【Hadoop学习之七】Hadoop YARN
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk8
hadoop-3.1.1
YARN:Yet Another Resource Negotiator
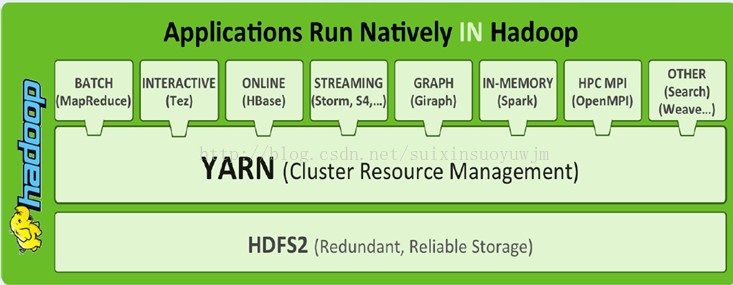
一、Yarn框架


1、概念
由于MRv1存在的问题,Hadoop 2.0新引入的资源管理系统
核心思想:将MRv1中JobTracker的资源管理和任务调度两个功能分开,分别由ResourceManager和ApplicationMaster进程实现。
(1)ResourceManager(RM):管理和分配集群的资源,是集群的一个单点,通过zookeeper来保存状态以便failover(容错)。RM主要包含两个功能组件:Applications Manager(AM)和Resource Scheduler(RS),其中AM负责接收client的作业提交的请求,为AppMaster请求Container,并且处理AppMaster的fail;RS负责在多个application之间分配资源,存在queue capacity的限制,RS调度的单位是Resource Container,一个Container是memory,cpu,disk,network的组合。Yarn支持可插拔的调度器!(处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度)
(2)ApplicationMaster(AM):每个application的master,负责和Resource Manager协商资源,将相应的Task分配到合适的Container上,并监测Task的执行情况。
(3)NodeManager(NM):部署在每个节点上的slave,负责启动container,并且检测进程组资源使用情况,单个节点上的资源管理、处理来自ResourceManager、ApplicationMaster的命令。
(4)Container:对任务运行环境的抽象。它描述一系列信息:任务运行资源(包括节点、内存、CPU)、任务启动命令、任务运行环境
2、运行过程
(1)用户通过JobClient向RM提交作业
(2)RM为AM分配Container,并请求NM启动AM
(3)AM启动后向RM协商Task的资源
(4)获得资源后AM通知NM启动Task
(5)Task启动后向AM发送心跳,更新进度、状态和出错信息

3、YARN容器框架能够支撑多种计算引擎运行,包括传统的Hadoop MR和现在的比较新的SPARK。 为各种框架进行资源分配和提供运行时环境。
(1)配置hadoop-env.sh
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
(2)配置etc/hadoop/mapred-site.xml
mapreduce.framwork.name:代表mapreduce的运行时环境,默认是local,需配置成yarn
mapreduce.application.classpath:Task的classpath
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
etc/hadoop/yarn-site.xml:
yarn.nodemanager.aux-services:代表附属服务的名称,如果使用mapreduce则需要将其配置为mapreduce_shuffle
yarn.nodemanager.env-whitelist:环境变量白名单,container容器可能会覆盖的环境变量,而不是使用NodeManager的默认值
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
(3)修改workers配置nodemanager的节点
node1
(4)启动
[root@node1 hadoop]# /usr/local/hadoop-3.1./sbin/start-yarn.sh
Starting resourcemanager
Starting nodemanagers
[root@node1 hadoop]# jps
Jps
ResourceManager
NodeManager
验证:

(5)关闭
[root@node1 hadoop]# /usr/local/hadoop-3.1./sbin/stop-yarn.sh
Stopping nodemanagers
Stopping resourcemanager
(1)配置hadoop-env.sh(node1)
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
(2)配置etc/hadoop/mapred-site.xml (node1)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
etc/hadoop/yarn-site.xml(node1):
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--启用HA集群-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--YARN HA集群标识-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<!--YARN HA集群里Resource Managers清单-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!--YARN HA集群里Resource Manager 对应节点-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node3</value>
</property>
<!--YARN HA集群里Resource Manager 对应节点-->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node4</value>
</property>
<!--YARN HA集群里Resource Manager WEB 主机端口-->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node3:</value>
</property>
<!--YARN HA集群里Resource Manager WEB 主机端口-->
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node4:</value>
</property>
<!--YARN HA集群里ZK清单-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>zk1:,zk2:,zk3:</value>
</property>
</configuration>
(3)修改workers配置nodemanager的节点
node2
node3
node4
将以上三步修改的文件分发到node2、node3、node4
(4)启动
(4.1)node1启动node2、node3、node4上的NodeManager
[root@node1 hadoop]# /usr/local/hadoop-3.1./sbin/start-yarn.sh
(4.2)node3、node4启动ResourceManager
[root@node3 hadoop]# /usr/local/hadoop-3.1./sbin/yarn-daemon.sh start resourcemanager
[root@node4 hadoop]# /usr/local/hadoop-3.1./sbin/yarn-daemon.sh start resourcemanager
验证:
http://node3:8088

