【Python爬虫】听说你又闹书荒了?豆瓣读书9.0分书籍陪你过五一
说明
五一将至,又到了学习的季节。目前流行的各大书单主打的都是豆瓣8.0评分书籍,却很少有人来聊聊这9.0评分的书籍长什么样子。刚好最近学了学python爬虫,那就拿豆瓣读书来练练手。

爬虫
本来思路是直接爬豆瓣的书籍目录,将评分9.0以上的书筛选出来,一打开发现事情并不简单,几千万本书可不好爬 = =,于是转化一下思路,看有没有类似的书单。

一搜还真有,找到一个9.0评分的榜单,大大减少了工作量,这样就不用先爬一下整站书籍来筛选了。看了看榜单,应该是某位好心的书友手工整理的,更新时间为2018-12-25,目前一共530本,分为22页,也就是说22次访问就能搞定了,不会给豆瓣的服务器造成压力。
目标
目标URL:https://www.douban.com/doulist/1264675/?start=0&sort=seq&playable=0&sub_type=4
数据量:530
预计访问次数:22
数据存储:csv
抓取内容格式:书籍名称 作者 评分 评价人数 出版社 出版年 封面链接
代码
有了小目标,接下来就是用刚学的 python 来现学现卖了。
先来定一下步骤:
# 设置headers
# 获取代理
# 获取网页数据
# 解析书籍数据
# 存入csv文件
然后一步步来填坑即可,先来设置headers,主要是设置UA来绕过访问限制:
url = 'https://www.douban.com/doulist/1264675/?start=0&sort=seq&playable=0&sub_type=4'
logging.basicConfig(level=logging.DEBUG)
ua = UserAgent()
# 设置headers
headers = {'User-Agent': ua.random}
当然,只设置UA也没法逃过访问限制,IP限制这一关还是存在的,所以需要使用代理来绕开。

所以先来爬一爬代理的数据,弄一批能用的代理IP下来:
# 获取代理数据
def get_proxies(proxy_url, dis_url, page=10):
proxy_list = []
for i in range(1, page + 1):
tmp_ua = UserAgent()
tmp_headers = {'User-Agent': tmp_ua.random}
html_str = get_web_data(proxy_url + str(i), tmp_headers)
soup = BeautifulSoup(html_str.content, "lxml")
ips = soup.find('tbody').find_all('tr')
for ip_info in ips:
tds = ip_info.find_all('td')
ip = tds[0].get_text()
port = tds[1].get_text()
ip_str = ip + ":" + port
tmp = {"http": "http://" + ip_str}
if check_proxy(dis_url, tmp):
logging.info("ip:%s is available", ip_str)
proxy_list.append(ip_str)
time.sleep(1)
return proxy_list
# 检测代理ip是否可用
def check_proxy(url, proxy):
try:
tmp_ua = UserAgent()
tmp_headers = {'User-Agent': tmp_ua.random}
res = requests.get(url, proxies=proxy, timeout=1, headers=tmp_headers)
except:
return False
else:
return True
这里其实有两个函数,一个是get_proxies函数,用来从代理页面爬数据,这里选用的是快代理,一个是check_proxy函数,用来检测该ip是否能访问目标页面,如果能访问,则将其添加到可用代理列表。
然后是获取网页内容,这里使用requests模块来获取网页内容:
# 获取网页数据
def get_web_data(url, headers, proxies=[]):
try:
data = requests.get(url, proxies=proxies, timeout=3, headers=headers)
except requests.exceptions.ConnectionError as e:
logging.error("请求错误,url:", url)
logging.error("错误详情:", e)
data = None
except:
logging.error("未知错误,url:", url)
data = None
return data
接下来进行网页内容解析,借助一下BeautifulSoup模块和re正则模块来解析网页元素。
# 解析书籍数据
def parse_data(data):
if data is None:
return None
# 处理编码
charset = chardet.detect(data.content)
