(一)ElasticSearch-入门
目录:
一.前言
二.安装
三.索引
四.搜索
五.聚合
六.分布式的特性
一.前言
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎。无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的Restful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
Elasticsearch不仅仅是Lucene和全文搜索,我们还能这样去描述它:
(1)分布式的实时文件存储,每个字段都被索引并可被搜索。
(2)分布式的实时分析搜索分布式的实时分析搜索引擎。
(3)可以扩展到上百台服务器,处理PB级结构化或非结构化数据。
而且,所有的这些功能被集成到一个服务里面,你的应用可以通过简单的Restful API、各种语言的客户端甚至命令行与之交互。
二.安装
在安装Elasticsearch引擎之前,必须安装ES需要的软件环境,安装Java JDK和配置JAVA_HOME环境变量:
1.首先从Oracle官网下载和安装Java SE开发包:

由于ElasticSearch对JRE的版本是很敏感的,错误的版本,会导致ElasticSearch无法运行,我运行的项目ElasticSearch版本是elasticsearch-2.4.4,所以对应Java SE版本是Java SE 8[Java Platform(JDK)8u121]。但是我们并没有看到对应Java SE版本,那么就得从Java Archive下载合适的版本,具体对应版本号如下所示:
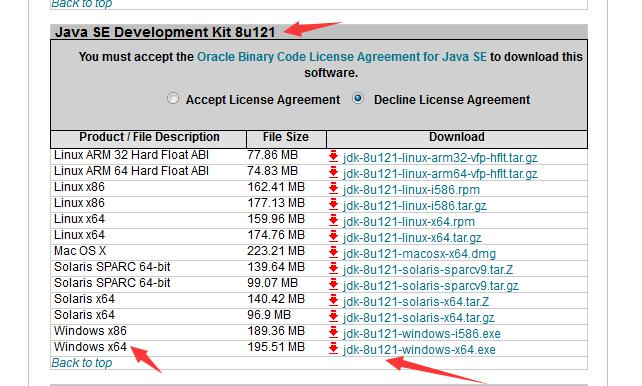
下载并安装Java SE开发包之后,打开Java控制面板,把自动更新选项勾选掉,防止其自动更新,导致后面ES运行报错。具体操作如下所示:
Java SE开发包安装完成之后,需要在服务器上创建JAVA_HOME环境变量
点击“计算机”的属性->高级系统设置(Advanced System Setting)->高级->环境变量(Environment Variables),新建一个用户环境变量 JAVA_HOME,设置变量值是:C:\Program Files\Java\jdk1.8.0_121
