分布式计算(二)使用Sqoop实现MySQL与HDFS数据迁移
近期接触了一个需求,业务背景是需要将关系型数据库的数据传输至HDFS进行计算,计算完成后再将计算结果传输回关系型数据库。听到这个背景,脑海中就蹦出了Sqoop迁移工具,可以非常完美的支持上述场景。
当然,数据传输工具还有很多,例如Datax、Kettle等等,大家可以针对自己的工作场景选择适合自己的迁移工具。
目录
一、介绍
二、架构
三、安装
1. 下载Sqoop
2. 配置环境变量
四、操作
1. 列出数据库
2. 列出数据表
3. MySQL导入到HDFS
4. HDFS导出到MySQL
一、介绍
Sqoop的命名,仔细一看是不是有点像 sql 和 hadoop 两个词语的拼接产物。其实从它的命名来看也就很明显,Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如:MySQL、Oracle、Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。对于某些NoSQL数据库它也提供了连接器。Sqoop,类似于其他ETL工具,使用元数据模型来判断数据类型并在数据从数据源转移到Hadoop时确保类型安全的数据处理。Sqoop专为大数据批量传输设计,能够分割数据集并创建Hadoop任务来处理每个区块。
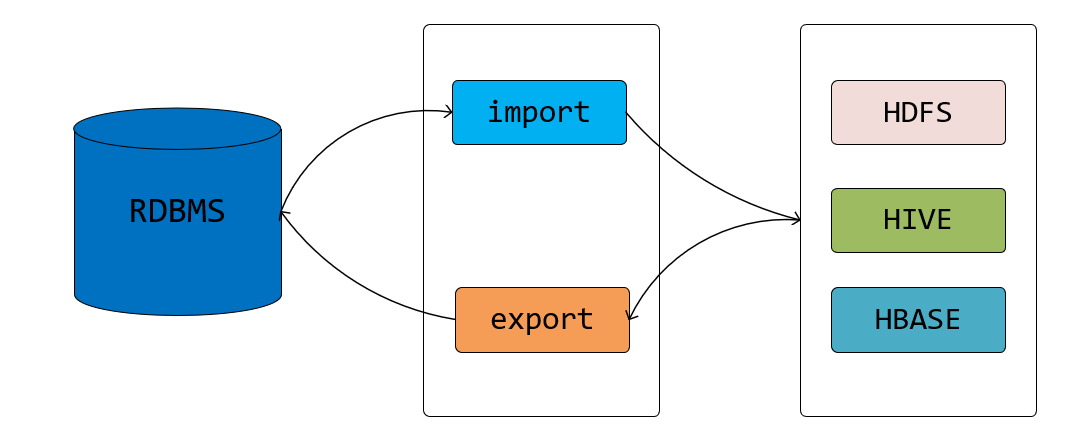
从关系型数据库到 hadoop 我们称之为 import,从 hadoop 到关系型数据库我们称之为 export。文章后面大家就会看到 "import"、"export" 对应命令的两个模式。
二、架构
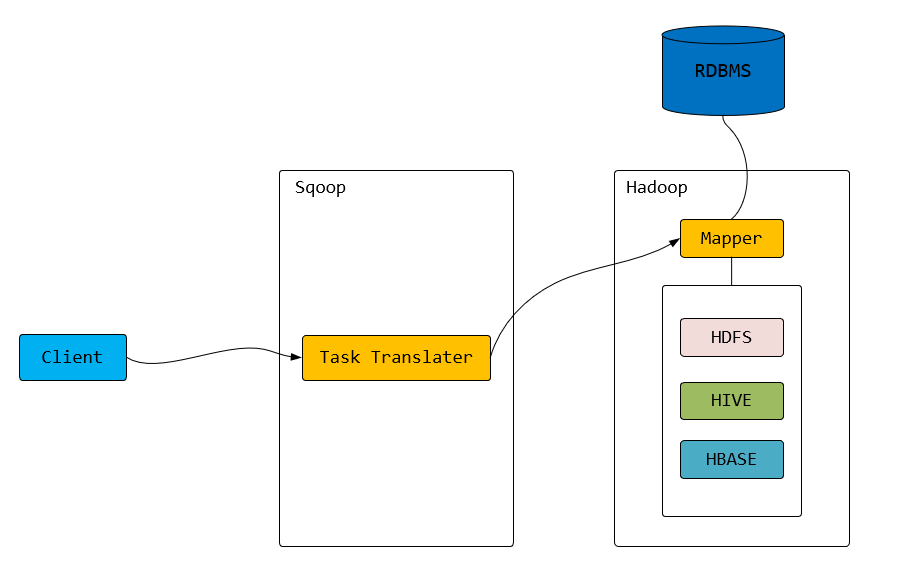
三、安装
前提:已经安装好JDK和Hadoop集群,若没安装,请参考:分布式计算(一)Ubuntu搭建Hadoop分布式集群
1. 下载Sqoop
Sqoop安装包可以从官网下载:http://sqoop.apache.org/
