KADEMLIA算法
一、概述
基于异或距离算法的分布式散列表(DHT), 实现了去中心化的信息存储于查询系统;
Kademlia将网络设计为具有160层的二叉树,树最末端的每个叶子看作为节点,节点在树中的位置由同样是160bit的节点ID决定。每个bit的两种可能值(0或1),决定了节点在书中属于左边还是右边的子树,160下来,每个节点ID便都有一个确定的位置;
二、节点之间距离
Kad网络中每个节点都有一个160bit的ID值作为标志符,Key也是一个160bit的标志符,每一个加入Kad网络的节点都会被分配一个160bit的节点ID(node ID),这个ID值是随机产生的。同时<key, value>对的数据就存放在ID值距离key值最近的若干个节点上。
Kademlia使用异或距离算法来计算节点间的距离:
x ^ x = 0 //自己于自己的距离为0
x ^ y > 0 // 不同节点间必有距离
x ^ y = y ^ x // x到y的距离等于y到x的距离
x ^ y + y ^ z >= x ^ z //从a经b绕到c, 要比直接从a到c距离长
x + y >= x ^ y //暂不理解
(x ^ y) ^ (y ^ z) = x ^ z //暂不理解
所说的距离是逻辑上的距离,与地理位置无关,所以有可能两个节点之间计算得到的逻辑距离很近,但实际上地理上的距离却很远 。
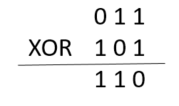
例如:节点A的ID(011)和节点B的ID(101)距离:011 ⊕ 101 = 110 = 4+2 = 6。
三、路由表
1、映射规则
- 先把key(如节点ID)以二进制形式表示,然后从高位到地位依次按Step2~Step3处理。
- 二进制的第n位对应二叉树的第n层
- 如果当前位是1,进入右子树,如果是0则进入左子树(认为设定,可以反过来)
- 按照高位到地位处理完后,这个Key值就对应于二叉树上的某个叶子节点。
当我们把所有节点ID都按照上述步骤操作后,会发现,这些节点形成一颗二叉树。
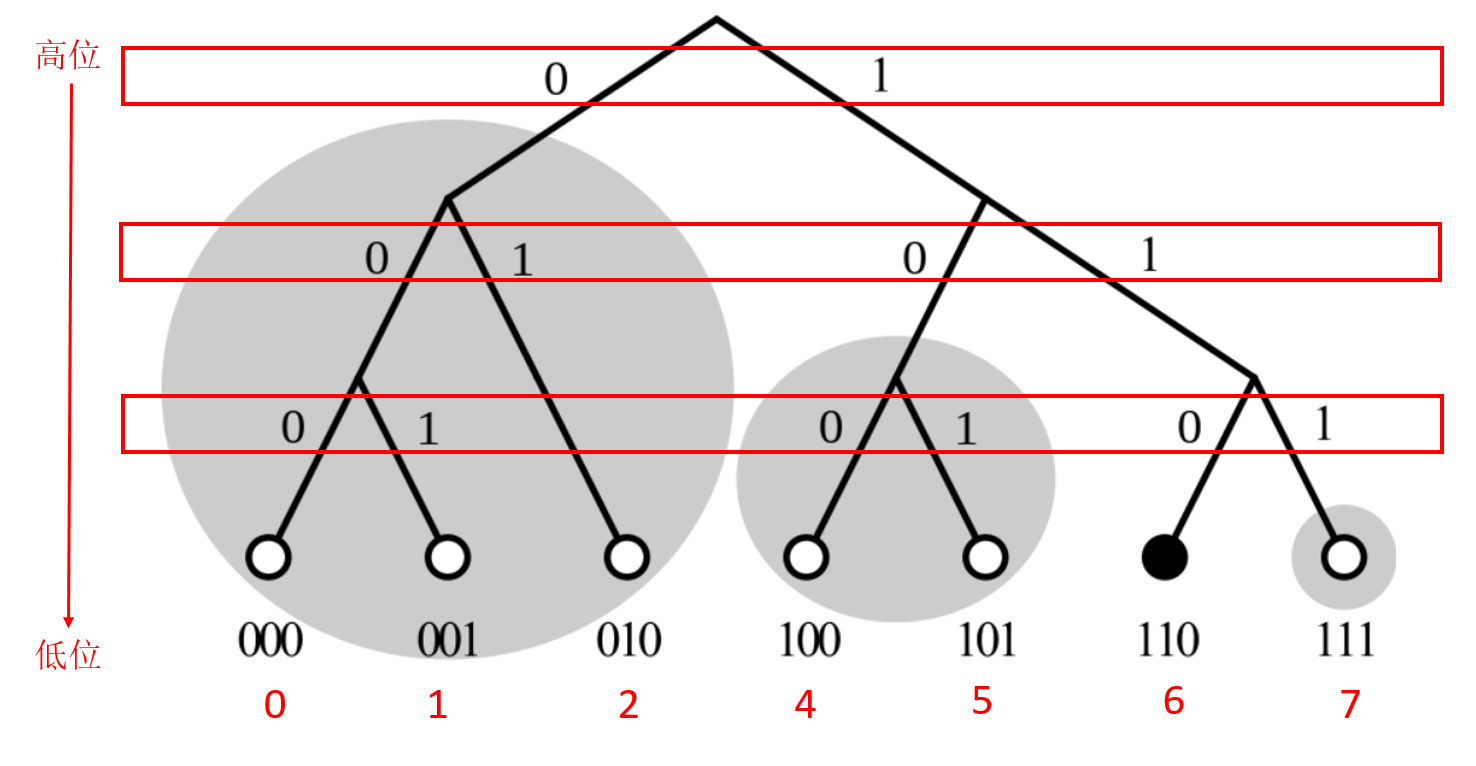
