强化学习之QLearning
注:以下第一段代码是 文章 提供的代码,但是简书的代码粘贴下来不换行,所以我在这里贴了一遍。其原理在原文中也说得很明白了。
算个旅行商问题
基本介绍
戳 代码解释与来源
代码整个计算过程使用的以下公式-QLearning
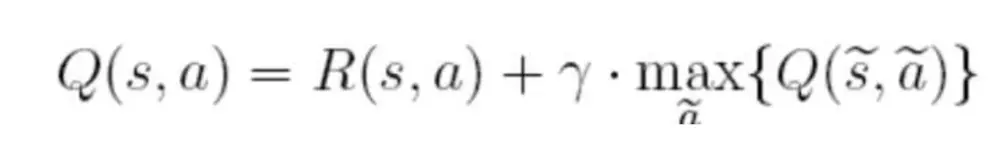
在上面的公式中,S表示当前的状态,a表示当前的动作,s表示下一个状态,a表示下一个动作,γ为贪婪因子,0<γ<1,一般设置为0.8。Q表示的是,在状态s下采取动作a能够获得的期望最大收益,R是立即获得的收益,而未来一期的收益则取决于下一阶段的动作
算法过程

面对问题
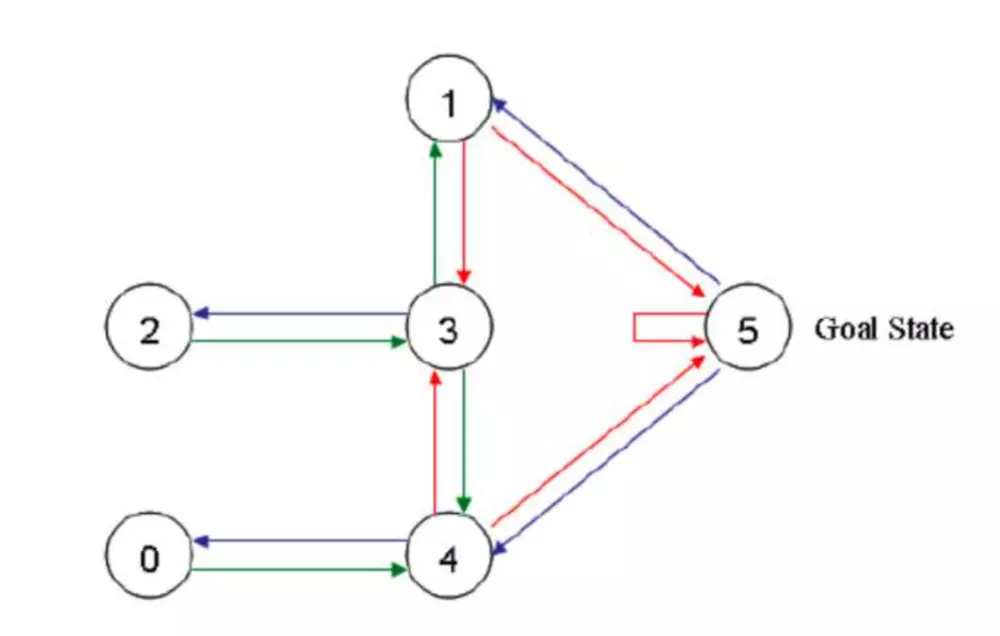
这是一个把一个代理(玩家)随机丢入一个房间,代理如何能最快速到达指定房间(在这里是5号房间) 的问题。
代码全文
import numpy as np
import random
r = np.array([[-1, -1, -1, -1, 0, -1], [-1, -1, -1, 0, -1, 100], [-1, -1, -1, 0, -1, -1], [-1, 0, 0, -1, 0, -1], [0, -1, -1, 0, -1, 100], [-1, 0, -1, -1, 0, 100]])
q = np.zeros([6,6],dtype=np.float32)
gamma = 0.8
step = 0
for step in range(100):
print("step:", step)
state = random.randint(0,5)
if state != 5:
next_state_list=[]
for i in range(6):
if r[state,i] != -1:
next_state_list.append(i)
next_state = next_state_list[random.randint(0,len(next_state_list)-1)]
qval = r[state,next_state] + gamma * max(q[next_state])
q[state,next_state] = qval
print(q)
for i in range(10):
print("第{}次验证".format(i + 1))
state = random.randint(0, 5)
print('机器人处于{}'.format(state))
count = 0
while state != 5:
if count > 20:
print('fail')
break
q_max = q[state].max()
q_max_action = []
for action in range(6):
if q[state, action] == q_max:
q_max_action.append(action)
next_state = q_max_action[random.randint(0, len(q_max_action) - 1)]
print("the robot goes to " + str(next_state) + '.')