NM只和Active RM交互资源信息

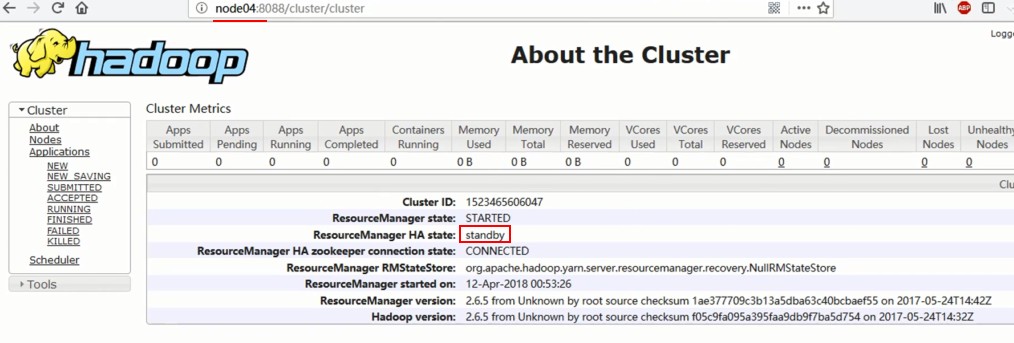
http://node4:8088 会跳转到node3

http://node4:8088/cluster/cluster (会显示node4为备机)
(5)关闭
[root@node1 hadoop]# /usr/local/hadoop-3.1.1/sbin/stop-yarn.sh
[root@node3 hadoop]# /usr/local/hadoop-3.1.1/sbin/yarn-daemon.sh stop resourcemanager
[root@node4 hadoop]# /usr/local/hadoop-3.1.1/sbin/yarn-daemon.sh stop resourcemanager
参考:
https://blog.csdn.net/suixinsuoyuwjm/article/details/22984087
https://www.cnblogs.com/sammyliu/p/4396162.html
HA搭建:https://blog.csdn.net/afgasdg/article/details/79277926
【Hadoop学习之七】Hadoop YARN的更多相关文章
- Hadoop学习之Hadoop集群搭建
1.检查网络状况 Dos命令:ping ip地址,同时,在Linux下通过命令:ifconfig可以查看ip信息2.修改虚拟机的ip地址 打开linux网络连接,在桌面右上角,然后编辑ip地址, ...
- hadoop学习;hadoop伪分布搭建
先前已经做了准备工作安装jdk什么的,以下開始ssh免password登陆.这里我们用的是PieTTY工具,当然你也能够直接在linux下直接操作 ssh(secure shell),运行命令 ssh ...
- Hadoop学习笔记——Hadoop经常使用命令
Hadoop下有一些经常使用的命令,通过这些命令能够非常方便操作Hadoop上的文件. 1.查看指定文件夹下的内容 语法: hadoop fs -ls 文件文件夹 2.打开某个已存在的文件 语法: h ...
- 二十六、Hadoop学习笔记————Hadoop Yarn的简介复习
1. 介绍 YARN(Yet Another Resource Negotiator)是一个通用的资源管理平台,可为各类计算框架提供资源的管理和调度. 之前有提到过,Yarn主要是为了减轻Hadoop ...
- hadoop学习之hadoop完全分布式集群安装
注:本文的主要目的是为了记录自己的学习过程,也方便与大家做交流.转载请注明来自: http://blog.csdn.net/ab198604/article/details/8250461 要想深入的 ...
- Hadoop学习之Hadoop案例分析
一.日志数据分析1.背景1.1 ***论坛日志,数据分为两部分组成,原来是一个大文件,是56GB:以后每天生成一个文件,大约是150-200MB之间: 每行记录有5部分组成:1.访问ip:2.访问时间 ...
- Hadoop学习笔记Hadoop伪分布式环境建设
建立一个伪分布式Hadoop周围环境 1.主办(Windows)顾客(安装在虚拟机Linux)网络连接. a) Host-only 主机和独立客户端联网: 好处:网络隔离: 坏处:虚拟机和其他serv ...
- Hadoop学习之YARN框架
转自:http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/,非常感谢分享! 对于业界的大数据存储及分布式处理系统来说,H ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
随机推荐
- swift 桥接 Bridging 的创建和使用
swift编程时,大概率会用到OC的文件,这时就要使用swift与oc的桥接文件.桥接文件以 XXXX-Bridging-header.h 这样子的文件名形式为标准,XXXX是你的项目名字. 具体 ...
- fdisk vs df
fdisk工具是分区工具:df是用来查看文件系统(分区)的使用情况的! 当用来查看分区信息时,较为相似: fdisk侧重于显示分区表的信息: df侧重于显示当前系统中所有文件系统的信息: 常用用法: ...
- JavaScript学习(七)
- 【托业】【新托业TOEIC新题型真题】学习笔记7-题库二->P1~4
P1: 1. shopping cart 购物车 stock the shelves 补货 examining the vegetables 挑选蔬菜 4.admire some paintings ...
- MongoDB update修改器: 针对Arrays的$修改器 $push $pull $pop
针对Arrays的$修改器 $push : { $push: { key: value } } 它是用来对Array (list)数据类型进行 增加 新元素的,相当于我们Python中 list.ap ...
- 008-ThreadLocal原理分析
一.简介 早在JDK 1.2的版本中就提供java.lang.ThreadLocal,ThreadLocal为解决多线程程序的并发问题提供了一种新的思路.使用这个工具类可以很简洁地编写出优美的多线程程 ...
- 【Java】-NO.17.EBook.4.Java.1.014-【疯狂Java讲义第3版 李刚】- Annotation
1.0.0 Summary Tittle:[Java]-NO.17.EBook.4.Java.1.014-[疯狂Java讲义第3版 李刚]- Annotation Style:EBook Serie ...
- Centos ssh 限制ip访问
要确定客户端计算机是否允许连接到服务,TCP包装器将引用以下两个文件,这两个文件通常称为主机访问文件: /etc/hosts.allow /etc/hosts.deny 当TCP包裹服务接收到客户端请 ...
- Laravel中路由怎么写(一)
1.路由基本使用示例 1.1 默认示例 Laravel中所有路由定义在/app/Http/routes.php文件中,该文件默认定义了应用的首页路由: Route::get('/', function ...
- jquery dataTables例子
https://datatables.net/examples/styling/bootstrap.html http://datatables.club/example/#styling http: ...