(实例仅演示三层)
2、二叉树拆分规则
每一个节点都可以从自己的视角出发来对二叉树进行拆分。
拆分规则是从根节点开始,把不包含自己的子树拆分出来,然后在剩下的子树再拆分不包含自己的下一层子树,以此类推,直到最后只剩下自己。如上图所示,以节点ID为6(110)为视角进行拆分,可以得到3个子树(灰色圆圈)。而以节点101为视角拆分,则可以得到如下二叉树。
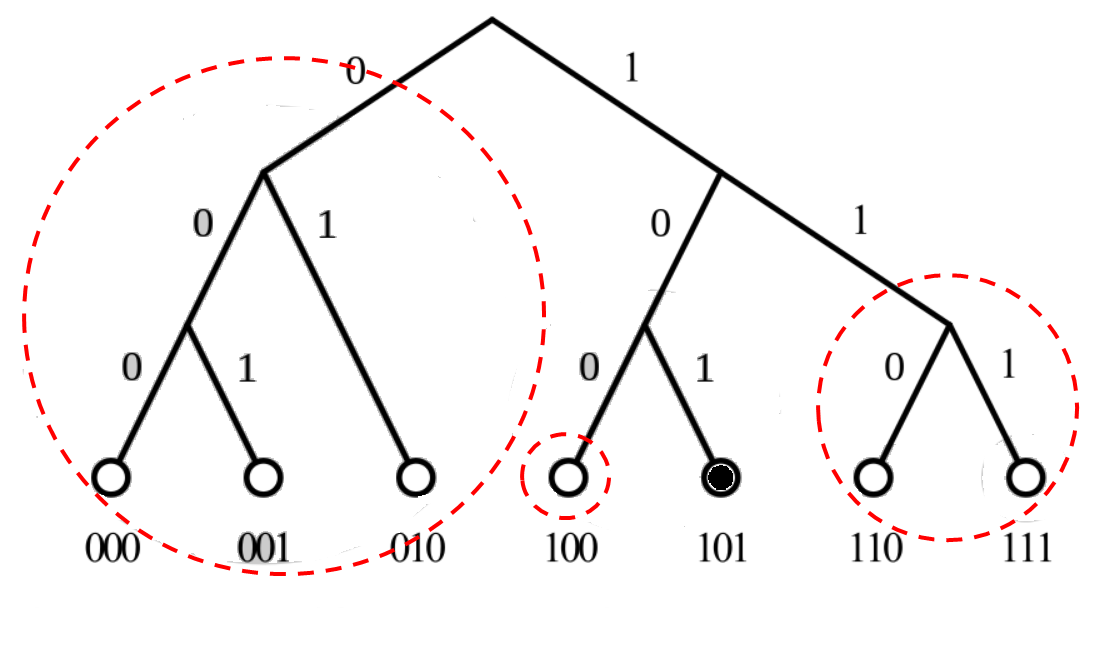
节点101的角度
Kad默认的散列值空间是m=160(散列值有160bit),所以拆分以后的子树最多有160个。而考虑到实际网络中节点个数远远没有2^160个,所以子树的个数明显小于160个。
对于每个节点,当按照自己的视角对二叉树进行拆分以后,会得到n个子树。对于每个子树,如果都分别知道里面1个节点,那么就可以利用这n个节点进行递归路由,从而可以达到整个二叉树的任何一个节点。
3、K-bucket 机制
假设每个节点ID是N bits。每个节点按照自己视角拆分完子树后,一共可以得到N个子树。
warning:上面说了,只要知道每个子树里的一个节点就可以实现所有节点的遍历。但是,在实际使用过程中,考虑到健壮性(每个节点可能推出或者宕机),只知道一个节点是不够的,需要之多多几个节点才比较保险。
所以,在Kad论文中旧有一个K-桶(K-bucket)的概念。也就是说,每个节点在完成拆分子树以后,要记录每个子树里面K个节点。这里K是一个系统级常量,由软件系统自己设定(BT下载使用的Kad算法中,K设定为8)。
K桶在这里实际上就是路由表。每个节点按照自己视角拆分完子树后,可以得到N个子树,那么就需要维护N个路由表(对应N个K-桶)。
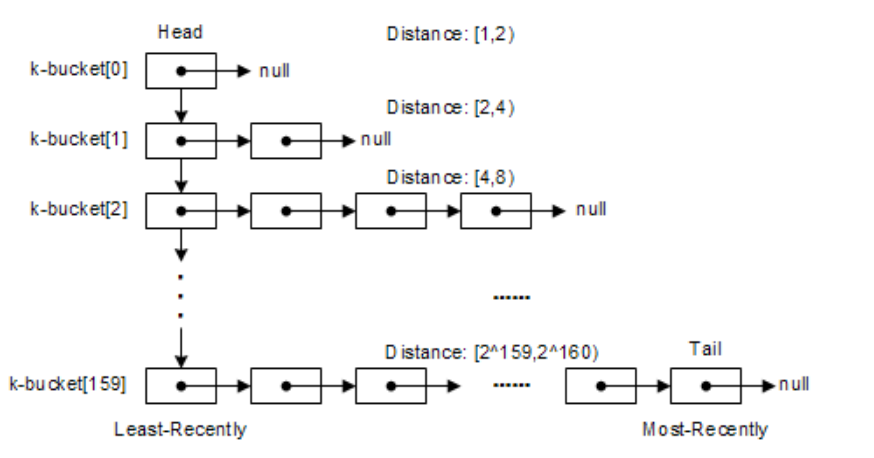
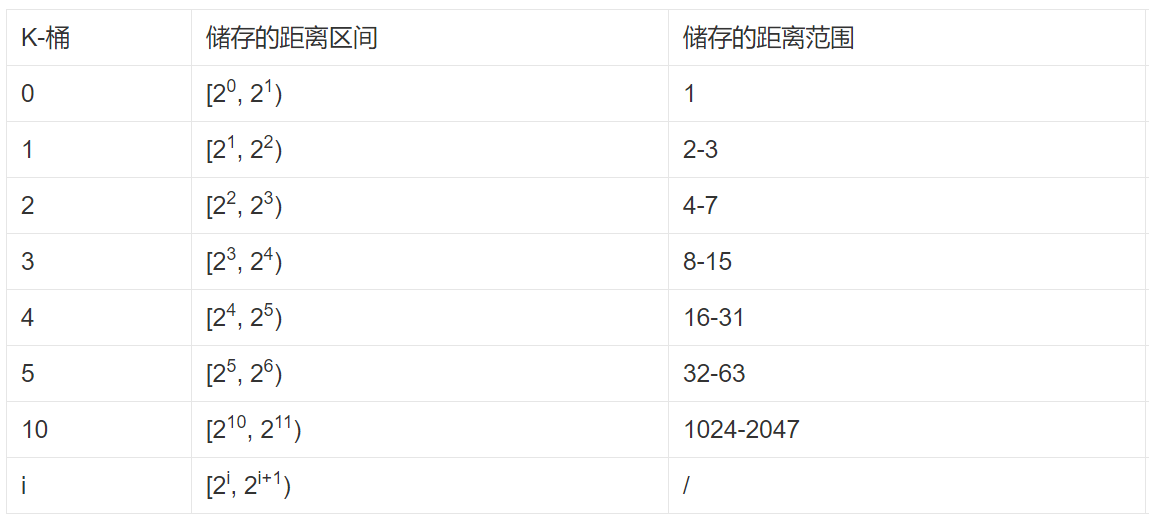
Kad算法中就使用了K-桶的概念来存储其他邻近节点的状态信息(节点ID、IP和端口),如下图,对于160bit的节点ID,就有160个K-桶。
