Kafka 2.1.0压缩算法性能测试
Apache Kafka 2.1.0正式支持ZStandard —— ZStandard是Facebook开源的压缩算法,旨在提供超高的压缩比(compression ratio),具体细节参见https://facebook.github.io/zstd/。本文对Kafka支持的这几种压缩算法(GZIP、Snappy、LZ4、ZStandard)做了一下基本的性能测试,希望能够以不同维度去衡量不同压缩算法在Kafka中的表现。
一、环境准备
本次测试使用了两台云主机,一台作为Kafka的服务器,跑broker进程;另一台作为client,运行Kafka的客户端程序(producer和consumer),具体配置如下:

软件配置如下:

二、测试topic准备
依次创建4个topic:test1、test2、test3、test4,分别用于LZ4、ZStandard、Snappy和GZIP的测试,这些topic都是单分区单副本。
三、测试producer端
使用kafka-producer-perf-test.sh脚本依次为4个topic发送60,000,000条消息,每条消息1KB大小,去计算各种压缩算法的TPS以及其他指标。结果如下:
1、客户端CPU使用率统计图
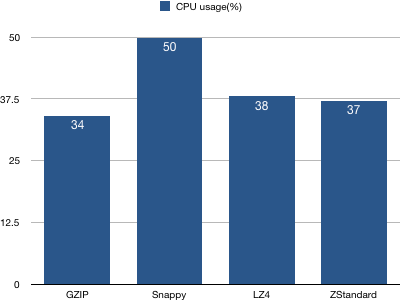
结论:Snappy算法使用的CPU资源最多,其他3种压缩算法相差不多。
2、Broker服务器带宽统计
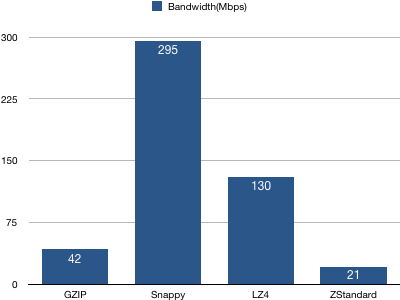
结论:Snappy算法占用的带宽最多且遥遥领先,LZ4次之,而新引入的ZStandard使用的带宽最少。一个可能的原因是ZStandard有较高的压缩比,减少了总体的网络IO传输量。
3、producer吞吐量(TPS)统计
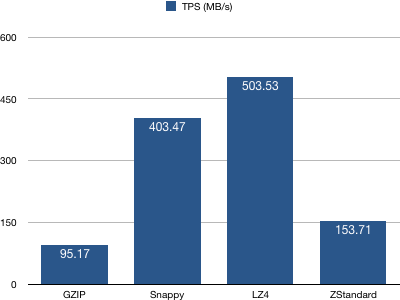
结论:配置LZ4的producer TPS最高——LZ4算法有着最快的压缩时间(至少是top3),故整体TPS最高也不令人惊讶。Snappy次之,ZStandard位居第三位。说明ZStandard不是一个很快的压缩算法。
4、producer延时分布统计
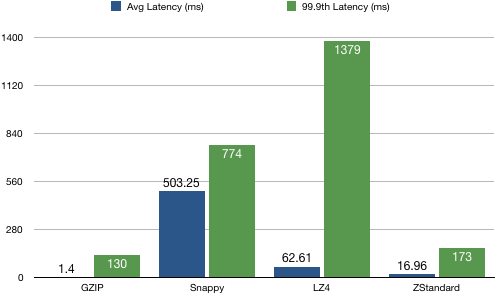
结论:GZIP算法的延时最低,ZStandard次之。有意思的是,Snappy算法的平均值和99.9分位均值比较接近,而LZ4算法方差较大(当然也可能因为异常点导致)。总之从延时角度来看GZIP最优。
5、磁盘占用统计
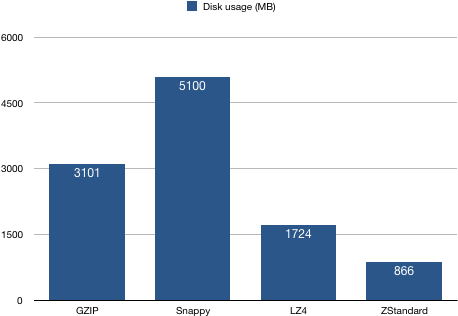
结论:配置ZStandard算法producer生产的消息有着最高的压缩比,这符合ZStandard算法官方的定位:"Zstd can trade compression speed for stronger compression ratios." —— 即该算法牺牲一部分压缩速度去换取更高的压缩比。
四、测试consumer端
使用kafka-consumer-perf-test.sh脚本依次消费4个topic,每个topic消费60,000,000条消息,去计算consumer端解压缩性能以及其他核心指标,结果如下:
1、客户端CPU使用率统计
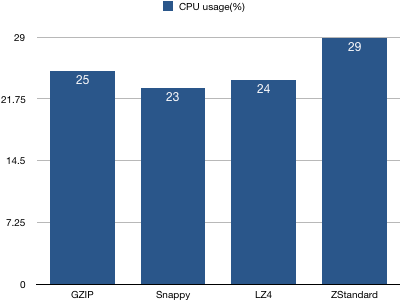
结论:基本上4种压缩算法的客户端CPU使用率基本持平,ZStandard算法略高一些
2、Broker端带宽占用统计