从官网可以看到,Sqoop有两个大的版本:Sqoop1和Sqoop2。
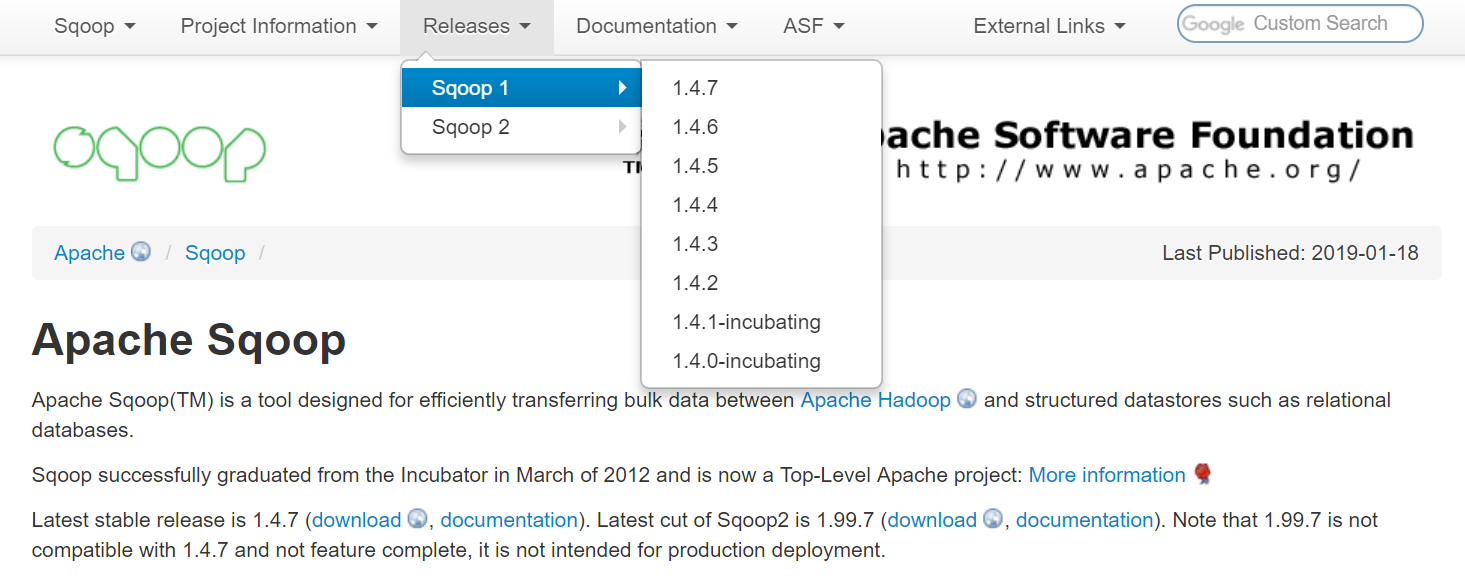
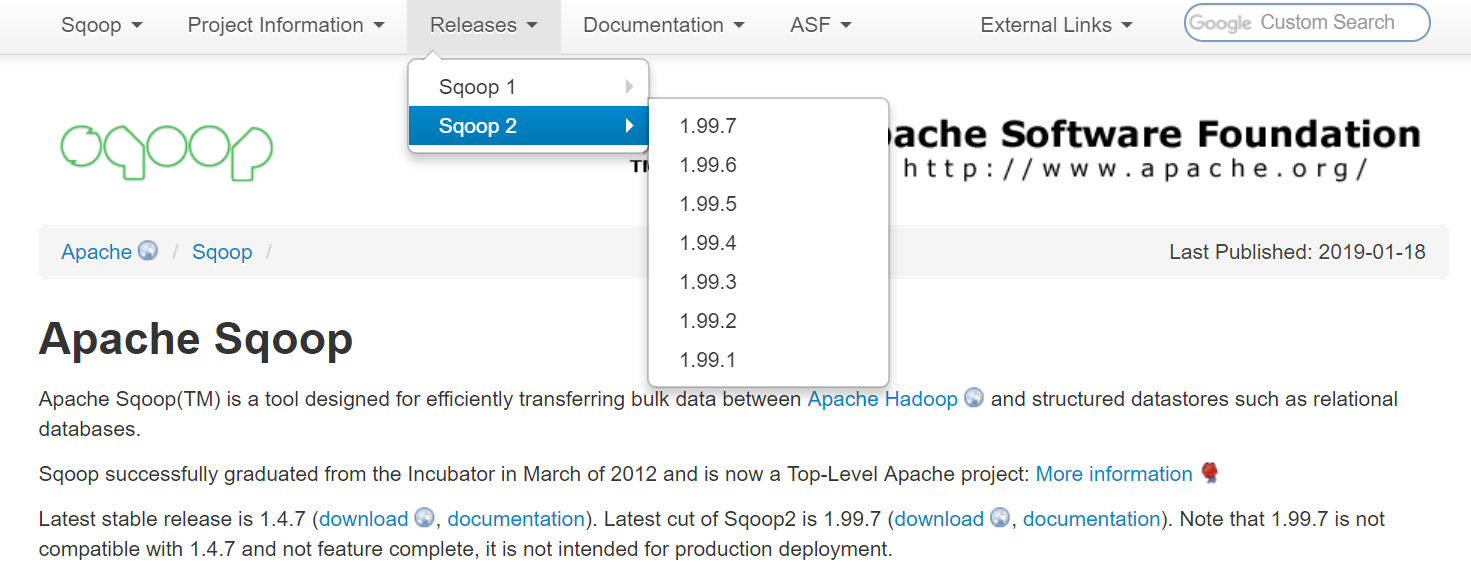
1.4.x 的为 Sqoop1,1.99.X 为 Sqoop2。
关于 Sqoop1 与 Sqoop2 的区别,通俗来讲就是:
- sqoop1 只是一个客户端工具,Sqoop2 加入了 Server 来集中化管理连接器
- Sqoop1 通过命令行来工作,工作方式单一,Sqoop2 则有更多的方式来工作,比如 REST api接口、Web 页
- Sqoop2 加入权限安全机制
对于笔者来说,Sqoop 就是一个同步工具,命令行足够满足工作需求,并且大部分数据同步都是在同一个局域网内部(也就没有数据安全之类问题),所以选择的是 Sqoop1(具体版本是 1.4.7)。
下载好了之后,在你想安装的路径下进行解压, 这里选择将Hadoop 安装到当前路径下:
# tar xvzf sqoop-1.4..bin__hadoop-2.6..tar.gz
# mv sqoop-1.4..bin__hadoop-2.6. sqoop
2. 配置环境变量
# vi /etc/profile export SQOOP_HOME=/root/sqoop
export PATH=$PATH:$SQOOP_HOME/bin
使得sqoop命令在当前终端立即生效
# source /etc/profile
配置好环境变量后,将数据库连接驱动放入 $SQOOP_HOME/lib 目录中。这里使用的是MySQL数据库,选择的MySQL连接驱动mysql-connector-java-5.1.46.jar ,当然,如果你使用的是其他关系型数据库,相应的就需要导入其他关系型数据库的jar包。
四、操作
了解了 Sqoop 是什么,能做什么以及大概的框架原理,接下来我们直接使用 Sqoop 命令来感受一下使用 Sqoop 是如何简单及有效。本文案例中的关系型数据库使用的是 MySQL,Oracle 以及其他使用 jdbc 连接的关系型数据库操作类似,差别不大。
运行 sqoop help 可以看到 Sqoop 提供了哪些操作
# sqoop help
// :: INFO sqoop.Sqoop: Running Sqoop version: 1.4.
usage: sqoop COMMAND [ARGS] Available commands:
codegen Generate code to interact with database records
create-hive-table Import a table definition into Hive
eval Evaluate a SQL statement and display the results
export Export an HDFS directory to a database table
help List available commands
import Import a table from a database to HDFS
import-all-tables Import tables from a database to HDFS
import-mainframe Import datasets from a mainframe server to HDFS
job Work with saved jobs
list-databases List available databases on a server
list-tables List available tables in a database
merge Merge results of incremental imports
metastore Run a standalone Sqoop metastore
version Display version information See 'sqoop help COMMAND' for information on a specific command.
