python爬虫(三) 用request爬取拉勾网职位信息
request.Request类
如果想要在请求的时候添加一个请求头(增加请求头的原因是,如果不加请求头,那么在我们爬取得时候,可能会被限制),那么就必须使用request.Request类来实现,比如要增加一个User-Agent,
url='https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput='
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'
}
req=request.Request(url,headers=headers)
resp=request.urlopen(req)
print(resp.read())
这样就可以爬取下来这个网站所有得信息:
拉勾网得反爬虫设计的非常好,在我们现在打开的页面:
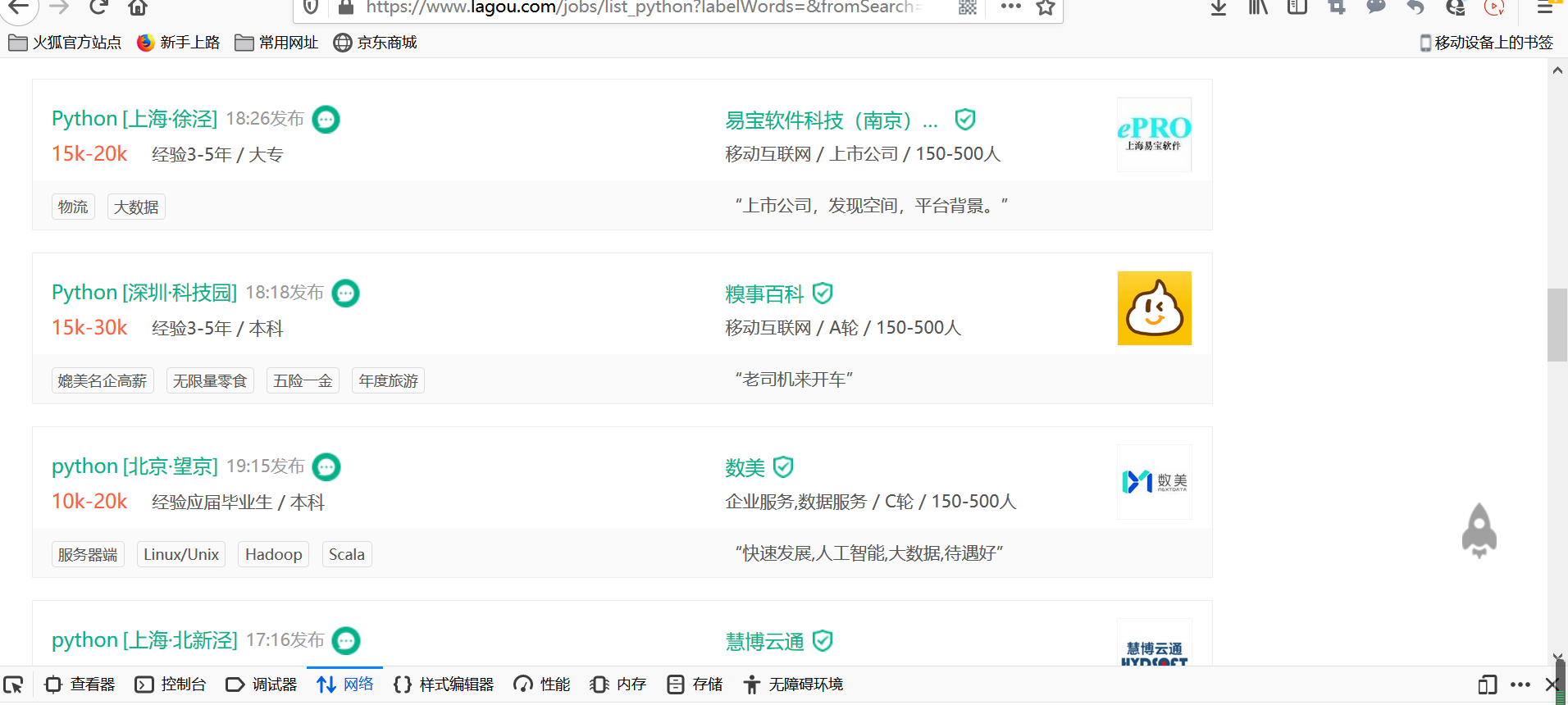
我们刚刚爬取得只是这个页面得信息,里面得职位信息是没有得,这些职位信息在另外得一个jsp里,通过调用得形式在这个页面显示出来
我们获取职位信息得网址
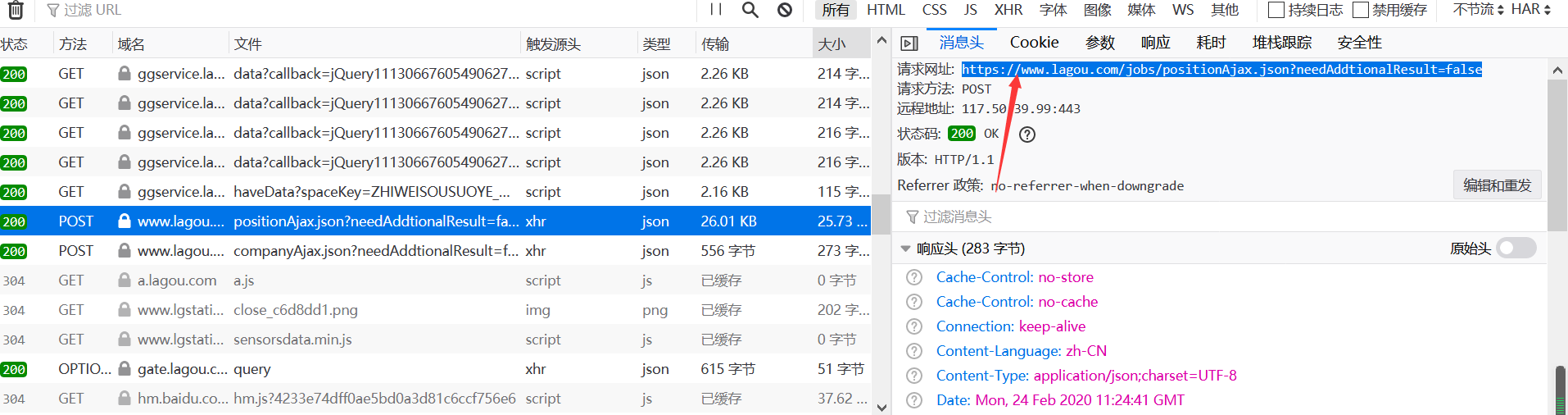

请求方法为POST;
url='https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'
}
data ={
'first':'true',
'pn':1,
'kd':'python'
}
req=request.Request(url,headers=headers,data=data,method='POST')
resp=request.urlopen(req)
print(resp.read())
结果为:

报错得原因是data也需要urlencode来传,同时也要是bytes得形式(encode('utf-8'))
还需要对请求头再次进行伪装,此时得请求头为:
headers = { 'Accept': 'application/json, text/javascript, */*; q=0.01', 'Referer': 'https://www.lagou.com/jobs/list_%E8%BF%90%E7%BB%B4?city=%E6%88%90%E9%83%BD&cl=false&fromSearch=true&labelWords=&suginput=', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'}
所以请求头就是在网站里右键,点击查看元素,然后选择网络,选择User-Agent和Referer里面得网址
url='https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
headers = { 'Accept': 'application/json, text/javascript, */*; q=0.01', 'Referer': 'https://www.lagou.com/jobs/list_%E8%BF%90%E7%BB%B4?city=%E6%88%90%E9%83%BD&cl=false&fromSearch=true&labelWords=&suginput=', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'}
data ={ 'first':'true', 'pn':1, 'kd':'python' } req=request.Request(url,headers=headers,data=parse.urlencode(data).encode('utf-8'),method='POST') resp=request.urlopen(req)
print(resp.read().decode('utf-8'))