state = next_state
count += 1
关于视频教程
视频教程中的demo实现没有看懂,然后我就按照上述文章的思路实现了视频中demo的基本功能。还不算完善,完善之后再追加。
简述:视频中demo的功能是实现一个单项运动,从1走到6就算成功。但是机器本身不知道应该按照什么样的方式走,应该加或者减,通过多次强化学习之后,可以通过回报表(Q表)知道自己应该一路加上去,从1加到6.
代码
import numpy as np
import random
r = np.array([[-1, 0, -1, -1, -1, -1], [0, -1, 0, -1, -1, -1], [-1, 0, -1,0, -1, -1], [-1, -1, 0, -1,0, -1], [-1, -1, -1, 0, -1, 100], [-1, -1,-1, -1, 0, 100 ]])
#能走的标记为0,不能走的方向标记为-1,到达终点标记为100
#因为是从1走到6一字排开,所以1能到2,2能到1,1不能到3酱紫
q = np.zeros([6,6],dtype=np.float32)
gamma = 0.8
#贪婪因子
step = 0
for step in range(10):
state = 0
time = 0
while state != 5:
time =time + 1
next_state_list=[]
for i in range(6):
if r[state,i] != -1:
next_state_list.append(i)
next_state = next_state_list[random.randint(0,len(next_state_list)-1)]
qval = r[state,next_state] + gamma * max(q[next_state])
q[state,next_state] = qval
state = next_state
############################我是分割线##########################
print(q)#打印Q表
state = 0
while state != 5:
next_state = q[state].argmax(axis = 0)#取得Q表当前行最大值的索引
print(next_state)
state = next_state
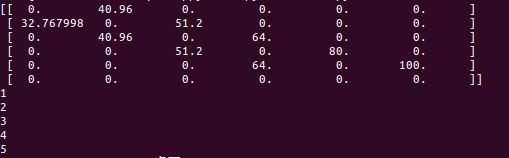
打印结果
解释
分割线之上通过强化学习(QLearning)得到Q表
分割线之下是通过Q表得到路线图(即一路上加)
打印结果表示下一步到哪 。初始在位置0,然后依次顺序打印应该到哪个位置。
总结
神经网络适合拟合、图像视频识别与分类能,强化学习适合做类似于阿尔法狗/走迷宫酱紫的智能活动
参考
文章:
https://www.itcodemonkey.com/article/3646.html
https://www.jianshu.com/p/29db50000e3f?utm_medium=hao.caibaojian.com&utm_source=hao.caibaojian.com
视频:
https://www.bilibili.com/video/av16921335/?p=6 对应代码
强化学习之QLearning的更多相关文章
- 强化学习之Q-learning ^_^
许久没有更新重新拾起,献于小白 这次介绍的是强化学习 Q-learning,Q-learning也是离线学习的一种 关于Q-learning的算法详情看 传送门 下文中我们会用openai gym来做 ...
- 强化学习之Q-learning简介
https://blog.csdn.net/Young_Gy/article/details/73485518 强化学习在alphago中大放异彩,本文将简要介绍强化学习的一种q-learning.先 ...
- 强化学习Q-Learning算法详解
python风控评分卡建模和风控常识(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005214003&am ...
