sql之透视
1、透视原理:就是将查询结果进行转置
下面就举例来说明:
执行下面语句:检查是否含有表 dbo.Orders,如果有就将表删除:
if OBJECT_ID('dbo.Orders','U') is not null
drop table dbo.Orders
然后创建表dbo.Orders:
create table dbo.Orders
(
orderid int not null primary key,
empid int not null,
custid int not null,
orderdate datetime,
qty int
)
批量插入数据:
insert into dbo.Orders (orderid,orderdate,empid,custid,qty) values
(30001,'',3,1,10),
(10001,'',2,1,12),
(10005,'',1,2,20),
(40001,'',2,3,40),
(20001,'',2,2,12),
(10006,'',1,3,14),
(40005,'',3,1,10),
(20002,'',1,3,20),
(30003,'',2,2,15),
(30004,'',3,3,22),
(30007,'',3,4,30)
业务逻辑:查询出 每个 员工 处理的 每个客户的 订单总数
普通的查询方式:
select
empid,custid,SUM(qty) as sumqty
from Orders
group by empid,custid
order by empid
查询结果:
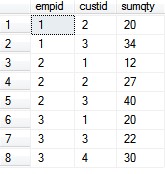
但是现在想要的结果是:
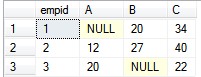
其中的A、B、C分别代表三个 客户Id,需要将原来的结果进行转置。
实现上面的结果就是sql里面的透视:
三个步骤:
1、将结果数据进行分组
2、将结果数据进行扩展
3、将结果数据进行聚合
第一种是实现方式:复杂、简单易懂的方式:使用相关子查询:
select
empid,
--下面是相关子查询,不是表的连接
(
select
SUM(qty)
from Orders as innerO
where innerO.empid=outerO.empid and custid=1
group by innerO.empid
) as A ,
(
select
SUM(qty)
from Orders as innerO
where innerO.empid=outerO.empid and custid=2
group by innerO.empid
) as B ,
(
select
SUM(qty)
from Orders as innerO
where innerO.empid=outerO.empid and custid=3
group by innerO.empid
) as C
from Orders as outerO
group by empid
第二种实现方式:使用组函数的特殊用法:
--简单方式 :使用sum()函数的特殊用法:在方法里面,添加 case语句
select
empid,
SUM(case when custid=1 then qty end) as A,--这样 将已经对empid 进行了限制
SUM(case when custid=2 then qty end) as B,
SUM(case when custid=3 then qty end) as C,
SUM(qty) as sumqty
from Orders
group by empid
第三种方式:使用pivot,是 sql server 特有的,在oracle里面没有:
select
empid,[],[],[]
from
(
--仅仅查询出 在 透视 里面需要用到的数据
select
empid,custid,qty
from Orders
) as t --在这里已经对数据 进行了分组
pivot
(
sum(qty) --聚合函数 (对那个列 执行 组函数)
for custid in ([],[],[])-- (对那些数据进行了聚合运算) 这里的数字一定要 加[]因为
) as p
这种 使用 sql server 里面内置的 pivot 的方法,肯定是比上面两种自己写的方法的效率高。
sql之透视的更多相关文章
- SQL数据透视
透视是一种通过聚合和旋转把数据行转换成数据列的技术.当透视数据时,需要确定三个要素:要在行(分组元素)中看到的元素,要在列(扩展元素)上看到的元素,要在数据部分看到的元素(聚合元素). SQL Ser ...
- SQL SERVER技术内幕之7 透视与逆透视
1.透视转换 透视数据(pivoting)是一种把数据从行的状态旋转为列的状态的处理,在这个过程中可能须要对值进行聚合. 每个透视转换将涉及三个逻辑处理阶段,每个阶段都有相关的元素:分组阶段处理相关的 ...
- [置顶] 图书推荐:SQL Server 2012 T-SQL基础 Itzik Ben-Gan
经过近三个月的不懈努力,终于翻译完毕了.图书虽然是基础知识,但是,即使你已经使用T-SQL几年,很多地方还是能够弥补你的知识空白.大师级的人物写基础知识,或许你想知道这基础中还有哪些深奥,敬请期待吧. ...
