Ruby用百度搜索爬虫
Ruby用百度搜索爬虫
博主ruby学得断断续续,打算写一个有点用的小程序娱乐一下,打算用ruby通过百度通道爬取网络信息。
第三方库准备
- mechanize:比较方便地处理网络请求,类似于Python中的requests
- nokogiri:解析HTML文本,采用的是jquery选择器
步骤分析
- 用mechanize创建一个agent对象
- 我们首先登录百度主页
- 找到百度『搜索』框的表单
- 填写表单内容
- 提交表单(agent用该表单的内容发出submit动作)
- 分析百度获得的搜索结果列表
- 用nokogiri解析HTML文本,提取出我们感兴趣的内容
代码
require 'mechanize'
require 'nokogiri'
# 百度搜索的关键字,可修改
keyword = 'ruby'
# 创建一个agent对象
agent = Mechanize.new
# 发送get请求获取页面
page = agent.get 'http://www.baidu.com/'
# 根据名字属性定位表单
search_form = page.form_with :name => 'f'
# 填表,搜索框的name是wd
search_form.field_with(:name => "wd").value = keyword
# 提交表单
search_results = agent.submit search_form
doc = Nokogiri::HTML(search_results.body)
doc.css('.c-container > h3 > a').each{
|item|
puts item.text
}
测试结果
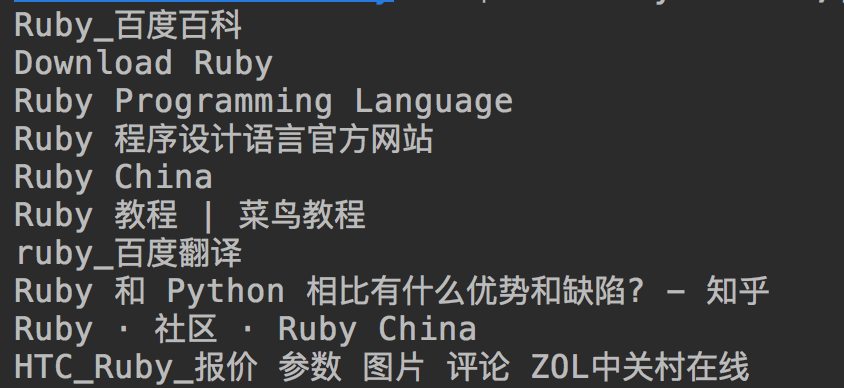
Ruby用百度搜索爬虫的更多相关文章
- 利用python爬取海量疾病名称百度搜索词条目数的爬虫实现
实验原因: 目前有一个医疗百科检索项目,该项目中对关键词进行检索后,返回的结果很多,可惜结果的排序很不好,影响用户体验.简单来说,搜索出来的所有符合疾病中,有可能是最不常见的疾病是排在第一个的,而最有 ...
- PHP网络爬虫实践:抓取百度搜索结果,并分析数据结构
百度的搜索引擎有反爬虫机制,我先直接用guzzle试试水.代码如下: <?php /** * Created by Benjiemin * Date: 2020/3/5 * Time: 14:5 ...
- 使用python抓取百度搜索、百度新闻搜索的关键词个数
由于实验的要求,需要统计一系列的字符串通过百度搜索得到的关键词个数,于是使用python写了一个相关的脚本. 在写这个脚本的过程中遇到了很多的问题,下面会一一道来. ps:我并没有系统地学习过pyth ...
- 简单的抓取淘宝关键字信息、图片的Python爬虫|Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇)
Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇) 淘宝改字段,Bugfix,查看https://github.com/hunterhug/taobaoscrapy.git 由于Gith ...
- python爬取百度搜索结果ur汇总
写了两篇之后,我觉得关于爬虫,重点还是分析过程 分析些什么呢: 1)首先明确自己要爬取的目标 比如这次我们需要爬取的是使用百度搜索之后所有出来的url结果 2)分析手动进行的获取目标的过程,以便以程序 ...
- 百度搜索:有关Baiduspider的10个问题
猫宁!!! 参考链接: http://help.baidu.com/question?prod_id=99&class=476&id=2996 https://ziyuan.baidu ...
- Python:输入关键字进行百度搜索并爬取搜索结果
学习自:手把手教你用Python爬取百度搜索结果并保存 - 云+社区 - 腾讯云 如何利用python模拟百度搜索,Python交流,技术交流区,鱼C论坛 指定关键字,对其进行百度搜索,保存搜索结果, ...
- jsonp模拟获取百度搜索相关词汇
随便写了个jsonp模拟百度搜索相关词汇的小demo,帮助新手理解jsonp的用法. <!DOCTYPE html><html lang="en">< ...
- Splinter学习--初探1,模拟百度搜索
Splinter是以Selenium, PhantomJS 和 zope.testbrowser为基础构建的web自动化测试工具,基本原理同selenium 支持的浏览器包括:Chrome, Fire ...
随机推荐
- 升级 Apache Tomcat的办法
1.下载最新的7系列tomcat cd /usr/local/software wget https://www-us.apache.org/dist/tomcat/tomcat-7/v7.0.92/ ...
- KnockOut -- 快速入门
简单示例 <!DOCTYPE html> <html lang="en"> <head> <meta charset="utf- ...
- SQL Server中Text和varchar(max) 区别
SQL Server 2005之后版本:请使用 varchar(max).nvarchar(max) 和 varbinary(max) 数据类型,而不要使用 text.ntext 和 image 数据 ...
- CND网站加速
CDN是什么 1-CDN俗称网站加速2-公司一般是购买其他cdn服务商提供的服务3-CDN一般是用来缓存网站的静态资源文件的(css,js,图片,html,htm),浏览器获取某个静态资源是按照就近原 ...
- H5利用pattern属性和oninvalid属性验证表单
HTML代码 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <ti ...
- luogu 1471
题意: 蒟蒻HansBug在一本数学书里面发现了一个神奇的数列,包含N个实数.他想算算这个数列的平均数和方差. 操作1:1 x y k ,表示将第x到第y项每项加上k,k为一实数. 操作2:2 x y ...
- weblogic弱密码检测
http://www.secbox.cn/hacker/tools/6252.html http://60.12.168.73:8088/console/login/LoginForm.jsp htt ...
- Python学习(二十五)—— Python连接MySql数据库
转载自http://www.cnblogs.com/liwenzhou/p/8032238.html 一.Python3连接MySQL PyMySQL 是在 Python3.x 版本中用于连接 MyS ...
- 解决背景图文字盖住html里面的dom元素
width:100%; background: url('../images/res.jpg') no-repeat 0 0px; background-attachment:fixed; backg ...
- HTML5上传图片预览功能
HTML5上传图片预览功能 HTML代码如下: <!-- date: 2018-04-27 14:41:35 author: 王召波 descride: HTML5上传图片预览功能 --> ...