对于每一个K-桶i,它会存储与自己距离在区间[2^i, 2^(i+1)) 范围内的K个节点的信息,如下图所示。每个K-桶i中存储有K个其他节点信息,在BitTorrent中K取8。当然每一个K-桶i不可能把所有相关的节点都存储,这样表根本存储不下。它是距离自己越近的节点存储的越多,离自己越远存储的越少(只取距离自己最近的K个节点),如下图所示。
同时每个K-桶中存放的位置是根据上次看到的时间顺序排列,最早访问的放在头部,最新访问的放在尾部。
4、K-桶更新机制【主要有3种】
- 主动收集节点
任何节点都可以发起FIND_NODE(查询节点)的请求,从而刷新K-桶中的节点信息
- 被动收集节点
当收到其他节点发送过来的请求(如:FIND_NODE、FIND_VALUE),会把对方的节点ID加入到某个K-桶中
- 检测失效节点
通过发起PING请求,判断K-桶中某个节点是否在线,然后清理K-桶中哪些下线的节点
当一个节点ID要被用来更新对应的K-桶,其具体步骤如下:
- 计算自己和目标节点ID的距离d
- 通过距离d选择路由表中对应的K-桶,如果目标节点ID已经在K-桶中,则把对应项移到该K-桶的尾部
- 如果目标节点ID不在K-桶中,则有两种情况:
- 如果该K-桶存储的节点小于K个,则直接把目标节点插入到K-桶尾部;
- 如果该K-桶存储节点大于等于K个,则选择K-桶中的头部节点进行PING操作,检测节点是否存活。如果头部节点没有响应,则移除该头部节点,并将目标节点插入到队列尾部;如果头部节点有响应,则把头部节点移到队列尾部,同时忽略目标节点。
我们可以看到K-桶的更新机制实现了一种把最近看到的节点更新的策略,也就是说在线时间长的节点有较高的可能性能够继续保留在K-桶列表中。
这种机制提高了Kad网络的稳定性并降少了网络维护成本(减少构建路由表),同时这种机制能在一定程度上防御DDOS攻击,因为只有老节点失效后,Kad才会更新K-桶,这就避免了通过新节点加入来泛洪路由信息。
5、协议消息
Kad算法一共有4中消息类型:
- PING 检查节点是否在线
- STORE 通知一个节点存储<key, value>键值对,以便以后查询使用
- FIND_NODE 返回对方节点桶中离请求键值最近的 K 个节点