data.encoding = charset['encoding']
# 正则表达式匹配作者出版社信息
author_pattern = re.compile(r'(作者: (.*))?[\s|\S]*出版社: (.*)[\s|\S]*出版年: (.*)')
# 解析标签
soup = BeautifulSoup(data.text, 'lxml')
book_list = soup.find_all("div", class_="bd doulist-subject")
list = []
for book in book_list:
book_map = {}
book_name = book.find('div', class_='title').get_text().strip()
book_map['book_name'] = book_name
rate_point = book.find('div', class_='rating').find('span', class_='rating_nums').get_text().strip()
book_map['rate_point'] = rate_point
rate_number = book.find('div', class_='rating').find('span', class_='').get_text().strip()[1:-4]
book_map['rate_number'] = rate_number
tmp = book.find('div', class_='abstract').get_text().strip()
m = author_pattern.match(tmp)
if m != None:
author = m.group(1)
if author == None:
author = ''
publisher = m.group(3)
publish_date = m.group(4)
book_map['author'] = author
book_map['publisher'] = publisher
book_map['publish_date'] = publish_date
pic_link = book.find('div', class_='post').a.img['src']
book_map['pic_link'] = pic_link
list.append(book_map)
logging.info("书名:《%s》,作者:%s,评分:%s,评分人数:%s,出版社:%s,出版年:%s,封面链接:%s",
book_name, author, rate_point, rate_number, publisher, publish_date, pic_link)
return list
然后将结果存入csv文件中:
# 存入csv文件
def save_to_csv(filename, books):
with open(filename, 'a', newline='', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=books[0].keys())
for book in books:
writer.writerow(book)
f.close()
这样,我们整体的代码就差不多成型了,全部代码如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
"""
auth: Frank
date: 2019-04-27
desc: 爬取豆瓣读书评分9.0以上书籍并存入csv文件
目标URL:https://www.douban.com/doulist/1264675/?start=0&sort=seq&playable=0&sub_type=4
数据量:530
预计访问次数:22
数据存储:csv
抓取内容格式:书籍名称 作者 作者国籍 评分 评价人数 出版社 出版年 封面链接
"""
import logging
import os
import random
import urllib.robotparser
import time
import requests
import re
import chardet
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import csv
# 获取网页数据
def get_web_data(url, headers, proxies=[]):
try:
data = requests.get(url, proxies=proxies, timeout=3, headers=headers)
except requests.exceptions.ConnectionError as e:
logging.error("请求错误,url:", url)
logging.error("错误详情:", e)
data = None
except:
logging.error("未知错误,url:", url)
data = None
return data
# 解析书籍数据
def parse_data(data):