注释:在Windows系统中,“%环境变量名%”用法的含义是获取指定环境变量的值,创建JAVA_HOME环境变量的作用,是由于安装ElasticSearch需要引用Java SE开发包。
2.安装ElasticSearch:
从ElasticSearch官网下载中心下载ElasticSearch 2.4.4版本安装包,具体版本号在历史记录里面:

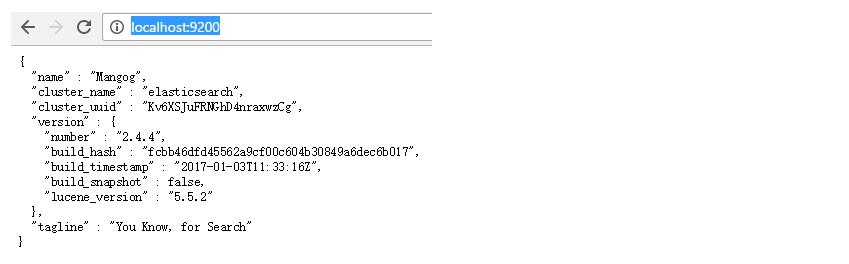
将zip文件解压到C盘,进入 C:\elasticsearch-2.4.4\bin 目录,双击执行 elasticsearch.bat,该脚本文件执行ElasticSearch安装程序,稍等片刻,打开浏览器,输入 http://localhost:9200,显示以下画面,说明ES安装成功。
安装head插件:
为了便于管理ES,本文使用head插件,这是最初级的管理工具,在浏览器中显示ES集群,索引等信息,十分好用。
(1)在命令行中安装插件:
按住Windows+R,输入cmd,打开命令行工具,进入到ElasticSearch的bin目录,使用ES命令安装插件。命令如下所示:
cd C:\elasticsearch-2.4.4\bin
plugin install mobz/elasticsearch-head
安装界面提示如下所示:

(2)通过网页管理ElasticSearch:
在本地浏览器中输入http://localhost:9200/_plugin/head/,如果看到以下截图,说明head插件安装成功: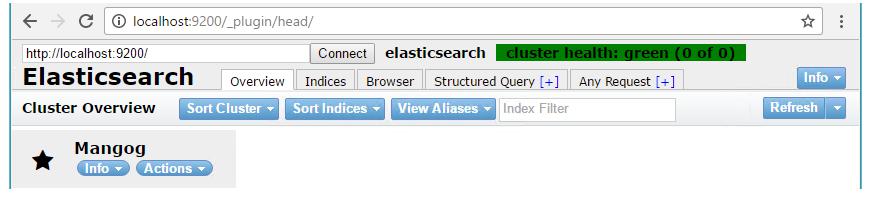
(3)将ElasticSearch 安装成Windows服务(Service)
方法一:
(3.1)cmd打开控制台界面,切换到ElasticSearch的bin目录(cd C:\elasticsearch-2.4.4\bin),执行service install命令。
(3.2)启动ElasticSearch服务执行service start命令。
(3.3)如果启动ElasticSearch服务时候报如下图错误:

切换到ElasticSearch的bin目录(cd C:\elasticsearch-2.4.4\bin),执行service manager命令;
如下图:
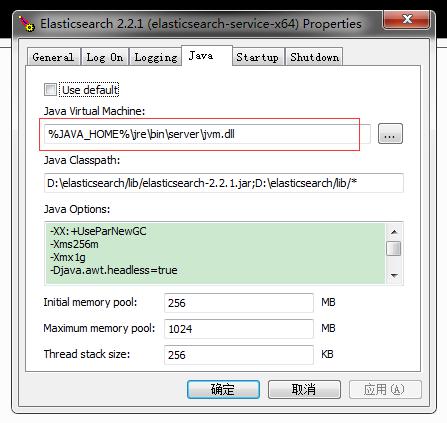