这时会出现“您的操作太频繁,请稍后重试”的提示,是因为网站已经发现了有人正在爬取而进行的提示。
我们在代码中添加与post和相关的cookie来请求
例如:爬取成都与运维相关的工作
import requests
import time
import json
def main():
url_start = "https://www.lagou.com/jobs/list_运维?city=%E6%88%90%E9%83%BD&cl=false&fromSearch=true&labelWords=&suginput="
url_parse = "https://www.lagou.com/jobs/positionAjax.json?city=成都&needAddtionalResult=false"
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Referer': 'https://www.lagou.com/jobs/list_%E8%BF%90%E7%BB%B4?city=%E6%88%90%E9%83%BD&cl=false&fromSearch=true&labelWords=&suginput=',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
for x in range(1, 5):
data = {
'first': 'true',
'pn': str(x),
'kd': '运维'
}
s = requests.Session()
s.get(url_start, headers=headers, timeout=3) # 请求首页获取cookies
cookie = s.cookies # 为此次获取的cookies
response = s.post(url_parse, data=data, headers=headers, cookies=cookie, timeout=3) # 获取此次文本
time.sleep(5)
response.encoding = response.apparent_encoding
text = json.loads(response.text)
info = text["content"]["positionResult"]["result"]
for i in info:
print(i["companyFullName"])
companyFullName = i["companyFullName"]
print(i["positionName"])
positionName = i["positionName"]
print(i["salary"])
salary = i["salary"]
print(i["companySize"])
companySize = i["companySize"]
print(i["skillLables"])
skillLables = i["skillLables"]
print(i["createTime"])
createTime = i["createTime"]
print(i["district"])
district = i["district"]
print(i["stationname"])
stationname = i["stationname"]
if __name__ == '__main__':
main()

python爬虫(三) 用request爬取拉勾网职位信息的更多相关文章
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
- 【实战】用request爬取拉勾网职位信息
from urllib import request import urllib import ssl import json url = 'https://www.lagou.com/jobs/po ...