if data is None:
return None
# 处理编码
charset = chardet.detect(data.content)
data.encoding = charset['encoding']
# 正则表达式匹配作者出版社信息
author_pattern = re.compile(r'(作者: (.*))?[\s|\S]*出版社: (.*)[\s|\S]*出版年: (.*)')
# 解析标签
soup = BeautifulSoup(data.text, 'lxml')
book_list = soup.find_all("div", class_="bd doulist-subject")
list = []
for book in book_list:
book_map = {}
book_name = book.find('div', class_='title').get_text().strip()
book_map['book_name'] = book_name
rate_point = book.find('div', class_='rating').find('span', class_='rating_nums').get_text().strip()
book_map['rate_point'] = rate_point
rate_number = book.find('div', class_='rating').find('span', class_='').get_text().strip()[1:-4]
book_map['rate_number'] = rate_number
tmp = book.find('div', class_='abstract').get_text().strip()
m = author_pattern.match(tmp)
if m is not None:
author = m.group(1)
if author is None:
author = ''
publisher = m.group(3)
publish_date = m.group(4)
book_map['author'] = author
book_map['publisher'] = publisher
book_map['publish_date'] = publish_date
pic_link = book.find('div', class_='post').a.img['src']
book_map['pic_link'] = pic_link
list.append(book_map)
logging.info("书名:《%s》,作者:%s,评分:%s,评分人数:%s,出版社:%s,出版年:%s,封面链接:%s",
book_name, author, rate_point, rate_number, publisher, publish_date, pic_link)
return list
# 存入csv文件
def save_to_csv(filename, books):
with open(filename, 'a', newline='', encoding='utf-8') as file:
writer = csv.DictWriter(file, fieldnames=books[0].keys())
for tmp_book in books:
writer.writerow(tmp_book)
# 获取代理数据
def get_proxies(proxy_url, dis_url, page=10):
proxy_list = []
for i in range(1, page + 1):
tmp_ua = UserAgent()
tmp_headers = {'User-Agent': tmp_ua.random}
html_str = get_web_data(proxy_url + str(i), tmp_headers)
soup = BeautifulSoup(html_str.content, "lxml")
ips = soup.find('tbody').find_all('tr')
for ip_info in ips:
tds = ip_info.find_all('td')
ip = tds[0].get_text()
port = tds[1].get_text()
ip_str = ip + ":" + port
tmp = {"http": "http://" + ip_str}
if check_proxy(dis_url, tmp):
logging.info("ip:%s is available", ip_str)
proxy_list.append(ip_str)
time.sleep(1)
return proxy_list
# 检测代理ip是否可用
def check_proxy(url, proxy):
try:
tmp_ua = UserAgent()
tmp_headers = {'User-Agent': tmp_ua.random}
res = requests.get(url, proxies=proxy, timeout=1, headers=tmp_headers)