- 基于Keras的OpenAI-gym强化学习的车杆/FlappyBird游戏
强化学习 课程:Q-Learning强化学习(李宏毅).深度强化学习 强化学习是一种允许你创造能从环境中交互学习的AI Agent的机器学习算法,其通过试错来学习.如上图所示,大脑代表AI Agent ...
- 深度强化学习(DRL)专栏(一)
目录: 1. 引言 专栏知识结构 从AlphaGo看深度强化学习 2. 强化学习基础知识 强化学习问题 马尔科夫决策过程 最优价值函数和贝尔曼方程 3. 有模型的强化学习方法 价值迭代 策略迭代 4. ...
- 深度强化学习(DRL)专栏开篇
2015年,DeepMind团队在Nature杂志上发表了一篇文章名为"Human-level control through deep reinforcement learning&quo ...
- (译) 强化学习 第一部分:Q-Learning 以及相关探索
(译) 强化学习 第一部分:Q-Learning 以及相关探索 Q-Learning review: Q-Learning 的基础要点是:有一个关于环境状态S的表达式,这些状态中可能的动作 a,然后你 ...
- 强化学习 - Q-learning Sarsa 和 DQN 的理解
本文用于基本入门理解. 强化学习的基本理论 : R, S, A 这些就不说了. 先设想两个场景: 一. 1个 5x5 的 格子图, 里面有一个目标点, 2个死亡点二. 一个迷宫, 一个出发点, ...
- 强化学习(九)Deep Q-Learning进阶之Nature DQN
在强化学习(八)价值函数的近似表示与Deep Q-Learning中,我们讲到了Deep Q-Learning(NIPS 2013)的算法和代码,在这个算法基础上,有很多Deep Q-Learning ...
随机推荐
- linux 学习第十六天(Samba配置)
Samba 服务 yum install samba mv smb.conf smb.conf.bak cat smb.conf.bak | grep -v "#" | grep ...
- jQuery|简单tab栏切换
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 如何使用gitbash 把你的代码托管到github
1.如果你没有创建仓库 mkdir vuex-playList cd vuex-playList git init touch README.md git add README.md git comm ...
- 解决「matplotlib 图例中文乱码」问题
在学习用 matplotlib 画图时遇到了中文显示乱码的问题,在网上找了很多需要修改配置的方法,个人还是喜欢在代码里修改. 解决方法如下: 在第2.3行代码中加上所示代码即可. import mat ...
- 直流电机驱动,TIMER口配置
电机的电压输出能力和频率有关??? 修改前:------------------------------------------------------------------------------ ...
- 20155203 2016-2017-2《Java程序设计》课程总结
目录 一.每周作业链接汇总 自认为写得最好一篇博客是?为什么? 作业中阅读量最高的一篇博客是?谈谈经验 作业中与师生交互最多的一篇博客是?谈谈收获 二.实验报告链接汇总 三.代码托管链接 四.课堂项目 ...
- 20155220 2016-2017-2 《Java程序设计》第10周学习总结
20155220 2016-2017-2 <Java程序设计>第10周学习总结 教材内容学习总结 计算机网络编程概述 路由器和交换机组成了核心的计算机网络,计算机只是这个网络上的节点以及控 ...
- 20155232 2016-2017-3 《Java程序设计》第3周学习总结
20155232 2016-2017-3 <Java程序设计>第3周学习总结 教材学习内容总结 第四章 认识对象 1.对象(Object):存在的具体实体,具有明确的状态和行为. 2.类( ...
- 20155302 2016-2017-2 《Java程序设计》第4周总结
20155302 2016-2017-2 <Java程序设计>第4周学习总结 教材学习内容总结 有关类的继承的理解:类实现继承的格式:class 子类名 extends 父类名 类的继承有 ...
- 20155333 2016-2017-2《Java程序设计》第二周学习总结
20155333 2016-2017-2<Java程序设计>第二周学习总结 教材学习内容总结 1. Java 类型系统:基本类型和类类型(参考类型) 2. 基本类型: 整数:short整数 ...