- PIVOT(透视转换)和UNPIVOT(逆透视转换)
一.原数据状态 二.手动写透视转换1 三.手动写透视转换2 四.PIVOT(透视转换)和UNPIVOT(逆透视转换)详细使用 使用标准SQL进行透视转换和逆视转换 --行列转换 create tabl ...
- 《MSSQL2008技术内幕:T-SQL语言基础》读书笔记(下)
索引: 一.SQL Server的体系结构 二.查询 三.表表达式 四.集合运算 五.透视.逆透视及分组 六.数据修改 七.事务和并发 八.可编程对象 五.透视.逆透视及分组 5.1 透视 所谓透视( ...
- 你真的会玩SQL吗?透视转换的艺术
你真的会玩SQL吗?系列目录 你真的会玩SQL吗?之逻辑查询处理阶段 你真的会玩SQL吗?和平大使 内连接.外连接 你真的会玩SQL吗?三范式.数据完整性 你真的会玩SQL吗?查询指定节点及其所有父节 ...
- SQL pivot 基本用法 行列转换 数据透视
SQL通过pivot进行行列转换 数据透视 可直接在sql server 运行 传统操作 和 pivot create table XKCl (name nchar(10) not null, 学科 ...
- 微软BI 之SSIS 系列 - 在 SQL 和 SSIS 中实现行转列的 PIVOT 透视操作
开篇介绍 记得笔者在 2006年左右刚开始学习 SQL Server 2000 的时候,遇到一个面试题就是行转列,列转行的操作,当时写了很长时间的 SQL 语句最终还是以失败而告终.后来即使能写出来, ...
- 通过sql做数据透视表,数据库表行列转换(pivot和Unpivot用法)(一)
在mssql中大家都知道可以使用pivot来统计数据,实现像excel的透视表功能 一.MSsqlserver中我们通常的用法 1.Sqlserver数据库测试 ---创建测试表 Create tab ...
随机推荐
- [改善Java代码]建议40:匿名类的构造函数很特殊
建议40: 匿名类的构造函数很特殊 在上一个建议中我们讲到匿名类虽然没有名字,但可以有一个初始化块来充当构造函数,那这个构造函数是否就和普通的构造函数完全一样呢?我们来看一个例子,设计一个计算器,进行 ...
- Linux 命令 - service: 系统服务管理
命令格式 service SCRIPT COMMAND [OPTIONS] service --status-all service --help | -h | --version 实例 a) 查看 ...
- Git CMD - push: Update remote refs along with associated objects
命令格式 git push [--all | --mirror | --tags] [--follow-tags] [--atomic] [-n | --dry-run] [--receive-pac ...
- HDOJ2000ASCII码排序
ASCII码排序 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Su ...
- 实例介绍Cocos2d-x物理引擎:HelloPhysicsWorld
我们通过一个实例介绍一下,在Cocos2d-x 3.x中使用物理引擎的开发过程,熟悉这些API的使用.这个实例的运行后的场景,当场景启动后,玩家可以触摸点击屏幕,每次触摸时候,就会在触摸点生成一个新的 ...
- ios开发:OC对象的内存分析
最近要开始准备找实习单位了,做做笔试题,看看各位大神的面试经历,发现自己要学习的东西真的还有很多,虽然也做过几个的项目,但是真正拿过笔试题一看,才发现自己对基础这方面的东西,确实有点忽视了,所以最近开 ...
- OC3-父类指针指向子类对象
// // Cat.h // OC3-父类指针指向子类对象 // // Created by qianfeng on 15/6/17. // Copyright (c) 2015年 qianfeng. ...
- WINDOWS2008 设置FTP防火墙规则
在防火墙入站规划这里,加上21.20两个端口. 然后重启ftp服务,cmd命令:net stop ftpsvc & net start ftpsvc(重启ftp服务) 一定要重启ftp服务,不 ...
- random between [a,b]、(a,b]、[a,b)
#include <iostream> #include <ctime> #include <cstdlib> using namespace std; ; /*c ...
- OpenCV3添加滑动条和鼠标事件到图形界面
鼠标事件和滑动条控制在计算机视觉和OpenCV中非常有用,使用这些控件,用户可以直接与图形界面交互,改变输入图像或者变量的属性值. /* In this section, we are going t ...