except:
return False
else:
return True
def get_random_ip(ip_list):
proxy = random.choice(ip_list)
proxies = {'http': 'http://' + proxy}
return proxies
if __name__ == '__main__':
logging.basicConfig(level=logging.INFO)
url = 'https://www.douban.com/doulist/1264675/?start='
file_path = os.path.dirname(os.path.realpath(__file__)) + os.sep + 'douban.csv'
f = open(file_path, 'w')
f.close()
# 获取代理
proxies = get_proxies("https://www.kuaidaili.com/free/intr/", url, 5)
# 设置headers
ua = UserAgent()
result_list = []
for num in range(0, 530, 25):
headers = {'User-Agent': ua.random}
logging.info('headers:%s', headers)
data = get_web_data(url + str(num), headers, get_random_ip(proxies))
book = parse_data(data)
save_to_csv(file_path, book)
time.sleep(1)
来运行一下:

最终爬下来的文件:
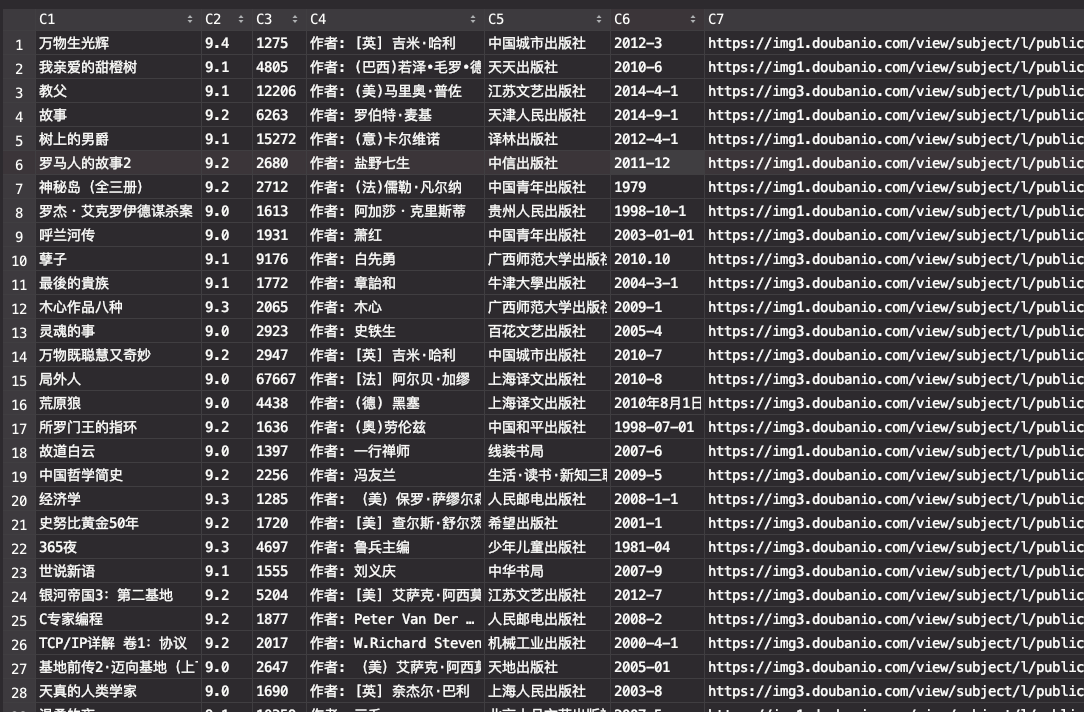
源码以及爬下来的数据都放到了github:https://github.com/MFrank2016/douban_spider
要运行该文件,除了需要安装import中的模块,还需要安装一个lxml模块才能运行。
总结
其实写爬虫的思路都是差不多的,大概分为几步:
- 查找可用代理ip
- 设置UA
- 使用代理ip访问网页
- 解析网页数据
- 存储/分析
这个爬虫还是比较简陋的,在获取代理并校验代理ip可用性这一步花了较多时间,优化的话,可以用多线程来进行代理ip可用性检测,得到一定数量的代理ip后,多线程进行网页访问和数据解析,然后再存储到数据库中。不过要使用多线程的话复杂度就会大大提升了,在这个小爬虫里,因为只需要爬22页数据,所以没有使用的必要。
还有一个重要的问题就是这里没有对异常信息进行处理,运行中途如果出错就会导致前功尽弃,要考虑好大部分异常情况并不容易。
当然,整个过程并没有上文描述的这样简单,调试过程还是花了不少时间,应该没有用过 BeautifulSoup 模块,摸索了不少时间才能初步使用它。
作为python的初学者而言,用python最舒服的感受便是好用的模块确实多,用 BeautifulSoup 模块来进行网页解析确实比直接正则解析要方便的多,而且更容易控制。
个人觉得爬虫只是用来获取数据的一个手段,用python也好,java也好,没有优劣之分,能实现想要的达成的目的即可,用什么语言顺手就用什么语言。将数据爬取下来后,便可以进行后续的数据分析,可视化等工作了。使用工具不是目的,只是手段,这一点我也是花了很长时间才慢慢理解。就像使用爬虫来获取数据来进行数据分析,从数据中挖掘想要的信息并用于指导实践才是真正产生价值的地方。作为技术人员,很容易产生的误区便是把技术当做一切,而不重视业务,殊不知真正创造价值的正是业务的制定者和执行者,技术最终都是为业务服务的。

本文到此就告一段落了,希望能对你有所帮助,也欢迎关注我的公众号进行留言交流。

【Python爬虫】听说你又闹书荒了?豆瓣读书9.0分书籍陪你过五一的更多相关文章
- Python爬虫小白入门(七)爬取豆瓣音乐top250
抓取目标: 豆瓣音乐top250的歌名.作者(专辑).评分和歌曲链接 使用工具: requests + lxml + xpath. 我认为这种工具组合是最适合初学者的,requests比pytho ...
- python爬虫抓取中国最好大学排名1 清华大学 北京 94.0 100.0 97.70% 清华大学 2 北京大学
import requests from bs4 import BeautifulSoup import bs4.element r=requests.get("http://www.zui ...
- 23个Python爬虫开源项目代码,包含微信、淘宝、豆瓣、知乎、微博等
今天为大家整理了23个Python爬虫项目.整理的原因是,爬虫入门简单快速,也非常适合新入门的小伙伴培养信心,所有链接指向GitHub,微信不能直接打开,老规矩,可以用电脑打开. 关注公众号「Pyth ...
- 豆瓣读书爬虫(requests + re)
前面整理了一些爬虫的内容,今天写一个小小的栗子,内容不深,大佬请忽略.内容包括对豆瓣读书网站中的书籍的基本信息进行爬取,并整理,便于我们快速了解每本书的中心. 一.爬取信息 每当爬取某个网页的信息时, ...