为什么还会出现这种错误?我们的JAVA_HOME也设置了,这就是Windows的坑爹之处;要么选择use default,要么浏览选择jvm.dll 的绝对路径,只能选择其一。
注:
在这里特声明一下,这个安装步骤,我是转载修改博主悦光阴(ElasticSearch入门 第一篇:Windows下安装ElasticSearch)这篇文章而来的。如果同时想要了解集群配置问题的同学,可以转移悦光阴处学习(ElasticSearch入门 第二篇:集群配置)相关配置知识。因为本人只是了解基础集群配置。后续学习深入了解之后再深聊这块知识点。
好了,到这里,整个生产环境就部署完成了。后面让我们来进行一个简单教程,它涵盖了一些基本的概念介绍,比如索引(indexing)、搜索(search)以及聚合(aggregations)。通过这个教程,我们可以让你对Elasticsearch能做的事以及其易用程度有一个大致的感觉。
三.索引
1.首先我们根据一个简单的对比图来了解索引跟传统关系型数据库:
RelationalDB->Databases->Tables->Rows->Columns
Elasticsearch->Indices->Types->Documents->Fields
2.Elasticsearch集群可以包含多个索引(indices)(数据库),每一个索引可以包含多个类型(types)(表),每一个类型包含多个文档(documents)(行),然后每个文档包含多个字段(Fields)(列)。
Elasticsearch里面的索引跟传统关系型数据库里面定义的索引是两种不同概念:
Elasticsearch索引,就像是传统关系数据库中的数据库,它是相关文档存储的地方。索引一个文档表示把一个文档存储到索引(名词)里,以便它可以被检索或者查询。这很像SQL中的INSERT关键字,差别是,如果文档已经存在,新的文档将覆盖旧的文档。
Elasticsearch倒排索引,传统数据库为特定列增加一个索引,例如B-Tree索引来加速检索。Elasticsearch和Lucene使用一种叫做倒排索引(inverted index)的数据结构来达到相同目的。
3.ElasticSearch发出请求组成部分跟传统HTTP请求是一样的:
(1)常用HTTP动词有下面五个:GET:获取服务器中的对象;POST:增删改服务器中的对象;PUT:创建服务器中的对象;DELETE:删除服务器中的对象;HEAD:仅仅用于获取对象的基础信息;
(2)Query_String:像传递URL参数一样去传递查询语句,例如
