强化学习之QLearning
注:以下第一段代码是 文章 提供的代码,但是简书的代码粘贴下来不换行,所以我在这里贴了一遍。其原理在原文中也说得很明白了。
算个旅行商问题
基本介绍
戳 代码解释与来源
代码整个计算过程使用的以下公式-QLearning
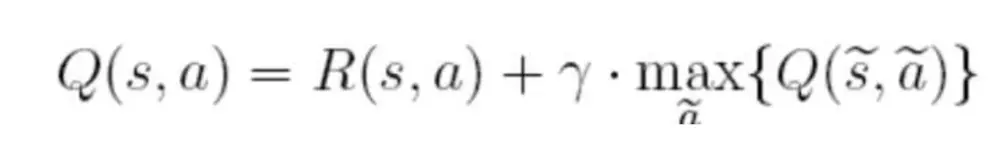
在上面的公式中,S表示当前的状态,a表示当前的动作,s表示下一个状态,a表示下一个动作,γ为贪婪因子,0<γ<1,一般设置为0.8。Q表示的是,在状态s下采取动作a能够获得的期望最大收益,R是立即获得的收益,而未来一期的收益则取决于下一阶段的动作
算法过程

面对问题
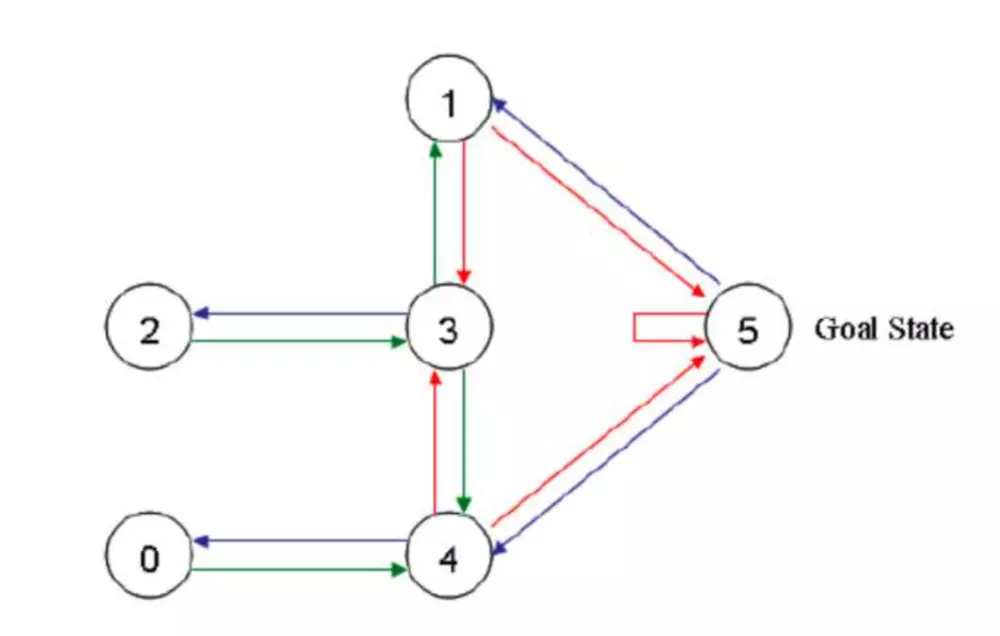
这是一个把一个代理(玩家)随机丢入一个房间,代理如何能最快速到达指定房间(在这里是5号房间) 的问题。
代码全文
import numpy as np
import random
r = np.array([[-1, -1, -1, -1, 0, -1], [-1, -1, -1, 0, -1, 100], [-1, -1, -1, 0, -1, -1], [-1, 0, 0, -1, 0, -1], [0, -1, -1, 0, -1, 100], [-1, 0, -1, -1, 0, 100]])
q = np.zeros([6,6],dtype=np.float32)
gamma = 0.8
step = 0
for step in range(100):
print("step:", step)
state = random.randint(0,5)
if state != 5:
next_state_list=[]
for i in range(6):
if r[state,i] != -1:
next_state_list.append(i)
next_state = next_state_list[random.randint(0,len(next_state_list)-1)]
qval = r[state,next_state] + gamma * max(q[next_state])
q[state,next_state] = qval
print(q)
for i in range(10):
print("第{}次验证".format(i + 1))
state = random.randint(0, 5)
print('机器人处于{}'.format(state))
count = 0
while state != 5:
if count > 20:
print('fail')
break
q_max = q[state].max()
q_max_action = []
for action in range(6):
if q[state, action] == q_max:
q_max_action.append(action)
next_state = q_max_action[random.randint(0, len(q_max_action) - 1)]
print("the robot goes to " + str(next_state) + '.')