- FIND_VALUE 与 FIND_NODE 一样,不过当请求的接收者存有请求者所请求的key值的时候,它将返回相应value
备注:每个发起请求的RPC消息都会包含一个发送者加入的随机值,这个可以确保在接收到消息响应的时候可以根前面发送过的消息匹配。
6、定位节点
节点查询可以同步进行也可以异步进行,同时查询的并发数量一般为3。
- 首先由发起者确定目标ID对应路由表中的K-桶位置,然后从自己的K-桶中筛选出K个距离目标ID最近的节点,并同时向这些节点发起FIND_NODE的查询请求。
- 被查询节点收到FIND_NODE请求后,从对应的K-桶中找出自己所知道的最近的K个节点,并返回给发起者。
- 发起者在收到这些节点后,更新自己的结果列表,并再次从其中K个距离目标节点ID最近的节点,挑选未发送请求的节点重复Step1步骤。
- 上述步骤不断重复,直到无法获取比发起者当前已知的K个节点更接近目标节点ID的活动节点为止。
- 在查询过程中,没有及时响应的节点应该立即排除,同时查询者必须保证最终获得的K个节点都是在线的。
7、定位资源
当节点要查询<key, value>数据对时,和定位节点的过程类似。
- 首先发起者会查找自己是否存储了<key, value>数据对,如果存在则直接返回,否则就返回K个距离key值最近的节点,并向这K个节点ID发起FIND_VALUE请求
- 收到FIND_VALUE请求的节点,首先也是检查自己是否存储了<key, value>数据对,如果有直接返回value,如果没有,则在自己的对应的K-桶中返回K-个距离key值最近的节点
- 发起者如果收到value则结束查询过程,否则发起者在收到这些节点后,更新自己的结果列表,并再次从其中K个距离key值最近的节点,挑选未发送请求的节点再次发起FIND_VALUE请求。
- 上述步骤不断重复,直到获取到value或者无法获取比发起者当前已知的K个节点更接近key值的活动节点为止,这时就表示未找到value值。
如果上述FIND_VALUE最终找到value值,则<key, value>数据对会缓存在没有返回value值的最近节点上,这样下次再查询相同的key值时就可以加快查询速度。