/deng/employee/_search?q=last_name:Smith;
(3)默认端口:9200;
(4)Body:一个JSON格式的请求主体;
4.好了,说那么多,现在我们根据一个生产环境的事例来更加清楚了解Elasticsearch索引的如何应用:假设我们在一家名称为deng的公司工作,某天人力资源部门要求我们技术部门统计下公司新入职员工信息,方便了解员工信息。
录入新员工信息之前,我们先创建deng公司(索引),具体命令执行如下:
HTTP:PUT deng
Web界面:

然后我们在数据浏览选项当中会看到创建对应索引:
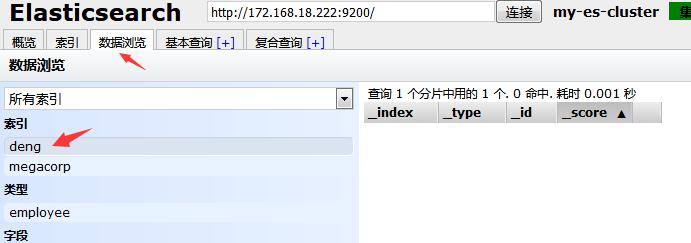
现在我们录入三个新员工信息,执行命令是:
HTTP:PUT /deng/employee/1
Body:
{
"first_name": "John",
"last_name": "Smith",
"age": ,
"about": "I love to go rock climbing",
"interests": [
"sports",
"music"
]
}
HTTP:PUT /deng/employee/2
Body:
{
"first_name": "Jane",
"last_name": "Smith",
"age": ,
"about": "I like to collect rock albums",
"interests": [
"music"
]
}
HTTP:PUT /deng/employee/3
Body:
{
"first_name": "Douglas",
"last_name": "Fir",
"age": ,
"about": "I like to build cabinets",
"interests": [
"forestry"
]
}
Web界面:
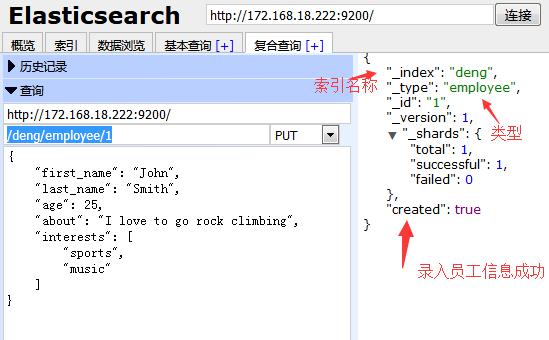
再回到数据浏览选项当中,我们是不是看到了刚刚录入新员工信息?

四.搜索
好了录入所有新员工信息之后,我们来检索deng公司(索引-数据库)所有新员工(类型-表)数据,一般检索方式有两种,一种是通过URL传参方式获取员工数据(Query_String),另外一种是在Body里面传入JSON(DSL语句)查询:
(1)如果我们要检索某个新入职员工信息,可以根据标识定位找到该员工信息,例如ID,或者人名:
Query_String:
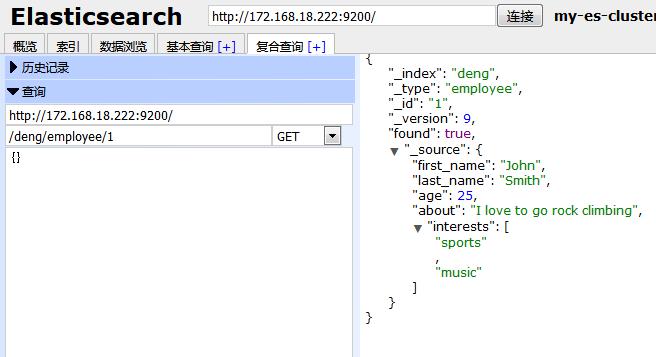
HTTP:GET /deng/employee/1
Web界面:
HTTP:GET /deng/employee/_search?q=last_name:Fir (根据某个类型字段来定位该员工信息)
Web界面:

DSL语句:
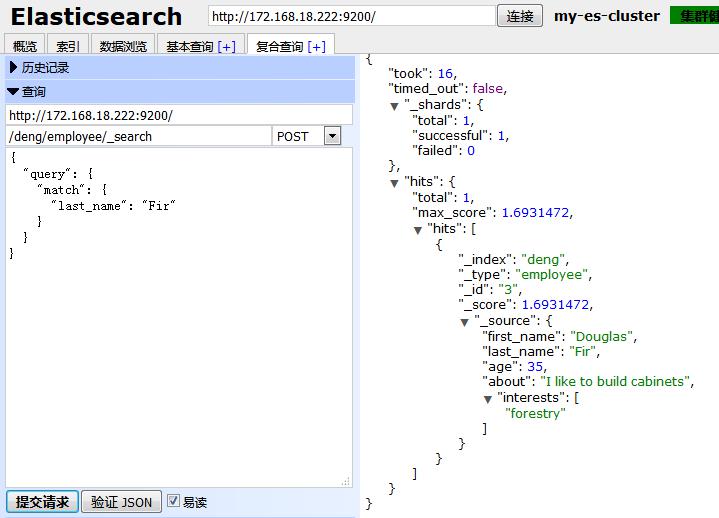
HTTP:POST /deng/employee/_search
Body:
{
"query": {
"match": {
"last_name": "Fir"
}
}
}
Web界面:
(2)如果我们要检索名称为Smith,且年龄大于30以上的新入职员工信息(过滤器filter):
DSL语句:
HTTP:POST /deng/employee/_search
Body:
{
"query": {
"filtered": {
"filter": {
"range": {
"age": {
"gt":
}
}
},
"query": {
"match": {
"last_name": "smith"
}
}
}
}
}
Web界面:


(3)如果我们想要查看某个新入职员工信息,但是我们忘记了他叫什么名字了,隐约只记得他好像说过喜欢rock climbing,那么我们可以使用全文检索,把about字段里面跟rock或者 climbing相关的员工信息都检索出来再进行筛选(全文检索match):
DSL语句:
HTTP:POST /deng/employee/_search
Body:
{
"query": {
"match": {
"about": "rock climbing"
}
}
}
Web界面:
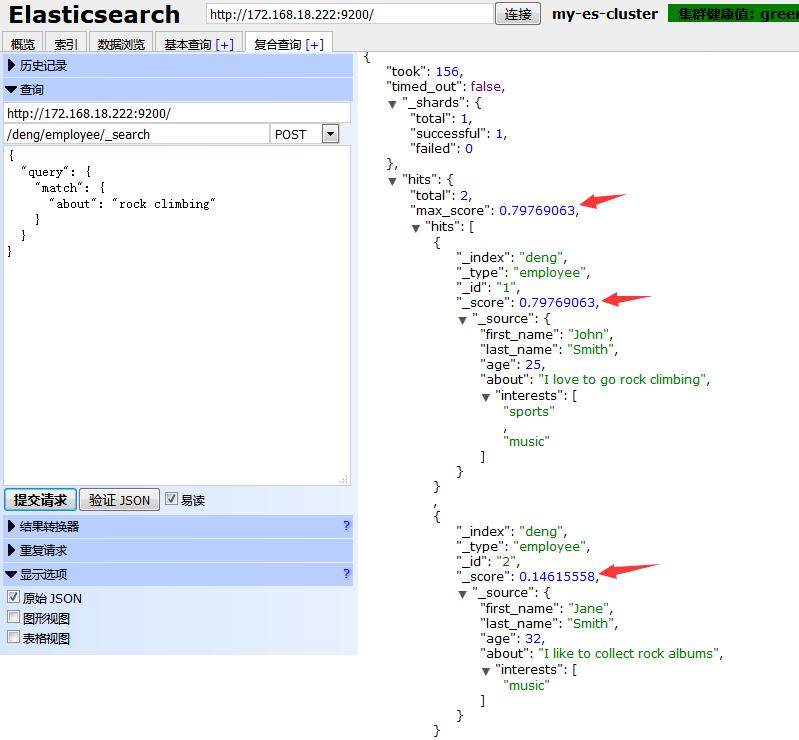
你们可以看到在使用了match关键字检索之后,会出现两个检索的结果,会按照结果相关性评分来排序,越接近搜索关键词的结果越靠前,评分也就就越高。
(4)同样道理,如果我们清楚记得某个入职员工说过他喜欢rock climbing,我们只想检索出跟about字段rock climbing关键词一致的新入职员工记录(短语检索match_phrase):
DSL语句:
HTTP:POST /deng/employee/_search
Body:
{
"query": {