结论:Snappy占用带宽最多,ZStandard最少——同理,这是因为ZStandard有最高的压缩比,极大地降低了网络IO传输量。
3、consumer吞吐量(TPS)统计
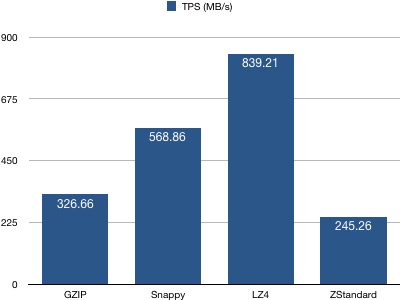
结论:配置LZ4算法的consumer有着最高的TPS,而ZStandard算法最低。
五、总结
相比于其他压缩算法,ZStandard有着最高的压缩比,相同的消息量占用最少的磁盘容量,因此带宽的占用也是比较少的,但是在TPS方面的表现并不抢眼,因此对于那些在乎磁盘和带宽资源的用户而言,配置ZStandard算法似乎是个不错的选择,但如果追求应用TPS,就目前的Kafka而言LZ4依然是最好的选择。
Kafka 2.1.0压缩算法性能测试的更多相关文章
- 发行说明 - Kafka - 版本1.0.0
发行说明 - Kafka - 版本1.0.0 以下是Kafka 1.0.0发行版中解决的JIRA问题的摘要.有关该版本的完整文档,入门指南以及有关该项目的信息,请参阅Kafka项目网站. 有关升级的注 ...
- _00017 Kafka的体系结构介绍以及Kafka入门案例(0基础案例+Java API的使用)
博文作者:妳那伊抹微笑 itdog8 地址链接 : http://www.itdog8.com(个人链接) 博客地址:http://blog.csdn.net/u012185296 博文标题:_000 ...
- Windows下Kafka 2.3.0的下载和安装
Kafka是由Apache软件基金会开发的一个开源流处理平台,是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据. 特性:(1)通过O(1)的磁盘数据结构提供消息的持久化 ...
- Kafka 2.5.0发布——弃用对Scala2.11的支持
近日Kafka发布了最新版本 2.5.0,增加了很多新功能: 下载地址:https://kafka.apache.org/downloads#2.5.0 对TLS 1.3的支持(默认为1.2) 引入用 ...
- Kafka Eagle V2.0.0新版预览
1.概述 Kafka Eagle是一款用于管理Kafka的监控系统,且完全开源.当前Kafka Eagle发布了2.0.0版本.今天笔者就为大家来介绍一下2.0.0更新了哪些功能. 官网地址:http ...
- Kafka Eagle 3.0.1功能预览
1.概述 最近有同学留言,关于Kafka Eagle的一些使用问题.今天笔者就为大家来详细介绍Kafka Eagle 3.0.1的功能以及使用方法. 2.内容 在3.0.1版本中,EFAK优化了分布式 ...
- Spark Streaming + Kafka整合(Kafka broker版本0.8.2.1+)
这篇博客是基于Spark Streaming整合Kafka-0.8.2.1官方文档. 本文主要讲解了Spark Streaming如何从Kafka接收数据.Spark Streaming从Kafka接 ...
- Structured Streaming + Kafka Integration Guide 结构化流+Kafka集成指南 (Kafka broker version 0.10.0 or higher)
用于Kafka 0.10的结构化流集成从Kafka读取数据并将数据写入到Kafka. 1. Linking 对于使用SBT/Maven项目定义的Scala/Java应用程序,用以下工件artifact ...
- scala spark(2.10)读取kafka(2.11_1.0.0)示例
1.pom加载jar包 <dependency> <groupId>org.apache.spark</groupId> <artifactId>spa ...
随机推荐
- h5本地缓存(localStorage,sessionStorage)
H5本地存储数据 localStorage,sessionStorage的区别: 相同点: 缓存数据比cookie的范围大; localStorage:关闭浏览器数据不会消失,除非手动删除数据 se ...
- Ruby面向对象
Ruby面向对象 Ruby是真正的面向对象语言,一切皆为对象,甚至基本数据类型都是对象 基本用法 class Box # 构造函数 def initialize(w,h) @with, @heig ...
- consul 文档
consul 服务发现 服务发现,用docker的时候可以使用,并且可以实现负载均衡. 因业务需要,所以留一下自己搜到比较好的资料吧 英文:https://www.consul.io/intro/ge ...
- sublime项目的添加删除
方便多个项目之间切换修改代码
- mysql 创建用户命令-grant
我们在使用mysql的过程中,经常需要对用户授权(添加,修改,删除),在mysql当中有三种方式实现 分别是 INSERT USER表的方法.CREATE USER的方法.GRANT的方法.今天主要看 ...
- Asp.Net 自定义设置Http缓存示例(一)
一.自定义图片输出,启用客户端的图片缓存处理 代码示例: string path = Request.Url.LocalPath; if (path != null) { path = path.To ...
- [oracle] Oracle存储过程里操作BLOB的字节数据的办法,例如写入32位整数
作者: zyl910 一.缘由 BLOB是指二进制大对象,也就是英文Binary Large Object的缩写. 在很多时候,我们是通过其他编程语言(如Java)访问BLOB的字节数据,进行字节级的 ...
- 洛谷P1048 采药
题目OJ地址 https://www.luogu.org/problemnew/show/P1048 https://vijos.org/p/1104 题目描述辰辰是个天资聪颖的孩子,他的梦想是成为世 ...
- 单片机成长之路(51基础篇) - 007 CH340CH341最全说明
比较全的CH340,CH341应用说明 CH340 以前用USB转串口时图方便一般也都是直接买现成的USB转串口模块,但是后面设计需要,不等不将CH340这个模块集成到电路板中,经过多次失败,终于得到 ...
- Python之数学题目练习
首先,下面的题目来自我的大学同学的分享,他用数学证明,我用编程计算机发现了答案. 他的数学推理: 然后下面是我的Python代码: #coding=utf-8 # 井的高度 well_hegith = ...