Kafka 2.1.0压缩算法性能测试
Apache Kafka 2.1.0正式支持ZStandard —— ZStandard是Facebook开源的压缩算法,旨在提供超高的压缩比(compression ratio),具体细节参见https://facebook.github.io/zstd/。本文对Kafka支持的这几种压缩算法(GZIP、Snappy、LZ4、ZStandard)做了一下基本的性能测试,希望能够以不同维度去衡量不同压缩算法在Kafka中的表现。
一、环境准备
本次测试使用了两台云主机,一台作为Kafka的服务器,跑broker进程;另一台作为client,运行Kafka的客户端程序(producer和consumer),具体配置如下:

软件配置如下:

二、测试topic准备
依次创建4个topic:test1、test2、test3、test4,分别用于LZ4、ZStandard、Snappy和GZIP的测试,这些topic都是单分区单副本。
三、测试producer端
使用kafka-producer-perf-test.sh脚本依次为4个topic发送60,000,000条消息,每条消息1KB大小,去计算各种压缩算法的TPS以及其他指标。结果如下:
1、客户端CPU使用率统计图
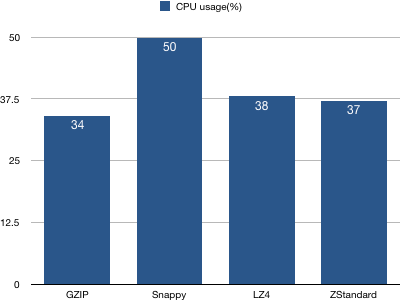
结论:Snappy算法使用的CPU资源最多,其他3种压缩算法相差不多。
2、Broker服务器带宽统计
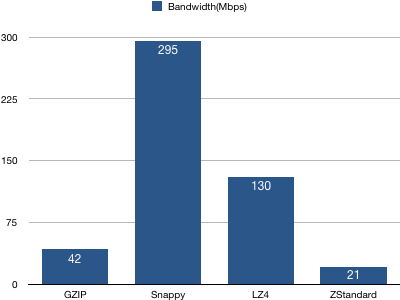
结论:Snappy算法占用的带宽最多且遥遥领先,LZ4次之,而新引入的ZStandard使用的带宽最少。一个可能的原因是ZStandard有较高的压缩比,减少了总体的网络IO传输量。
3、producer吞吐量(TPS)统计
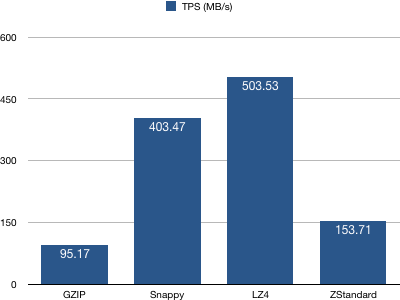
结论:配置LZ4的producer TPS最高——LZ4算法有着最快的压缩时间(至少是top3),故整体TPS最高也不令人惊讶。Snappy次之,ZStandard位居第三位。说明ZStandard不是一个很快的压缩算法。
4、producer延时分布统计
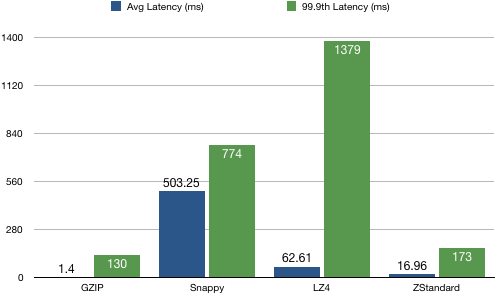
结论:GZIP算法的延时最低,ZStandard次之。有意思的是,Snappy算法的平均值和99.9分位均值比较接近,而LZ4算法方差较大(当然也可能因为异常点导致)。总之从延时角度来看GZIP最优。
5、磁盘占用统计
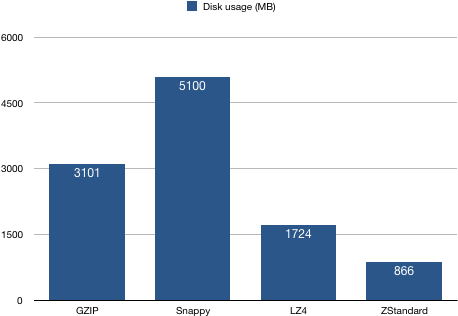
结论:配置ZStandard算法producer生产的消息有着最高的压缩比,这符合ZStandard算法官方的定位:"Zstd can trade compression speed for stronger compression ratios." —— 即该算法牺牲一部分压缩速度去换取更高的压缩比。
四、测试consumer端
使用kafka-consumer-perf-test.sh脚本依次消费4个topic,每个topic消费60,000,000条消息,去计算consumer端解压缩性能以及其他核心指标,结果如下:
1、客户端CPU使用率统计
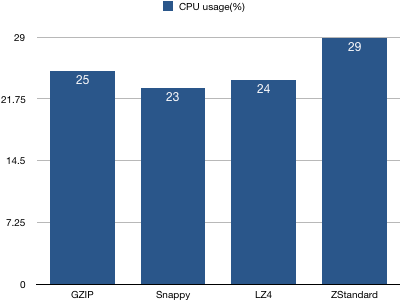
结论:基本上4种压缩算法的客户端CPU使用率基本持平,ZStandard算法略高一些
2、Broker端带宽占用统计

