hadoop伪分布环境快速搭建
1.首先下载一个完成已经进行简单配置好的镜像文件(hadoop,HBASE,eclipse,jdk环境已经搭建好,tomcat为7.0版本,建议更改为tomcat8.5版本,运行比较稳定)。
2安装VMware虚拟机
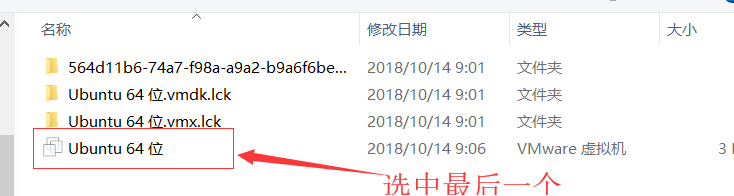
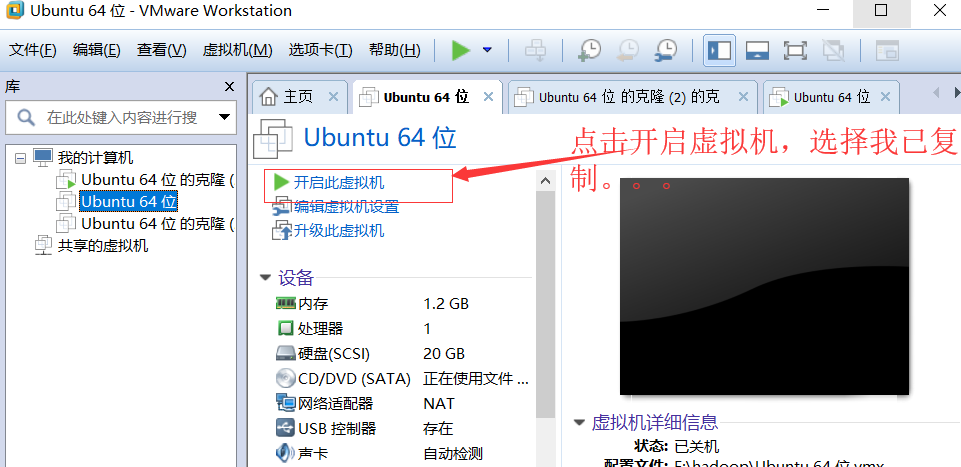
3.打开下载好的镜像文件

4.修改root的密码
1.在当前终端输入sudo passwd(回车)
2.Password: <--- 输入你当前用户的密码
输入你现在用户的密码后系统会出现:
Enter new UNIX password: <--- 新的Root用户密码
Retype new UNIX password: <--- 重复新的Root用户密码
passwd:已成功更新密码
现在,你可以使用命令 su ,接着输入root密码,你就可以变成root权限咯。当你想从root变成普通用户时,只需要输入命令 su 普通用户名 ,然后就会切换用户,并且此时不需要输入普通用户的密码,因为root权限比较高呗
5.修改主机名
vi /etc/hostnames
在此文件中修改主机名,与ip地址
6.将

未完持续更新中
hadoop伪分布环境快速搭建的更多相关文章
- Hadoop伪分布式环境快速搭建
Hadoop分支 Apache Cloudera Hortonworks 本文是采用Cloudera分支的hadoop. 下载cdh-5.3.6 版本 下载地址:http://archive.clou ...
- centos 6.4-linux环境配置,安装hadoop-1.1.2(hadoop伪分布环境配置)
1 Hadoop环境搭建 hadoop 的6个核心配置文件的作用: core-site.xml:核心配置文件,主要定义了我们文件访问的格式hdfs://. hadoop-env.sh:主要配置我们的j ...
- hadoop伪分布集群搭建
系统环境:ubuntu server16.04 1.root@master:~$ vim /etc/hostname #修改主机名 master 2.root@master:~$ reboot #重启 ...
- Hadoop之伪分布环境搭建
搭建伪分布环境 上传hadoop2.7.0编译后的包并解压到/zzy目录下 mkdir /zzy 解压 tar -zxvf hadoop.2.7.0.tar.gz -C /zzy 配置hado ...
- 【Hadoop离线基础总结】CDH版本Hadoop 伪分布式环境搭建
CDH版本Hadoop 伪分布式环境搭建 服务规划 步骤 第一步:上传压缩包并解压 cd /export/softwares/ tar -zxvf hadoop-2.6.0-cdh5.14.0.tar ...
- CentOS7下Hadoop伪分布式环境搭建
CentOS7下Hadoop伪分布式环境搭建 前期准备 1.配置hostname(可选,了解) 在CentOS中,有三种定义的主机名:静态的(static),瞬态的(transient),和灵活的(p ...
- 基于Centos搭建 Hadoop 伪分布式环境
软硬件环境: CentOS 7.2 64 位, OpenJDK- 1.8,Hadoop- 2.7 关于本教程的说明 云实验室云主机自动使用 root 账户登录系统,因此本教程中所有的操作都是以 roo ...
- hadoop集群环境的搭建
hadoop集群环境的搭建 今天终于把hadoop集群环境给搭建起来了,能够运行单词统计的示例程序了. 集群信息如下: 主机名 Hadoop角色 Hadoop jps命令结果 Hadoop用户 Had ...
- VMware 克隆linux后找不到eth0(学习hadoop,所以想快速搭建一个集群)
发生情况: 由于在学习hadoop,所以想快速搭建一个集群出来.所以直接在windows操作系统上用VMware安装了CentOS操作系统,配置好hadoop开发环境后,采用克隆功能,直接克 ...
随机推荐
- UESTC 1034 AC Milan VS Juventus 分情况讨论
AC Milan VS Juventus Time Limit: 3000/1000MS (Java/Others) Memory Limit: 65535/65535KB (Java/Oth ...
- go微服务框架go-micro深度学习(一) 整体架构介绍
产品嘴里的一个小项目,从立项到开发上线,随着时间和需求的不断激增,会越来越复杂,变成一个大项目,如果前期项目架构没设计的不好,代码会越来越臃肿,难以维护,后期的每次产品迭代上线都会牵一发而动全身.项目 ...
- 解决Linux文件系统变成只读的方法
解决Linux文件系统变成只读的方法 解决方法 1.重启看是否可以修复(很多机器可以) 2.使用用 fsck – y /dev/hdc6 (/dev/hdc6指你需要修复的分区) 来修复文件系统 ...
- Android 看源码学 Binder
参考:https://jekton.github.io/2018/04/07/binder-why-RemoteListenerCallback-works/ 参考:https://jekton.gi ...
- django项目添加utf-8编码支持中文
代码中出现中文会报错: Non-ASCII character '...' in file ......models.py on line ......., but no encoding decla ...
- android sdk content loader 0%不动
Make sure that eclipse is not active. If it is active kill eclipse from the processes tab of the tas ...
- openfire课程
https://blog.csdn.net/huwenfeng_2011/article/category/2874473/2 https://www.cnblogs.com/Fordestiny/p ...
- fiddler抓包url有乱码
fiddler抓包url有乱码: 解决具体步骤: 注册表:regedit HKEY_CURRENT_USER\Software\Microsoft\Fiddler2 1.打开注册表,regedit ...
- C#时间格式化显示AM/PM
.ToString("MM/dd/yyyy hh:mm:ss:ffff tt")); //12小时制 .ToString("MM/dd/yyyy HH:mm:ss:fff ...
- 【规范】前端编码规范——jquery 规范
使用单引号 不推荐 $("div").html("<img src='1.jpg'>"); 推荐 $('div').html('<img sr ...