spark集群使用hanlp进行分布式分词操作说明
本篇分享一个使用hanlp分词的操作小案例,即在spark集群中使用hanlp完成分布式分词的操作,文章整理自【qq_33872191】的博客,感谢分享!以下为全文:
分两步:
第一步:实现hankcs.hanlp/corpus.io.IIOAdapter
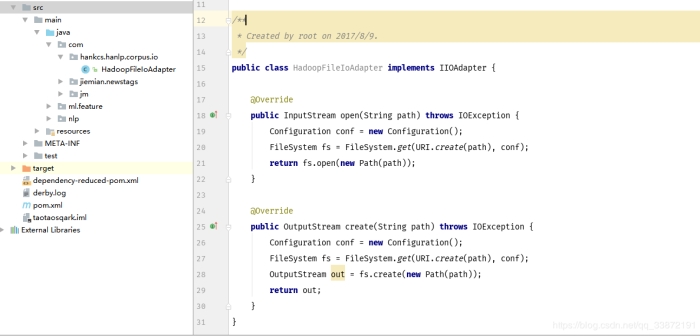
1.public class HadoopFileIoAdapter implements IIOAdapter {
2.
3. @Override
4. public InputStream open(String path) throws IOException {
5. Configuration conf = new Configuration();
6. FileSystem fs = FileSystem.get(URI.create(path), conf);
7. return fs.open(new Path(path));
8. }
9.
10. @Override
11. public OutputStream create(String path) throws IOException {
12. Configuration conf = new Configuration();
13. FileSystem fs = FileSystem.get(URI.create(path), conf);
14. OutputStream out = fs.create(new Path(path));
15. return out;
16. }
17. }
第二步:修改配置文件。root为hdfs上的数据包,把IOAdapter改为咱们上面实现的类


ok,这样你就能在分布式集群上使用hanlp进行分词了。
整个步骤比较简单,欢迎各位大神交流探讨!
spark集群使用hanlp进行分布式分词操作说明的更多相关文章
- 大数据学习day18----第三阶段spark01--------0.前言(分布式运算框架的核心思想,MR与Spark的比较,spark可以怎么运行,spark提交到spark集群的方式)1. spark(standalone模式)的安装 2. Spark各个角色的功能 3.SparkShell的使用,spark编程入门(wordcount案例)
0.前言 0.1 分布式运算框架的核心思想(此处以MR运行在yarn上为例) 提交job时,resourcemanager(图中写成了master)会根据数据的量以及工作的复杂度,解析工作量,从而 ...
- zhihu spark集群,书籍,论文
spark集群中的节点可以只处理自身独立数据库里的数据,然后汇总吗? 修改 我将spark搭建在两台机器上,其中一台既是master又是slave,另一台是slave,两台机器上均装有独立的mongo ...
- Spark集群 + Akka + Kafka + Scala 开发(3) : 开发一个Akka + Spark的应用
前言 在Spark集群 + Akka + Kafka + Scala 开发(1) : 配置开发环境中,我们已经部署好了一个Spark的开发环境. 在Spark集群 + Akka + Kafka + S ...
- 实验室中搭建Spark集群和PyCUDA开发环境
1.安装CUDA 1.1安装前工作 1.1.1选取实验器材 实验中的每台计算机均装有双系统.选择其中一台计算机作为master节点,配置有GeForce GTX 650显卡,拥有384个CUDA核心. ...
- 如果Apache Spark集群中没有分布式系统,则会?
若当连接到Spark的master之后,若集群中没有分布式文件系统,Spark会在集群中每一台机器上加载数据,所以要确保Spark集群中每个节点上都有完整数据. 通常可以选择把数据放到HDFS.S3或 ...
- 使用docker安装部署Spark集群来训练CNN(含Python实例)
使用docker安装部署Spark集群来训练CNN(含Python实例) http://blog.csdn.net/cyh_24/article/details/49683221 实验室有4台神服务器 ...
- Spark集群搭建简配+它到底有多快?【单挑纯C/CPP/HADOOP】
最近耳闻Spark风生水起,这两天利用休息时间研究了一下,果然还是给人不少惊喜.可惜,笔者不善JAVA,只有PYTHON和SCALA接口.花了不少时间从零开始认识PYTHON和SCALA,不少时间答了 ...
- spark集群搭建整理之解决亿级人群标签问题
最近在做一个人群标签的项目,也就是根据客户的一些交易行为自动给客户打标签,而这些标签更有利于我们做商品推荐,目前打上标签的数据已达5亿+, 用户量大概1亿+,项目需求就是根据各种组合条件寻找标签和人群 ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
随机推荐
- C++连接mysql数据库的两种方法
本文主要介绍了C++连接mysql数据库的两种方法,希望通过本文,能对你有所帮助,一起来看. 现在正做一个接口,通过不同的连接字符串操作不同的数据库.要用到mysql数据库,以前没用过这个数据库,用a ...
- placeholder兼容性问题
由于placeholder是H5新属性,IE9及以下都不支持 解决办法:给input添加一个背景图,背景图里面添加placeholder内容,当焦点落在输入框中,背景图隐藏,即可做出类似的效果 代码: ...
- Dalvik源码阅读笔记(一)
dalvik 虚拟机启动入口在 JNI_CreateJavaVM(), 在进行完 JNIEnv 等环境设置后,调用 dvmStartup() 函数进行真正的 DVM 初始化. jint JNI_Cre ...
- 【c++】函数默认参数
c++ Prime Plus sixth edition page274 如何设置默认值呢?必须通过函数原型. 只有原型指定了默认值.函数定义与没有默认参数时完全相同. 参考 1. http://ww ...
- pytorch实现style transfer
说是实现,其实并不是我自己实现的 亮出代码:https://github.com/yunjey/pytorch-tutorial/tree/master/tutorials/03-advanced/n ...
- jupyter notebook远程服务器终端连接
如下图
- 田螺便利店—win10专业版激活码
win10专业版:VP4MG-CMX8Q-27THR-Y468R-HRVR7 开始——设置——更新和安全——激活——更改产品密钥 复制VP4MG-CMX8Q-27THR-Y468R-HRVR7即可激活 ...
- vim 的编辑模式 命令模式
1.vim的编辑模式 进入编辑模式 按键: a i o a: 表示在光标当前的,后面开始插入,写数据 i : 则表示 前面 . o : 表面在光标当前的,下一行开始写入数据. O : 大写的 ...
- poj1504 Adding Reversed Numbers
Adding Reversed Numbers Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 17993 Accepted: 9 ...
- qduoj LC的课后辅导
描述 有一天,LC给我们出了一道题,如图: 这个图形从左到右由若干个 宽为1 高不确定 的小矩形构成,求出这个图形所包含的最大矩形面积. 输入 多组测试数据每组测试数据的第一行为n(0 <= n ...