这些操作其实都会一一对应到 sqoop bin 目录下的一个个可运行脚本文件,如果想了解细节,可以打开这些脚本进行查看
# ll bin/
total
drwxr-xr-x Dec ./
drwxr-xr-x Dec ../
-rwxr-xr-x Dec configure-sqoop*
-rwxr-xr-x Dec configure-sqoop.cmd*
-rwxr-xr-x Dec sqoop*
-rwxr-xr-x Dec sqoop.cmd*
-rwxr-xr-x Dec sqoop-codegen*
-rwxr-xr-x Dec sqoop-create-hive-table*
-rwxr-xr-x Dec sqoop-eval*
-rwxr-xr-x Dec sqoop-export*
-rwxr-xr-x Dec sqoop-help*
-rwxr-xr-x Dec sqoop-import*
-rwxr-xr-x Dec sqoop-import-all-tables*
-rwxr-xr-x Dec sqoop-import-mainframe*
-rwxr-xr-x Dec sqoop-job*
-rwxr-xr-x Dec sqoop-list-databases*
-rwxr-xr-x Dec sqoop-list-tables*
-rwxr-xr-x Dec sqoop-merge*
-rwxr-xr-x Dec sqoop-metastore*
-rwxr-xr-x Dec sqoop-version*
-rwxr-xr-x Dec start-metastore.sh*
-rwxr-xr-x Dec stop-metastore.sh*
工作中一般常用的几个操作或者命令如下:
- list-databases : 查看有哪些数据库
- list-tables : 查看数据库中有哪些表
- import : 关系型数据库到 hadoop 数据同步
- export : hadoop 到关系型数据库数据同步
- version :查看 Sqoop 版本
1. 列出数据库
# sqoop list-databases --connect jdbc:mysql://192.168.1.123:3306/?useSSL=false --username root --password 12345678
2. 列出数据表
# sqoop list-tables --connect jdbc:mysql://192.168.1.123:3306/databasename?useSSL=false --username root --password 12345678
3. MySQL导入HDFS
# sqoop import
--connect jdbc:mysql://192.168.1.123:3306/databasename?useSSL=false
--username root
--password
--table product
--target-dir /hadoopDir/
--fields-terminalted-by '\t'
-m
--columns 'PRODUCT_ID,PRODUCT_NAME,LIST_PRICE,QUANTITY,CREATE_TIME'
--last-value num
--incremental append
--where 'QUANTITY > 500'
| 选项 | 说明 |
| --connect | 数据库的 JDBC URL,后面的 databasename 想要连接的数据库名称 |
| --table | 数据库表 |
| --username | 数据库用户名 |
| --password | 数据库密码 |
| --target-dir | HDFS 目标目录,不指定,默认和数据库表名一样 |
| --fields-terminated-by | 数据导入后每个字段之间的分隔符,不指定,默认为逗号 |
| -m | mapper 的并发数量 |
| --columns | 指定导入时的参考列,这里是PRODUCT_ID,PRODUCT_NAME,LIST_PRICE,QUANTITY,CREATE_TIME |
| --last-value | 上一次导入的最后一个值 |
| --incremental append | 导入方式为增量 |
| --where | 按条件筛选数据,where条件的内容必须在单引号内 |
注意:工作中需要增量同步的场景下,我们就可以使用 --incremental append 以及 --last-value。比如这里我们使用 id 来作为参考列,如果上次同步到了 1000, 这次我们想只同步新的数据,就可以带上参数 --last-value 1000。
4. HDFS导出MySQL
# sqoop export
--connect 'jdbc:mysql://192.168.1.123:3306/databasename?useSSL=false&useUnicode=true&characterEncoding=utf-8'
--username root
--password ''
--table product
--m
--export-dir /hadoopDir/
--input-fields-terminated-by '\t'
--columns 'PRODUCT_ID,PRODUCT_NAME,LIST_PRICE,QUANTITY,CREATE_TIME'
HDFS导出到MySQL时,数据有可能乱码,此时需要在--connect参数中指定编码。
问题
1. Sqoop配置好后,执行sqoop命令会出现以下日志:
# sqoop job -list
Warning: /root/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /root/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /root/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /root/sqoop/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
// :: INFO sqoop.Sqoop: Running Sqoop version: 1.4.
Available jobs:
此时只需要在sqoop的安装路径下创建hbase、hcatalog、accumulo、zookeeper的空目录即可解决问题。
Mysql 与 hadoop 数据同步(迁移),你需要知道 Sqoop
分布式计算(二)使用Sqoop实现MySQL与HDFS数据迁移的更多相关文章
- hive、sqoop、MySQL间的数据传递
hdfs到MySQL csv/txt文件到hdfs MySQL到hdfs hive与hdfs的映射: drop table if exists emp;create table emp ( id i ...
- HDFS数据迁移解决方案之DistCp工具的巧妙使用
前言 在当今每日信息量巨大的社会中,源源不断的数据需要被安全的存储.等到数据的规模越来越大的时候,也许瓶颈就来了,没有存储空间了.这时候怎么办,你也许会说,加机器解决,显然这是一个很简单直接但是又显得 ...