所以,越热门的资源,其缓存的<key, value>数据对范围就越广。这也是为什么我们以前用P2P下载工具,下载的某个资源的人越多时,下载速度越快的原因。
8、保存资源
当节点收到一个<key, value>的数据时,它的存储过程如下:
- 发起者首先定位K个距离目标key值最近的节点
- 然后发起者对这K个节点发起STORE请求
- 接收到STORE请求的节点将保存<key, value>数据
- 同时,执行STORE操作的K个节点每小时重发布自己所有的<key, value>对数据
- 最后,为了限制失效信息,所有<key, value>对数据在发布24小时后过期。
9、新节点加入网络
新节点想要加入Kad网络,其步骤如下:
- 新节点A首先需要一个种子节点B作为引导,并把该种子节点加入到对应的K-桶中
- 首先生成一个随机的节点ID值,直到离开网络,该节点会一直使用该ID
- 向节点B发起FIND_NODE请求,请求定位的节点时自己的节点ID
- 节点B在收到节点A的FIND_NODE请求后,会根据FIND_NODE请求的约定,找到K个距离A最近的节点,并返回给A节点
- A收到这些节点以后,就把它们加入到自己的K-桶中
- 然后节点A会继续向这些刚拿到节点发起FIND_NODE请求,如此往复,直到A建立了足够详细的路由表。
节点A在自我定位建立路由表的同时,也使得其他节点能够使用节点A的ID来更新他们的路由表。这过程让节点A获得详细路由表的同时,也让其他节点知道A节点的加入。
转自《https://shuwoom.com/?p=813》
KADEMLIA算法的更多相关文章
- 死磕以太坊源码分析之Kademlia算法
死磕以太坊源码分析之Kademlia算法 KAD 算法概述 Kademlia是一种点对点分布式哈希表(DHT),它在容易出错的环境中也具有可证明的一致性和性能.使用一种基于异或指标的拓扑结构来路由查询 ...
- KADEMLIA算法学习
在上一篇文章中<P2P技术是什么>,我们介绍了P2P技术的特点以及发展历史.在本篇文章中,我们来介绍某一个具体的算法. 如今很多P2P网络的实现都采用DHT的方式实现查找,其中Kademl ...
