python 爬虫启航
1. 使用excel(简单使用)
数据- 自网站-导入
2.you-get
python爬虫入门
1.环境配置
python,request,lxml
2.原理
爬虫的框架如下:
1.挑选种子URL;
2.将这些URL放入待抓取的URL队列;
3.取出待抓取的URL,下载并存储进已下载网页库中。此外,将这些URL放入待抓取URL队列,进入下一循环;
4.分析已抓取队列中的URL,并且将URL放入待抓取URL队列,从而进入下一循环。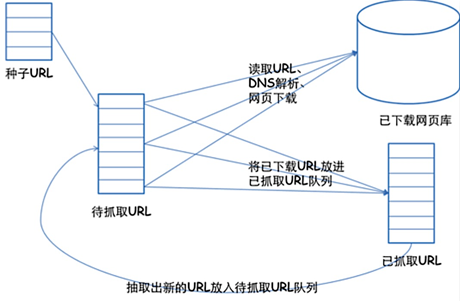
爬虫的基本流程:
简单的说,我们向服务器发送请求后,会得到返回的页面,通过解析页面之后,我们可以抽取我们想要的那部分信息,并存储在指定的文档或数据库中。这样,我们想要的信息就被我们“爬”下来啦~
Requests+Xpath爬去豆瓣电影
import requests
from lxml import etree
from bs4 import BeautifulSoup
def movie_spider(url):
data = requests.get(url).text
s = etree.HTML(data) # 根据页面的xpath解析数据
film = s.xpath('/html/body/div[3]/div[1]/h1/span[1]/text()')
director = s.xpath('/html/body/div[3]/div[1]/div[3]/div[1]/div[1]/div[1]/div[1]/div[2]/span[1]/span[2]/a/text()') # 浏览器检查的Xpath和实际不对应?为什么?
actor1= s.xpath('//*[@id="info"]/span[3]/span[2]/a[1]/text()')
time = s.xpath('/html/body/div[3]/div[1]/div[3]/div[1]/div[1]/div[1]/div[1]/div[2]/span[13]/text()')
print(film,director,actor1,time) 静态网页抓取
def top250_movie_spider():
"""
1.定制请求头,network>user-agent
:return:
"""
movie_list = []
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0',
'Host':'movie.douban.com'
}
for i in range(0,10):
link = 'https://movie.douban.com/top250?start='+str(i*25)+'&filter='
r = requests.get(link,headers=headers,timeout=10)
# 使用BeautifulSoup解析网页
soup = BeautifulSoup(r.text,'lxml')
div_list = soup.find_all('div',class_='hd')
for each in div_list:
movie = each.a.span.text.strip()
movie_list.append(movie)
return movie_list
if __name__ == "__main__":
url = "https://movie.douban.com/subject/1292052/"
# movie_spider(url)
print(top250_movie_spider())
动态网页抓取
解析真实地址抓取:
network(刷新网页抓包)>XHR>确定真实地址
json库解析数据
import requests
import json
link ="https://api-zero.livere.com/v1/comments/list?callback=jQuery1124047657659644175476_1543235317407&limit=10&repSeq=4272904&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&_=1543235317409"
def single_page_comment(link):
# 定制请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.89 Safari/537.36'}
r = requests.get(link, headers=headers) json_string = r.text
json_string = json_string[json_string.find('{'):-2] json_data = json.loads(json_string) common_list = json_data['results']['parents']
for eachone in common_list:
message = eachone['content']
print(message) # 对比不同的地址,找出改变的量
for page in range(1,4):
link1 = "https://api-zero.livere.com/v1/comments/list?callback=jQuery112403473268296510956_1531502963311&limit=10&offset="
link2 = "&repSeq=4272904&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&_=1531502963316"
page_str = str(page)
link = link1 + page_str + link2
print (link)
single_page_comment(link)
使用Selenium模拟浏览器抓取
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
import time
# # 需要geckodriver,并放入环境变量中 --错误
# driver = webdriver.Firefox()
# driver.get("https://www.baidu.com") #动态爬取网页
caps = webdriver.DesiredCapabilities().FIREFOX
caps["marionette"] = True
# 计算机中firefox的地址
binary = FirefoxBinary(r"C:\Program Files (x86)\Mozilla Firefox\firefox.exe")
driver = webdriver.Firefox(firefox_binary=binary,capabilities=caps)
for i in range(0,20):
driver.get("https://zh.airbnb.com/s/Shenzhen--China/homes?refinement_paths%5B%5D=%2Fhomes&click_referer=t%3ASEE_ALL%7Csid%3Ad66de168-dbd5-42e7-a122-bd4a001f781e%7Cst%3AMAGAZINE_HOMES&title_type=MAGAZINE_HOMES&query=Shenzhen%2C%20China&allow_override%5B%5D=&s_tag=ckaduMCI§ion_offset=4&items_offset="+str(i*18))
rent_list = driver.find_elements_by_css_selector('div._gig1e7')
for eachhouse in rent_list:
comment = eachhouse.find_element_by_css_selector('span._1cy09umr')
comment = comment.text price_detail = eachhouse.find_elements_by_css_selector("span._1sfeueqe")
price_list = [i.text for i in price_detail]
price = price_list[1] name = eachhouse.find_element_by_css_selector("div._190019zr")
name = name.text details = eachhouse.find_element_by_css_selector("div._1etkxf1")
details = details.text print(comment,price,name,details)
python 爬虫启航的更多相关文章
- python 爬虫启航2.0
文章解析: 1.正则表达式解析 2.beautifulsoup,BeautifulSoup是一个复杂的树形结构,她的每一个节点都是一个python对象,获取网页的内容就是一个提取对象内容的过程,它的提 ...