- django 连接MYSQL时,数据迁移时报:django.db.utils.InternalError: (1366, "Incorrect string value: '\\xE9\\x97\\xAE\\xE9\\xA2\\x98' for column 'name' at row 5")
django 连接MYSQL时,数据迁移时报:django.db.utils.InternalError: (1366, "Incorrect string value: '\\xE9\\x ...
- Mongodb到mysql数据库的数据迁移(Java,Windows)
运行环境为windows 测试过260万的数据表,迁移大概要10分钟左右,当然肯定和网络,字段大小什么的有关系. 遇到的坑和注意点都用紫色标记了(对,就是我大乃团的高冷紫--Nogizaka 46) ...
- mysql搭建及数据迁移教程
1.如果jumbo不存在,先安装jumbo 参考 http://hetu.baidu.com/api/tool/show?toolId=174: bash -c "$( curl htt ...
- HDFS数据迁移目录到正确姿势
添加了一块硬盘,原来的DataNode已经把原有的硬盘占满:怎么办,想要把旧有的数据迁移到新的硬盘上面: 1. 在CDH中修改目录(在HDFS组件中搜索.dir),本例中,新加的硬盘挂载在/data上 ...
- 使用Sqoop从mysql向hdfs或者hive导入数据时出现的一些错误
1.原表没有设置主键,出现错误提示: ERROR tool.ImportTool: Error during import: No primary key could be found for tab ...
- hadoop hdfs 数据迁移到其他集群
# hadoop fs -cat /srclist Warning: $HADOOP_HOME is deprecated. hdfs://sht-sgmhadoopcm-01:9011/jdk-6u ...
- Django项目与mysql交互进行数据迁移时报错:AttributeError: 'str' object has no attribute 'decode'
问题描述 Django项目启动,当我们执行命令 python manage.py makemigrations 出现如下错误: File , in last_executed_query query ...
随机推荐
- 【Dubbo&&Zookeeper】6、 给dubbo接口添加白名单——dubbo Filter的使用
在开发中,有时候需要限制访问的权限,白名单就是一种方法.对于Java Web应用,Spring的拦截器可以拦截Web接口的调用:而对于dubbo接口,Spring的拦截器就不管用了. dubbo提供了 ...
- Java 内部类的简单介绍
内部类的三种分类(成员内部类,局部内部类,匿名内部类) 1.成员内部类 (类似于成员变量和成员方法) 在类的外部类的方法中去调用内部类 输出结果: 另一种直接在别的类中使用内部类,不过需要先创建外部 ...
- Django Rest framework 之 节流
RESTful 规范 django rest framework 之 认证(一) django rest framework 之 权限(二) django rest framework 之 节流(三) ...
- Harbor 搜索镜像及查看 tag
在我们搭建完 Harbor 后: https://www.cnblogs.com/klvchen/p/9482153.html 如果想要通过 API 获取 Harbor 上面的镜像及 tag 可以使用 ...
- Ps—导出:sql作业配合ps导出csv文件
$dateText=Get-Date #获取当前日期时间 $dateText = $dateText.ToShortDateString() #转为短日期格式(去掉时间部分) $checkDate=( ...
- ES6模块化与常用功能
目前开发环境已经普及使用,如vue,react等,但浏览器环境却支持不好,所以需要开发环境编译,下面介绍下开发环境的使用和常用语法: 一,ES6模块化 1,模块化的基本语法 ES6 的模块自动采用严格 ...
- Salesforce小知识:累计汇总字段类型
累计汇总字段类型的定义 Salesforce中可以在两个对象之间建立关系.一个对象的某一条记录可以有若干条相关联的其他对象记录. 累计汇总字段可以将这些相关联的记录中的某些字段值汇总起来,显示给用户. ...
- Android--清除默认桌面设置和设置默认桌面(转)
http://blog.csdn.net/chaozhung_no_l/article/details/49929177 转自这位大神的博客,感谢这位大神,帮了大忙,谢谢!!
- (网页)在SQL Server中为什么不建议使用Not In子查询(转)
转自博客园宋沄剑 英文名:CareySon : 在SQL Server中,子查询可以分为相关子查询和无关子查询,对于无关子查询来说,Not In子句比较常见,但Not In潜在会带来下面两种问题: ...
- 我的简历 PHP Java C# 技术总监
石先生 ID:303321266 目前正在找工作 13611326258 hr_msn@163.com 男|32 岁 (1985/08/06)|现居住北京-海淀区|12年工作经验 ...