state = next_state
count += 1
关于视频教程
视频教程中的demo实现没有看懂,然后我就按照上述文章的思路实现了视频中demo的基本功能。还不算完善,完善之后再追加。
简述:视频中demo的功能是实现一个单项运动,从1走到6就算成功。但是机器本身不知道应该按照什么样的方式走,应该加或者减,通过多次强化学习之后,可以通过回报表(Q表)知道自己应该一路加上去,从1加到6.
代码
import numpy as np
import random
r = np.array([[-1, 0, -1, -1, -1, -1], [0, -1, 0, -1, -1, -1], [-1, 0, -1,0, -1, -1], [-1, -1, 0, -1,0, -1], [-1, -1, -1, 0, -1, 100], [-1, -1,-1, -1, 0, 100 ]])
#能走的标记为0,不能走的方向标记为-1,到达终点标记为100
#因为是从1走到6一字排开,所以1能到2,2能到1,1不能到3酱紫
q = np.zeros([6,6],dtype=np.float32)
gamma = 0.8
#贪婪因子
step = 0
for step in range(10):
state = 0
time = 0
while state != 5:
time =time + 1
next_state_list=[]
for i in range(6):
if r[state,i] != -1:
next_state_list.append(i)
next_state = next_state_list[random.randint(0,len(next_state_list)-1)]
qval = r[state,next_state] + gamma * max(q[next_state])
q[state,next_state] = qval
state = next_state
############################我是分割线##########################
print(q)#打印Q表
state = 0
while state != 5:
next_state = q[state].argmax(axis = 0)#取得Q表当前行最大值的索引
print(next_state)
state = next_state
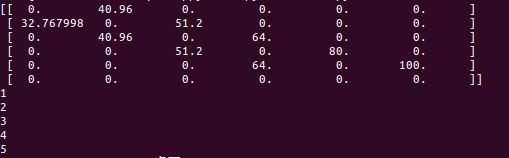
打印结果
解释
分割线之上通过强化学习(QLearning)得到Q表
分割线之下是通过Q表得到路线图(即一路上加)
打印结果表示下一步到哪 。初始在位置0,然后依次顺序打印应该到哪个位置。
总结
神经网络适合拟合、图像视频识别与分类能,强化学习适合做类似于阿尔法狗/走迷宫酱紫的智能活动
参考
文章:
https://www.itcodemonkey.com/article/3646.html
https://www.jianshu.com/p/29db50000e3f?utm_medium=hao.caibaojian.com&utm_source=hao.caibaojian.com
视频:
https://www.bilibili.com/video/av16921335/?p=6 对应代码
强化学习之QLearning的更多相关文章
- 强化学习之Q-learning ^_^
许久没有更新重新拾起,献于小白 这次介绍的是强化学习 Q-learning,Q-learning也是离线学习的一种 关于Q-learning的算法详情看 传送门 下文中我们会用openai gym来做 ...
- 强化学习之Q-learning简介
https://blog.csdn.net/Young_Gy/article/details/73485518 强化学习在alphago中大放异彩,本文将简要介绍强化学习的一种q-learning.先 ...
- 强化学习Q-Learning算法详解
python风控评分卡建模和风控常识(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005214003&am ...
- 基于Keras的OpenAI-gym强化学习的车杆/FlappyBird游戏
强化学习 课程:Q-Learning强化学习(李宏毅).深度强化学习 强化学习是一种允许你创造能从环境中交互学习的AI Agent的机器学习算法,其通过试错来学习.如上图所示,大脑代表AI Agent ...