- 以太坊Bootstrap和Kademlia算法实现逻辑简介(基于cpp-ethereum)
- Kademlia、DHT、KRPC、BitTorrent 协议、DHT Sniffer
catalogue . 引言 . Kademlia协议 . KRPC 协议 KRPC Protocol . DHT 公网嗅探器实现(DHT 爬虫) . BitTorrent协议 . uTP协议 . P ...
- 开源磁力搜索爬虫dhtspider原理解析
开源地址:https://github.com/callmelanmao/dhtspider. 开源的dht爬虫已经有很多了,有php版本的,python版本的和nodejs版本.经过一些测试,发现还 ...
- [C#搜片神器] 之P2P中DHT网络爬虫原理
继续接着上一篇写:使用C#实现DHT磁力搜索的BT种子后端管理程序+数据库设计(开源)[搜片神器] 昨天由于开源的时候没有注意运行环境,直接没有考虑下载BT种子文件时生成子文件夹,可能导致有的朋友运行 ...
- [转载]用.NET开发的磁力搜索引擎——Btbook.net
去年10月份开始研究相关的协议与资料,中途乱七八糟的事情差点没坚持下来,寒假里修修补补上礼拜把Btbook发布了,经过社交网络的推广之后,上线第三天UV就达到了两万多,也算是对这几个月工作的一点肯定吧 ...
- 网络协议 15 - P2P 协议:小种子大学问
[前五篇]系列文章传送门: 网络协议 10 - Socket 编程(上):实践是检验真理的唯一标准 网络协议 11 - Socket 编程(下):眼见为实耳听为虚 网络协议 12 - HTTP 协议: ...
- 用.NET开发的磁力搜索引擎——btbook.net
UPDATE:目前项目已停止维护,本文仅留作纪念. 去年10月份开始研究相关的协议与资料,中途乱七八糟的事情差点没坚持下来,寒假里修修补补上礼拜把Btbook发布了,经过社交网络的推广之后,上线第三天 ...
随机推荐
- python基础篇_001_初识Python
一.Python环境 windows环境安装Python步骤 .下载安装包:https://www.python.org/downloads/windows/ .安装:默认安装路径:C:\pytho ...
- POJ 1733 Parity game 【带权并查集】+【离散化】
<题目链接> 题目大意: 一个由0,1组成的序列,每次给出一段区间的奇偶,问哪一条信息不合法. 解题分析: 我们用s[i]表示前i个数的前缀和,那么a b even意味着s[b]和s[a- ...
- Java设计模式从精通到入门五 抽象工厂方法模式
定义 抽象工厂类为创建一组相关和相互依赖的对象提供一组接口,而无需指定一个具体的类. 这里我得把工厂方法模式得定义拿出来做一下比较:定义一个创建对象的接口,由子类决定实例化哪一个类.工厂方法是一个 ...
- Kafka、RabbitMQ、RocketMQ等消息中间件的对比 —— 消息发送性能和区别
https://blog.csdn.net/yunfeng482/article/details/72856762
- BZOJ1500: [NOI2005]维修数列 [splay序列操作]【学习笔记】
以前写过这道题了,但我把以前的内容删掉了,因为现在感觉没法看 重写! 题意: 维护一个数列,支持插入一段数,删除一段数,修改一段数,翻转一段数,查询区间和,区间最大子序列 splay序列操作裸题 需要 ...
- js点击回到顶部2
<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title>点 ...
- Java转型
集合转型 通过中间类型List List<String> strs=new ArrayList<>(); List list=(List)strs; List<Objec ...
- LINUX配置Django
django项目: 依赖包[root@web01 ~]# yum install openssl-devel bzip2-devel expat-devel gdbm-devel readline-d ...
- Node爬取简书首页文章
Node爬取简书首页文章 博主刚学node,打算写个爬虫练练手,这次的爬虫目标是简书的首页文章 流程分析 使用superagent发送http请求到服务端,获取HTML文本 用cheerio解析获得的 ...
- docker 清理容器的命令
执行以下命令会彻底清除所有容器. docker rm -f $(docker ps -qa) rm -rf /var/lib/etcd /var/lib/cni /var/run/calico rm ...