- 批量下载小说网站上的小说(python爬虫)
随便说点什么 因为在学python,所有自然而然的就掉进了爬虫这个坑里,好吧,主要是因为我觉得爬虫比较酷,才入坑的. 想想看,你可以批量自动的采集互联网上海量的资料数据,是多么令人激动啊! 所以我就被 ...
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- Python爬虫入门
Python爬虫简介(来源于维基百科): 网络爬虫始于一张被称作种子的统一资源地址(URLs)列表.当网络爬虫访问这些统一资源定位器时,它们会甄别出页面上所有的超链接,并将它们写入一张"待访列表",即 ...
- [python爬虫] Selenium定向爬取海量精美图片及搜索引擎杂谈
我自认为这是自己写过博客中一篇比较优秀的文章,同时也是在深夜凌晨2点满怀着激情和愉悦之心完成的.首先通过这篇文章,你能学到以下几点: 1.可以了解Python简单爬取图片的一些思路和方法 ...
- python爬虫如何入门
学爬虫是循序渐进的过程,作为零基础小白,大体上可分为三个阶段,第一阶段是入门,掌握必备的基础知识,第二阶段是模仿,跟着别人的爬虫代码学,弄懂每一行代码,第三阶段是自己动手,这个阶段你开始有自己的解题思 ...
随机推荐
- 中兴u880e精简教程
精简软件请参考此处 (A代表可以删除,B代表建议别删除.)删或留你做主. Accounts AndSyncSettings.apk 账户与同步设置 A alarming.apk 闹钟时钟 A Appl ...
- 别名的使用注意,""真坑。
我们使用别名都是使用as关键字. 大多数时候我们都会省略as关键字,然后后面直接加别名就好了.我的习惯是别名用双引号括起来. 今天因为这个习惯坑了我一大波 首先oracle的别名的规则: AS 别名 ...
- ANSI的Escape序列屏幕控制码
http://blog.csdn.net/lano2088/article/details/51985563 https://www.cnblogs.com/pied/p/4175641.html h ...
- 在Android中来修改SQL里面的权限和显示内容
1.在Android中建立了一个数据库. 然后要知道存储数据库的路劲.得到路劲然后进入cmd里面进到 手机终端. 2.利用splite3来显示数据库里面的东西. 3.利用chmod来修改数据库文件的权 ...
- Codeforces 983B. XOR-pyramid【区间DP】
LINK 定义了一种函数f 对于一个数组b 当长度是1的时候是本身 否则是用一个新的数组(长度是原数组-1)来记录相邻数的异或,对这个数组求函数f 大概是这样的: \(f(b[1]⊕b[2],b[2] ...
- UVA11732 "strcmp()" Anyone?【左儿子右兄弟Trie】
LINK1 LINK2 题目大意 给你一些字符串,并定义了一个函数(具体见题面) 问你把任意两个字符串放到函数里面得到的值的和是多少 思路 该怎么统计答案呢? 每次考虑当前插入的串和所有已经插入过的串 ...
- Linux环境编程之同步(四):Posix信号量
信号量是一种用于提供不同进程间或一个给定进程的不同线程间同步手段的原语.有三种类型:Posix有名信号量,使用Posix IPC名字标识.Posix基于内存的信号量,存放在共享内存区中:System ...
- 为什么 Windows 10 无论怎么设置一分钟后就自动关屏幕?
为什么 Windows 10 无论怎么设置一分钟后就自动关屏幕? 在设置中设置了很多方法,但不管怎么设置就是不行,不到一分钟一定关屏幕. 开始以为是能源之星引起,查了相关资料说不是,那个能源之星标志只 ...
- 安全关闭MySQL
想要安全关闭 mysqld 服务进程,建议按照下面的步骤来进行: 0.用具有SUPER.ALL等最高权限的账号连接MySQL,最好是用 unix socket 方式连接: 1.在5.0及以上版本,设置 ...
- mediawikide
wiki.conf server { listen 80; server_name wiki.talkvip.cn; index index.html index.htm index.php; roo ...