- 深度强化学习(DRL)专栏(一)
目录: 1. 引言 专栏知识结构 从AlphaGo看深度强化学习 2. 强化学习基础知识 强化学习问题 马尔科夫决策过程 最优价值函数和贝尔曼方程 3. 有模型的强化学习方法 价值迭代 策略迭代 4. ...
- 深度强化学习(DRL)专栏开篇
2015年,DeepMind团队在Nature杂志上发表了一篇文章名为"Human-level control through deep reinforcement learning&quo ...
- (译) 强化学习 第一部分:Q-Learning 以及相关探索
(译) 强化学习 第一部分:Q-Learning 以及相关探索 Q-Learning review: Q-Learning 的基础要点是:有一个关于环境状态S的表达式,这些状态中可能的动作 a,然后你 ...
- 强化学习 - Q-learning Sarsa 和 DQN 的理解
本文用于基本入门理解. 强化学习的基本理论 : R, S, A 这些就不说了. 先设想两个场景: 一. 1个 5x5 的 格子图, 里面有一个目标点, 2个死亡点二. 一个迷宫, 一个出发点, ...
- 强化学习(九)Deep Q-Learning进阶之Nature DQN
在强化学习(八)价值函数的近似表示与Deep Q-Learning中,我们讲到了Deep Q-Learning(NIPS 2013)的算法和代码,在这个算法基础上,有很多Deep Q-Learning ...
随机推荐
- Vue 父组件调用子组件的方法
qwq 前两天看了下vue,父子组件方法的调用,怕忘记,所以做个小记录. 一.父组件调用子组件的方法 1.父组件 <template> <div id="rightmen ...
- Home Assistant系列 -- 接入手机摄像头做实时监控和人脸识别
准备一部废旧(土豪忽略,主要是穷)的.摄像头还是好的手机做监控设备,(Android 和iPhone都行)当Home Assistant 获得实时的视频流后,可以接入各种图像处理组件完成人脸识别,动作 ...
- STM32(6)——USART串口的使用
1. 串口的基本概念 在STM32的参考手册中,串口被描述成通用同步异步收发器(USART),它提供了一种灵活的方法与使用工业标准NRZ异步串行数据格式的外部设备之间进行全双工数据交换.USART利用 ...
- django定义模型类-14
目录 1. 定义 字段类型 约束类型 django的模型类定义在应用下的 models.py 文件中. 模型类继承自 django.db.models 包下的 Model 类. 新创建应用 book ...
- css position:absolute align center bottom
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- 20155315 2016-2017-2 实验二《Java面向对象程序设计》实验报告
实验内容 1.初步掌握单元测试和TDD 2.理解并掌握面向对象三要素:封装.继承.多态 3.初步掌握UML建模 4.熟悉S.O.L.I.D原则 5.了解设计模式 实验知识点 1.参考Intellj I ...
- 20155328 《Java程序设计》 实验二(Java面向对象程序设计) 实验报告
20155328 <Java程序设计> 实验二(Java面向对象程序设计) 实验报告 单元测试 一.单元测试和TDD 编程时需理清思路,将编程需求等想好,再开始编.此部分可用伪代码实现. ...
- 【转】 线段树完全版 ~by NotOnlySuccess
载自:NotOnlySuccess的博客 [完全版]线段树 很早前写的那篇线段树专辑至今一直是本博客阅读点击量最大的一片文章,当时觉得挺自豪的,还去pku打广告,但是现在我自己都不太好意思去看那篇文章 ...
- (转) 转换Drupal7模块到Drupal8
转载地址:http://verynull.com/2015/11/02/Converting-7-x-modules-to-8-x/ 本节主要介绍如何把drupal7的模块转化为drupal8.参考资 ...
- PHP5.4 连接 SQL SERVER 2008
PHP链接sqlserver需要先安装驱动,不是先把dll放到ext下面,一重启服务器就完事了. 本地环境: XAMPP 1.8.2 PHP 5.4.31 SQL SERVER 2008 R2 使用的 ...