Hinge Loss、交叉熵损失、平方损失、指数损失、对数损失、0-1损失、绝对值损失
损失函数(Loss function)是用来估量你模型的预测值 f(x) 与真实值 Y 的不一致程度,它是一个非负实值函数,通常用 L(Y,f(x)) 来表示。损失函数越小,模型的鲁棒性就越好。
损失函数分为经验风险损失函数和结构风险损失函数。经验风险损失函数指预测结果和实际结果的差别,结构风险损失函数是指经验风险损失函数加上正则项。通常表示为如下:(整个式子表示的意思是找到使目标函数最小时的θ值。)

常见的损失误差有6种:
- 铰链损失(Hinge Loss):主要用于支持向量机(SVM) 中;
- 交叉熵损失 (Cross Entropy Loss,Softmax Loss ):用于Logistic 回归与Softmax 分类中;
- 平方损失(Square Loss):主要是最小二乘法(OLS)中;
- 指数损失(Exponential Loss):主要用于Adaboost 集成学习算法中;
- 对数损失
- 其他损失(如0-1损失,绝对值损失)
1、Hinge损失函数(又称为max-margin loss最大边界损失)
Hinge loss 的叫法来源于其损失函数的图形,为一个折线,通用的函数表达式为:

表示如果被正确分类,损失是0,否则损失就是 1−mi(w) .

Hinge loss用于最大间隔(maximum-margin)分类,其中最有代表性的就是支持向量机SVM。在支持向量机中,最初的SVM优化的函数如下:

将约束项进行变形,则为:

则损失函数可以进一步写为:

因此, SVM 的损失函数可以看作是 L2-norm 和 Hinge loss 之和。
2、交叉熵损失
有些人可能觉得逻辑回归的损失函数就是平方损失,其实并不是。平方损失函数可以通过线性回归在假设样本是高斯分布的条件下推导得到,而逻辑回归得到的并不是平方损失。在逻辑回归的推导中,它假设样本服从伯努利分布(0-1分布),然后求得满足该分布的似然函数,接着取对数求极值等等。而逻辑回归并没有求似然函数的极值,而是把极大化当做是一种思想,进而推导出它的经验风险函数为:最小化负的似然函数
 从损失函数的视角来看,它就成了Softmax 损失函数了。
从损失函数的视角来看,它就成了Softmax 损失函数了。
log损失函数的标准形式:

刚刚说到,取对数是为了方便计算极大似然估计,因为在MLE中,直接求导比较困难,所以通常都是先取对数再求导找极值点。损失函数L(Y,P(Y|X)) 表达的是样本X 在分类Y的情况下,使概率P(Y|X) 达到最大值(换言之,就是利用已知的样本分布,找到最有可能(即最大概率)导致这种分布的参数值;或者说什么样的参数才能使我们观测到目前这组数据的概率最大)。因为log函数是单调递增的,所以logP(Y|X) 也会达到最大值,因此在前面加上负号之后,最大化P(Y|X)就等价于最小化L 了。
逻辑回归的P(Y=y|x)表达式如下(为了将类别标签y统一为1 和0 ):

其中,

3、平方损失函数
最小二乘法是线性回归的一种方法,它将回归的问题转化为了凸优化的问题。在线性回归中,它假设样本和噪声都服从高斯分布(中心极限定理),最后通过极大似然估计(MLE)可以推导出最小二乘式子。最小二乘法的基本原则是:最优拟合曲线应该使得所有点到回归直线的距离和最小。通常用欧式距离进行距离的度量。
平方损失的损失函数为:(当样本个数为N时)

Y−f(X)表示残差,整个式子表示的是残差平方和 ,我们的目标就是最小化这个目标函数值,即最小化残差的平方和。在实际应用中,我们使用均方差(MSE)作为一项衡量指标,公式如下:
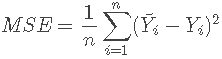
4、指数损失函数
AdaBoost就是一指数损失函数为损失函数的。
指数损失函数的标准形式:
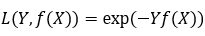
exp-loss,主要应用于 Boosting 算法中,在Adaboost 算法中,经过 m 次迭代后,可以得到 fm(x) :

Adaboost 每次迭代时的目的都是找到最小化下列式子的参数α 和G:

易知,Adabooost 的目标式子就是指数损失,在给定n个样本的情况下,Adaboost 的损失函数为:

5、log对数损失函数
Logistic回归的损失函数就是对数损失函数,在Logistic回归的推导中,它假设样本服从伯努利分布(0-1)分布,然后求得满足该分布的似然函数,接着用对数求极值。Logistic回归并没有求对数似然函数的最大值,而是把极大化当做一个思想,进而推导它的风险函数为最小化的负的似然函数。从损失函数的角度上,它就成为了log损失函数。
log损失函数的标准形式: 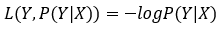
在极大似然估计中,通常都是先取对数再求导,再找极值点,这样做是方便计算极大似然估计。损失函数L(Y,P(Y|X))是指样本X在标签Y的情况下,使概率P(Y|X)达到最大值(利用已知的样本分布,找到最大概率导致这种分布的参数值)
6、0-1损失函数和绝对值损失函数
0-1损失是指,预测值和目标值不相等为1,否则为0:


参考文献:
【1】机器学习中的损失函数 (着重比较:hinge loss vs softmax loss)
Hinge Loss、交叉熵损失、平方损失、指数损失、对数损失、0-1损失、绝对值损失的更多相关文章
- 支持向量机之Hinge Loss 解释
Hinge Loss 解释 SVM 求解使通过建立二次规划原始问题,引入拉格朗日乘子法,然后转换成对偶的形式去求解,这是一种理论非常充实的解法.这里换一种角度来思考,在机器学习领域,一般的做法是经验风 ...
- SVM(支持向量机)之Hinge Loss解释
Hinge Loss 解释 SVM 求解使通过建立二次规划原始问题,引入拉格朗日乘子法,然后转换成对偶的形式去求解,这是一种理论非常充实的解法.这里换一种角度来思考,在机器学习领域,一般的做法是经验风 ...
- 深度学习面试题07:sigmod交叉熵、softmax交叉熵
目录 sigmod交叉熵 Softmax转换 Softmax交叉熵 参考资料 sigmod交叉熵 Sigmod交叉熵实际就是我们所说的对数损失,它是针对二分类任务的损失函数,在神经网络中,一般输出层只 ...
- 交叉熵理解:softmax_cross_entropy,binary_cross_entropy,sigmoid_cross_entropy简介
cross entropy 交叉熵的概念网上一大堆了,具体问度娘,这里主要介绍深度学习中,使用交叉熵作为类别分类. 1.二元交叉熵 binary_cross_entropy 我们通常见的交叉熵是二元交 ...
- 【转载】深度学习中softmax交叉熵损失函数的理解
深度学习中softmax交叉熵损失函数的理解 2018-08-11 23:49:43 lilong117194 阅读数 5198更多 分类专栏: Deep learning 版权声明:本文为博主原 ...
- 信息论随笔3: 交叉熵与TF-IDF模型
接上文:信息论随笔2: 交叉熵.相对熵,及上上文:信息论随笔 在读<数学之美>的时候,相关性那一节对TF-IDF模型有这样一句描述:"其实 IDF 的概念就是一个特定条件下.关键 ...
- 从交叉熵损失到Facal Loss
1交叉熵损失函数的由来1.1关于熵,交叉熵,相对熵(KL散度) 熵:香农信息量的期望.变量的不确定性越大,熵也就越大,把它搞清楚所需要的信息量也就越大.其计算公式如下: 其是一个期望的计算,也是记录随 ...
- DL基础补全计划(二)---Softmax回归及示例(Pytorch,交叉熵损失)
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...
- 深度学习原理与框架-Tensorflow卷积神经网络-卷积神经网络mnist分类 1.tf.nn.conv2d(卷积操作) 2.tf.nn.max_pool(最大池化操作) 3.tf.nn.dropout(执行dropout操作) 4.tf.nn.softmax_cross_entropy_with_logits(交叉熵损失) 5.tf.truncated_normal(两个标准差内的正态分布)
1. tf.nn.conv2d(x, w, strides=[1, 1, 1, 1], padding='SAME') # 对数据进行卷积操作 参数说明:x表示输入数据,w表示卷积核, stride ...
随机推荐
- Entity Framework Core的坑:Skip/Take放在Select之前造成Include的实体全表查询
今天将一个迁移至 ASP.NET Core 的项目放到一台 Linux 服务器上试运行.站点启动后,浏览器打开一个页面一直处于等待状态.接着奇怪的事情发生了,整个 Linux 服务器响应缓慢,ssh命 ...
- ESP8266 nodemcu
主要资料来源于一下几个网站 1.nodemcu官网:此处有几个示例和github(用处不大) 2.用户说明:http://nodemcu.readthedocs.io/en/master/ (非常重 ...
- Mysql thread 与 OS thread
测试环境信息如下: OS:Ubuntu 16.04 LTS Mysql:Mysql 5.7.18,使用docker images运行的实例 Mysql如何处理client请求 在Mysql中,连接管理 ...
- xpath路径表达式
简单说,xpath就是选择XML文件中节点的方法. 所谓节点(node),就是XML文件的最小构成单位,一共分成7种. - element(元素节点)- attribute(属性节点)- text ( ...
- [Day5]方法
1.方法 (1)概念:方法就是用来完成解决某件事情或实现某个功能的办法 会包含很多条语句用于完成某些有意义的功能 通过在程序代码中引用方法名称和所需的参数,实现在该程序中执行(或称调用)该方法 (2) ...
- py 正则表达式 List的使用, cxfreeze打包
从index.html当做检索出压缩文件,index.html的内容如下: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN& ...
- mysql之workbench如何只导出(insert语句)数据
https://www.jianshu.com/p/a5cd14bc5499 1. 说明: 出发点: 由于特殊原因,我们只想导出数据库中的数据(insert into语句格式的),但是在网上找到的资源 ...
- 转:Redis 3.2.1集群搭建
Redis 3.2.1集群搭建 一.概述 Redis3.0版本之后支持Cluster. 1.1.redis cluster的现状 目前redis支持的cluster特性: 1):节点自动发现 2) ...
- (转载)centos7启用端口
转载:原文地址:https://www.cnblogs.com/moxiaoan/p/5683743.html 1.firewalld的基本使用 启动: systemctl start firew ...
- java 网络编程(一)InetAddress
package cn.sasa.net; import java.net.InetAddress; import java.net.UnknownHostException; public class ...