结论:Snappy占用带宽最多,ZStandard最少——同理,这是因为ZStandard有最高的压缩比,极大地降低了网络IO传输量。
3、consumer吞吐量(TPS)统计
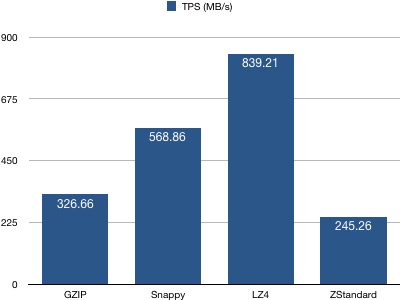
结论:配置LZ4算法的consumer有着最高的TPS,而ZStandard算法最低。
五、总结
相比于其他压缩算法,ZStandard有着最高的压缩比,相同的消息量占用最少的磁盘容量,因此带宽的占用也是比较少的,但是在TPS方面的表现并不抢眼,因此对于那些在乎磁盘和带宽资源的用户而言,配置ZStandard算法似乎是个不错的选择,但如果追求应用TPS,就目前的Kafka而言LZ4依然是最好的选择。
Kafka 2.1.0压缩算法性能测试的更多相关文章
- 发行说明 - Kafka - 版本1.0.0
发行说明 - Kafka - 版本1.0.0 以下是Kafka 1.0.0发行版中解决的JIRA问题的摘要.有关该版本的完整文档,入门指南以及有关该项目的信息,请参阅Kafka项目网站. 有关升级的注 ...
- _00017 Kafka的体系结构介绍以及Kafka入门案例(0基础案例+Java API的使用)
博文作者:妳那伊抹微笑 itdog8 地址链接 : http://www.itdog8.com(个人链接) 博客地址:http://blog.csdn.net/u012185296 博文标题:_000 ...
- Windows下Kafka 2.3.0的下载和安装
Kafka是由Apache软件基金会开发的一个开源流处理平台,是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据. 特性:(1)通过O(1)的磁盘数据结构提供消息的持久化 ...
- Kafka 2.5.0发布——弃用对Scala2.11的支持
近日Kafka发布了最新版本 2.5.0,增加了很多新功能: 下载地址:https://kafka.apache.org/downloads#2.5.0 对TLS 1.3的支持(默认为1.2) 引入用 ...
- Kafka Eagle V2.0.0新版预览
1.概述 Kafka Eagle是一款用于管理Kafka的监控系统,且完全开源.当前Kafka Eagle发布了2.0.0版本.今天笔者就为大家来介绍一下2.0.0更新了哪些功能. 官网地址:http ...
- Kafka Eagle 3.0.1功能预览
1.概述 最近有同学留言,关于Kafka Eagle的一些使用问题.今天笔者就为大家来详细介绍Kafka Eagle 3.0.1的功能以及使用方法. 2.内容 在3.0.1版本中,EFAK优化了分布式 ...
- Spark Streaming + Kafka整合(Kafka broker版本0.8.2.1+)
这篇博客是基于Spark Streaming整合Kafka-0.8.2.1官方文档. 本文主要讲解了Spark Streaming如何从Kafka接收数据.Spark Streaming从Kafka接 ...
- Structured Streaming + Kafka Integration Guide 结构化流+Kafka集成指南 (Kafka broker version 0.10.0 or higher)
用于Kafka 0.10的结构化流集成从Kafka读取数据并将数据写入到Kafka. 1. Linking 对于使用SBT/Maven项目定义的Scala/Java应用程序,用以下工件artifact ...
- scala spark(2.10)读取kafka(2.11_1.0.0)示例
1.pom加载jar包 <dependency> <groupId>org.apache.spark</groupId> <artifactId>spa ...
随机推荐
- Java 多线程 同步和异步
同步和异步通常用来描述一次方法调用.一旦开始调用同步方法,调用者必须等到方法调用返回后,才能执行后续操作.一旦开始调用异步方法,方法调用会立即返回,调用者可以执行后续操作.异步方法会在另外一个线程中真 ...
- Egret 项目文件夹配置和基本容器、动画
Egret 项目文件夹配置和基本容器.动画: class Main extends egret.DisplayObjectContainer { //src是resource codede 缩写,所有 ...
- java内存和linux关系
运行个JAVA 用sleep去hold住 package org.hjb.test; public class TestOnly { public static void main(String[] ...
- python之进程和线程
1 操作系统 为什么要有操作系统 ? 操作系统位于底层硬件与应用软件之间的一层 工作方式:向下管理硬件,向上提供接口 操作系统进程切换: 出现IO操作 固定时间 2 进程和线程的概念 进程就是一个程序 ...
- 微信小程序中的单位
vw:viewpoint width,视窗宽度,1vw等于视窗宽度的1%. vh:viewpoint height,视窗高度,1vh等于视窗高度的1%. rpx:rpx单位是微信小程序中css的尺寸单 ...
- flask之信号和mateclass元类
本篇导航: flask实例化参数 信号 metaclass元类解析 一.flask实例化参数 instance_path和instance_relative_config是配合来用的:这两个参数是用来 ...
- Exchange - Add Owner of Distribution Group
User Interface: Open Exchange Management Console. Expand Microsoft Exchange On-Premises, then right ...
- Python 读取 支付宝账单并存储到 Access 中
我有一个很多年前自己写的C#+Access的记账程序,用了很多年,现在花钱的机会多了,并且大部分走的支付宝,于是就想把账单从支付宝网站上下载下来,直接写入到Access,这样就很省心了. 记账程序是长 ...
- 一步步教你轻松学K-means聚类算法
一步步教你轻松学K-means聚类算法(白宁超 2018年9月13日09:10:33) 导读:k-均值算法(英文:k-means clustering),属于比较常用的算法之一,文本首先介绍聚类的理 ...
- xcode10 改动
xcode10 开发环境 比 之前有了稍微的变动 1. 代码块 界面控件 图片资源等 的查看位置发生了变化 之前的开发环境 代码块 统一放在 右侧栏的下方的几个选项中 现在 统一放到了上方 ...