.cn/oauth2/authorize?client_id=1010&a ...
- R语言爬虫:爬取百度百科词条
抓取目标:抓取花儿与少年的百度百科中成员信息 url <- "http://baike.baidu.com/item/%E8%8A%B1%E5%84%BF%E4%B8%8E%E5%B0 ...
- R语言爬虫:爬取包含所有R包的名称及介绍
第一种方法 library("rvest") page <- read_html("https://cran.rstudio.com/web/packages/av ...
- R语言爬虫:CSS方法与XPath方法对比(表格介绍)
css 选择器与 xpath 用法对比 目标 匹配节点 CSS 3 XPath 所有节点 ~ * //* 查找一级.二级.三级标题节点 <h1>,<h2>,<h3> ...
随机推荐
- Leetcode 239题 滑动窗口最大值(Sliding Window Maximum) Java语言求解
题目链接 https://leetcode-cn.com/problems/sliding-window-maximum/ 题目内容 给定一个数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧 ...
- C++扬帆远航——3(打印图形)
/* * Copyright (c) 2016,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名:tuxing.cpp * 作者:常轩 * 完成日期:2016年3 ...
- Spring AOP使用方式
AOP:全称是Aspect Oriented Programming,面向切面编程 Spring AOP的作用和优势: 作用:在程序运行期间,不修改源码对已有方法进行增强 优势:减少重复代码:提高开发 ...
- linux安装国产数据库(金仓数据库,达梦数据库,南大通用数据库)
今天在公司做的任务是,在Linux的环境下安装三种数据库,结果一种数据库也没有安装好,首先遇到的问题是安装南大通用数据库遇到安装的第五步,就出现问题了,问题是Gbase SDK没有安装成功,以及Gba ...
- 从头解决PKIX path building failed
从头解决PKIX path building failed的问题 本篇涉及到PKIX path building failed的原因和解决办法(包括暂时解决和长效解决的方法),也包括HTTP和HTTP ...
- node.js-web服务器
node.js--web服务器 目前最主流的三个Web服务器是Apache.Nginx.IIS. 使用 Node 创建 Web 服务器 以下是演示一个最基本的 HTTP 服务器架构(使用8081端口) ...
- 学h5前端开发前必知的三大流行趋势
学h5前端开发前必知的三大流行趋势 随着互联网时代的飞速发展,各种互联网的Web应用程序层出不穷,很多人对于HTML5前端开发的过程充满了好奇,但是却没有了解到前端开发的未来发展趋势.下面,云慧学院专 ...
- python之路-基本数据类型之list列表
1.概述 列表是python的基本数据类型之一,是一个可变的数据类型,用[]方括号表示,每一项元素使用逗号隔开,可以装大量的数据 #先来看看list列表的源码写了什么,方法:按ctrl+鼠标左键点li ...
- 基于springcloud搭建项目-Hystrix篇(五)
1.概述 (1).首先要知道分布式系统面临的问题复杂分布式体系结构中应用程序有数十个依赖关系,每个依赖关系在某些时候将不可避免的失败 (2).服务雪崩 多个服务之间相互调用的时候,假设微服务A调用微服 ...
- 小程序的数据存储,与Django等服务发送请求
目录 官方文档 快速归纳 存取改删 1.wx存储数据到本地以及本地获取数 1.1 wx.setStorageSync(string key, any data) 存(同步) 1.2 wx.setSto ...