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
- python爬虫学习(7) —— 爬取你的AC代码
上一篇文章中,我们介绍了python爬虫利器--requests,并且拿HDU做了小测试. 这篇文章,我们来爬取一下自己AC的代码. 1 确定ac代码对应的页面 如下图所示,我们一般情况可以通过该顺序 ...
- python爬虫学习(6) —— 神器 Requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 H ...
- 批量下载小说网站上的小说(python爬虫)
随便说点什么 因为在学python,所有自然而然的就掉进了爬虫这个坑里,好吧,主要是因为我觉得爬虫比较酷,才入坑的. 想想看,你可以批量自动的采集互联网上海量的资料数据,是多么令人激动啊! 所以我就被 ...
- python 爬虫(二)
python 爬虫 Advanced HTML Parsing 1. 通过属性查找标签:基本上在每一个网站上都有stylesheets,针对于不同的标签会有不同的css类于之向对应在我们看到的标签可能 ...
- Python 爬虫1——爬虫简述
Python除了可以用来开发Python Web之后,其实还可以用来编写一些爬虫小工具,可能还有人不知道什么是爬虫的. 一.爬虫的定义: 爬虫——网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区 ...
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
随机推荐
- Verilog中的$display和$write任务
$display(p1,p2, …,pn); $write(p1,p2, …,pn); 这两个函数和系统任务的作用都是用来输出信息,即将参数p2到pn按参数p1给定的格式输出.参数p1通常称为:“格式 ...
- binary and out mode to open a file
When I use binary and out mode to open a exist file, and to modify the 4th and 8th byte data to 0x78 ...
- activity select problem(greedy algorithms)
many activities will use the same place, every activity ai has its' start time si and finish time f ...
- Spell checker using hash table
Problem description Given a text file, show the spell errors from it. (https://www.andrew.cmu.edu/c ...
- Unity在UI界面上显示3D模型/物体,控制模型旋转
Unity3D物体在UI界面的显示 本文提供全流程,中文翻译. Chinar 坚持将简单的生活方式,带给世人!(拥有更好的阅读体验 -- 高分辨率用户请根据需求调整网页缩放比例) Chinar -- ...
- [JLOI2011]不重复数字
原题链接 题解 题目大意:给出N个数,要求把其中重复的去掉,只保留第一次出现的数.最后按顺序输出N <= 50000 然这题是个哈希的典型题目 HASH,我对于它的理解就是一个桶%一个数,当然并 ...
- hibernate模拟(转载)
package simulation; /** * * @author Administrator * */ public class User { private int id; private S ...
- 从npm 角度理解 mvn 的 pom.xml
从npm 角度理解 mvn 的 pom.xml pom -- project object model. 用于描述项目的配置: 基础说明 依赖 如何构建运行 类似 node.js 的 package. ...
- 对数据进行GZIP压缩或解压缩
/** * 对data进行GZIP解压缩 * @param data * @return * @throws Exception */ public static String unCompress( ...
- [转]使用python爬取东方财富网机构调研数据
最近有一个需求,需要爬取东方财富网的机构调研数据.数据所在的网页地址为: 机构调研 网页如下所示: 可见数据共有8464页,此处不能直接使用scrapy爬虫进行爬取,因为点击下一页时,浏览器只是发起了 ...