- node.js爬虫爬取拉勾网职位信息
简介 用node.js写了一个简单的小爬虫,用来爬取拉勾网上的招聘信息,共爬取了北京.上海.广州.深圳.杭州.西安.成都7个城市的数据,分别以前端.PHP.java.c++.python.Androi ...
- 基于selenium爬取拉勾网职位信息
1.selenium Selenium 本是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.而这一特性为爬虫开发提供了一个选择及方向,由于其本身依赖 ...
- python爬取拉勾网职位信息-python相关职位
import requestsimport mathimport pandas as pdimport timefrom lxml import etree url = 'https://www.la ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
随机推荐
- 【C语言】用函数实现两个数排序(指针作函数参数)
原理就不讲了,这里用来理解指针的使用方法 #include <stdio.h> void fun(int* a,int* b) { int t; if(*a>=*b) { t = * ...
- js和jsp中怎么去获取后台 model.addAttribute()存入的list<。。。>对象
java 后台List productionGroupList =getProductionGroupList(); model.addAttribute("productionGroupL ...
- 201771010135 杨蓉庆《面对对象程序设计(java)》第十六周学习总结
1.实验目的与要求 (1) 掌握线程概念: (2) 掌握线程创建的两种技术: (3) 理解和掌握线程的优先级属性及调度方法: (4) 掌握线程同步的概念及实现技术: 一.理论知识 ⚫ 线程的概念 (1 ...
- netty(六) buffer 源码分析
问题 : netty的 ByteBuff 和传统的ByteBuff的区别是什么? HeapByteBuf 和 DirectByteBuf 的区别 ? HeapByteBuf : 使用堆内存,缺点 ,s ...
- CentOS7中JDK的安装和配置
1.使用yum线上安装jdk 这里以jdk1.7为例进行示范,1.8同理 yum -y list java* #浏览线上所有jdk版本列表,列表太长了,会显示不全 y ...
- pycharm如何关闭虚拟环境(即取消venv命令行)
venv命令行 是虚拟环境特有, 为什么要使用虚拟环境: 在实际项目开发中,我们通常会根据自己的需求去下载各种相应的框架库,如Scrapy.Beautiful Soup等,但是可能每个项目使用的框架库 ...
- Javascript——(1)
1.Javascript有两种解释表示形式:1)在html的<header>中写<script><script/>,另一种是将另一个文件保存为xxx.js文档,然后 ...
- VBA 学习笔记 - 运算符
学习资料:https://www.yiibai.com/vba/vba_operators.html 算术运算符 加减乘除模指,这个没啥特别的. 比较运算符 和 Lua 相比,判断相等变成了一个等于号 ...
- Unity2018编辑器脚本趟坑记录
解除预制体问题:(这个例子是解除游戏中的Canvas与Asset中的预制体的关系) if( PrefabUtility.IsAnyPrefabInstanceRoot(GameObject.Find( ...
- 关闭AnyConnect登录安全警告窗口
一.问题描述:使用AnyConnect client连接时,如何关闭的安全警告窗口? 二.原因分析: AnyConnect Server(ASA)和AnyConect client(PC)上没有受 ...