"match_phrase": {
"about": "rock climbing"
}
}
}
Web界面:
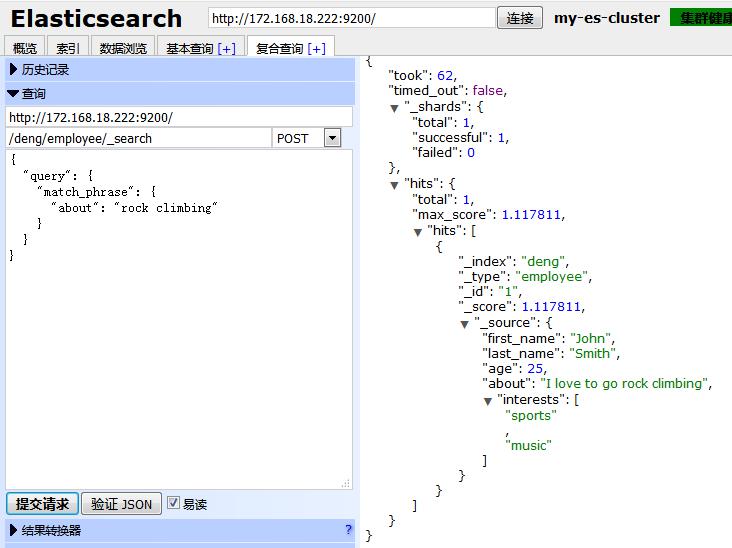
(5)当我们想要在检索员工记录中高亮关键词(高亮highlight):
DSL语句:
HTTP:POST /deng/employee/_search
Body:
{
"query": {
"match_phrase": {
"about": "rock climbing"
}
},
"highlight": {
"fields": {
"about": {}
}
}
}
Web界面:
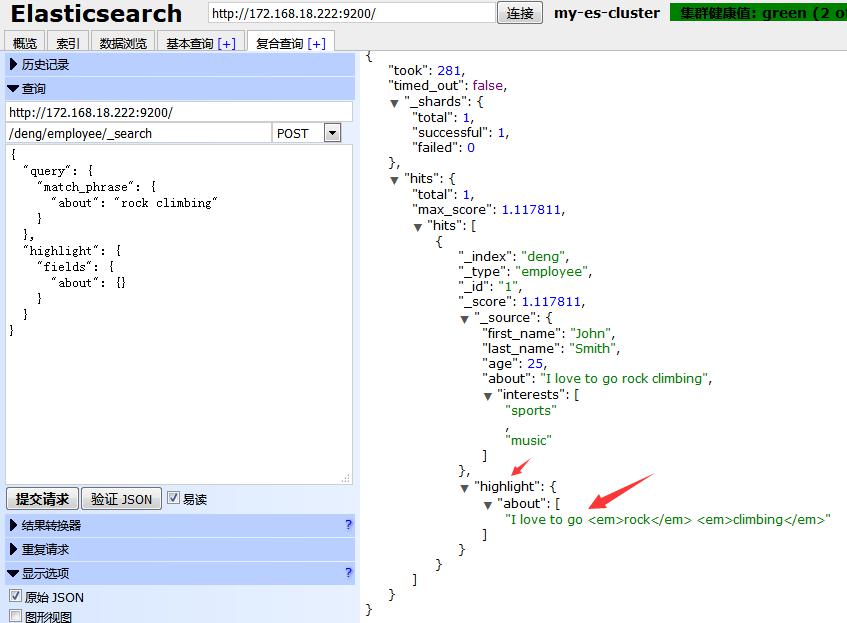
在上面截图我们可以看到about字段检索出内容关键词rock climbing分别都加了<em></em>HTML标签,这是高亮标识。
五.聚合
(1)Elasticsearch有一个功能叫做聚合(aggregations),它允许你在数据上生成复杂的分析统计。它跟我们在SQL中GROUP BY很相似,但是比它更加强大。比如我们想要在新入职员工当中统计每个员工的爱好(聚合aggregations):
HTTP:POST /deng/employee/_search
Body:
{
"aggs": {
"all_interests": {
"terms": {
"field": "interests"
}
}
}
}
Web界面:
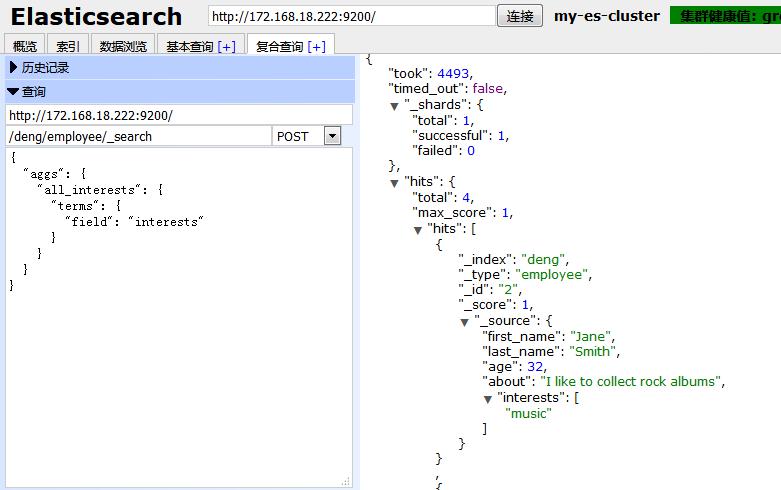

如上图可以看到,检索出来结果是喜欢music:2人,atrs:1人,forestry:1人,sports:1人。
(2)如果我们想知道所有叫smith员工的爱好分别是什么呢?请看下面例子:
HTTP:POST /deng/employee/_search
Body:
{
"query": {
"match": {
"last_name": "smith"
}
},
"aggs": {
"all_interests": {
"terms": {
"field": "interests"
}
}
}
}
Web界面:
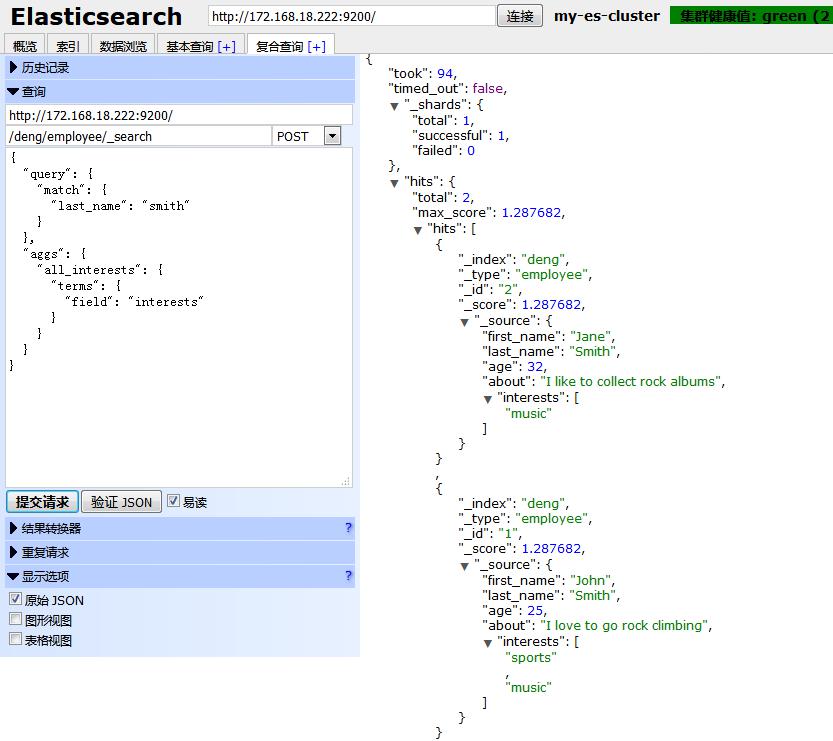

从上面检索结果,我们可以看出来所有叫smith的员工喜欢music:2人,sports:1人。
(3)聚合也允许分级汇总,例如我们要统计每个兴趣下员工平均年龄:
HTTP:POST /deng/employee/_search
Body:
{
"aggs": {
"all_interests": {
"terms": {
"field": "interests"
},
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
}
}
}
}
}
Web界面:
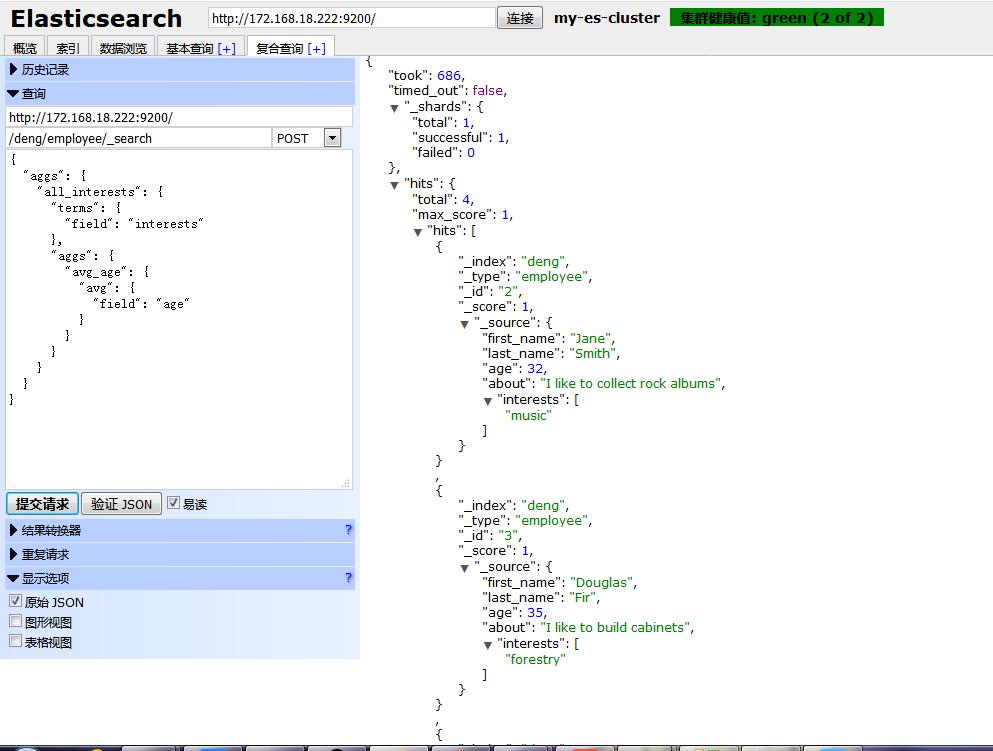

很明显这个检索结果让我们能得到更多详情员工信息,即使你不了解语法,但你也能通过大概感觉通过这个特性完成相当复杂聚合工作。
六.分布式的特性
Elasticsearch致力于隐藏分布式系统的复杂性。以下这些操作都是在底层自动完成的:
(1)将你的文档分区到不同的容器或者分片(shards)中,它们可以存在于一个或多个节点中。
(2)将分片均匀的分配到各个节点,对索引和搜索做负载均衡。
(3)冗余每一个分片,防止硬件故障造成的数据丢失。
(4)将集群中任意一个节点上的请求路由到相应数据所在的节点。
(5)无论是增加节点,还是移除节点,分片都可以做到无缝的扩展和迁移。
通过上述案例,我相信大家对ES有了一个很基础的了解,这篇文章只是介绍ES入门,例如集群配置,索引管理,深入分片这些知识点,后续我们再来聊。
参考文档:
ElasticSearch入门 第一篇:Windows下安装ElasticSearch
(一)ElasticSearch-入门的更多相关文章
- ElasticSearch入门-搜索如此简单
搜索引擎我也不是很熟悉,但是数据库还是比较了解.可以把搜索理解为数据库的like功能的替代品.因为like有以下几点不足: 第一.like的效率不行,在使用like时,一般都用不到索引,除非使用前缀匹 ...
- ElasticSearch入门知识扫盲
ElasticSearch 入门介绍 tags: 第三方 lucene [toc] 1. what Elastic Search(ES)是什么 全文检索和lucene 全文检索 优点:高效,准确,分词 ...
- 《读书报告 -- Elasticsearch入门 》--简单使用(2)
<读书报告 – Elasticsearch入门 > ' 第四章 分布式文件存储 这章的主要内容是理解数据如何在分布式系统中存储. 4.1 路由文档到分片 创建一个新文档时,它是如何确定应该 ...
- 《读书报告 -- Elasticsearch入门 》-- 安装以及简单使用(1)
<读书报告 – Elasticsearch入门 > 第一章 Elasticsearch入门 Elasticsearch是一个实时的分布式搜索和分析引擎,使得人们可以在一定规模上和一定速度上 ...
- ElasticSearch入门 附.Net Core例子
1.什么是ElasticSearch? Elasticsearch是基于Lucene的搜索引擎.它提供了一个分布式,支持多租户的全文搜索引擎,它具有HTTP Web界面和无模式JSON文档. Elas ...
- ElasticSearch入门点滴
这是Elasticsearch-6.2.4 版本系列的第一篇: ElasticSearch入门 第一篇:Windows下安装ElasticSearch ElasticSearch入门 第二篇:集群配置 ...
- 全文搜索引擎Elasticsearch入门实践
全文搜索引擎Elasticsearch入门实践 感谢阮一峰的网络日志全文搜索引擎 Elasticsearch 入门教程 安装 首先需要依赖Java环境.Elasticsearch官网https://w ...
- Elasticsearch Elasticsearch入门指导
Elasticsearch入门指导 By:授客 QQ:1033553122 1. 开启elasticsearch服务器 1 2. 基本概念 2 <1> 集群(Cluster) 2 < ...
- ElasticSearch 入门
http://www.oschina.net/translate/elasticsearch-getting-started?cmp ElasticSearch 简单入门 返回原文英文原文:Getti ...
- 全文搜索引擎 Elasticsearch 入门
1. 百科 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticsearch是用Java开发的,并作 ...
随机推荐
- Docker系列02: 容器生命周期管理 镜像&容器
A) Docker信息1. 查看docker运行状态 systemctl status docker docker.service - Docker Application Container Eng ...
- MongoDB 生态 – 可视化管理工具
工欲善其事,必先利其器,我们在使用数据库时,通常需要各种工具的支持来提高效率:很多新用户在刚接触 MongoDB 时,遇到的问题是『不知道有哪些现成的工具可以使用』,本系列文章将主要介绍 MongoD ...
- 使用css弹性盒子模型
提示: 当期内容不充实, 修改后再来看吧 以下称:弹性子元素: 子元素, 弹性容器: 容器 弹性盒子的属性 1. css弹性盒子模型规定了弹性元素如何在弹性容器内展示 2. 弹性元素默认显示在弹性容器 ...
- PDF预览之PDFObject.js总结
get from:PDF预览之PDFObject.js总结 PDFObject.js - 将PDF嵌入到一个div内,而不是占据整个页面(要求浏览器支持显示PDF,不支持,可配置PDF.js来实现 ...
- 关于TP5中的依赖注入和容器和facade
看了不少的文章,也看了官方的介绍,还是根据自己的理解,写写看法,理清下思路 只是单纯的说依赖注入Dependency Injection和容器 别的不白扯 比如有A,B,C三个类 A类的1方法依赖B类 ...
- VB.Net与C# 的语法比较
最近看代码或写代码时,经常把VB与C#的基本语法搞混,为方便查看,特对其异同进行对比: 變數初始化 VB.NET 自動將所有的變數初始化成 0 或 nothing.C# 在你未初始化變數之前不准你用該 ...
- Java匿名内部类的学习
新建一个抽象类或者接口,抽象类中只要有一个抽象方法就是抽象类,接口的定义是:里面的方法全部都是抽象方法,接口和抽象类不能直接实例化,需要子类来实现 /* 匿名内部类: 1.匿名内部类其实就是内部类的简 ...
- LUA table.sort的问题,数组与表的区别
t = { [] = , [] = , [] = , [] = , } t1 = { , , , , } t2 = { 'a', 'b','d','c', } function cmp(v1, v2) ...
- 迷你MVVM框架 avalonjs 1.3.3发布
大家可以在仓库中看到,多出了一个叫avalon.observe的东西,它是基于Object.observe,dataset, Promise等新API实现.其中,它也使用全新的静态收集依赖的机制,这个 ...
- 【Git】三、工作区、暂存区、版本库
一.基础概念 工作区:电脑中可以看到的目录,为电脑中的项目文件 暂存区:暂存修改的地方 版本库:存放项目的各个版本文件 二.详细介绍 工作区为我们工作所使用的目录,在工作区我们对项目文件进行增删改查. ...