浅析requests库响应对象的text和content属性
在做爬虫时请求网页的requests库是必不可少的,我们常常会用到 res = resquests.get(url) 方法,在获取网页的html代码时常常使用res的text属性: html = res.text,在下载图片或文件时常常使用res的content属性:
with open(filename, 'wb') as fp: fp.write(res.content)
下面我们来看看 'text' 和 'content' 的不同之处:
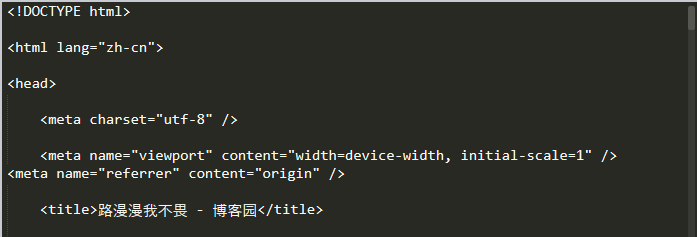
输出本博客的响应对象的 text
import requests url = 'https://www.cnblogs.com/huwt/' res = requests.get(url, timeout = 6) print(res.text)
(只截取到<title>标签)
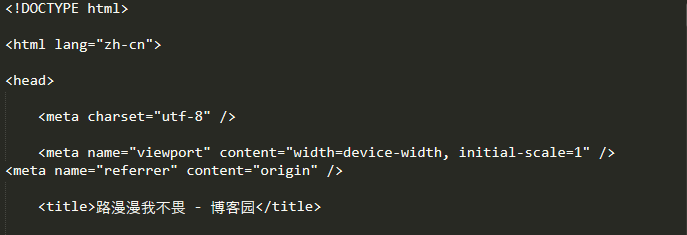
输出本博客的响应对象的 content
import requests url = 'https://www.cnblogs.com/huwt/' res = requests.get(url, timeout = 6) print(res.content)
(只截取到<title>标签)

通过<title>标签我们可以看出 res.text 直接输出了汉字,而 res.content 好像是以十六进制的形式来表示汉字
为了让进一步了解text 和 content 我们来看看它们的类型:
import requests url = 'https://www.cnblogs.com/huwt/' res = requests.get(url, timeout = 6) print(type(res.text)) print(type(res.content))

我们可以看到res.text是字符串类型,而res.content是二进制类型
为了进一步验证我们使用bytes类型的decode()方法对content进行‘utf-8’编码再显示
import requests
url = 'https://www.cnblogs.com/huwt/'
res = requests.get(url, timeout = 6)
print(res.content.decode('utf-8'))
发现和res.text显示的内容完全一样
因此我们可以得出结论:
resp.text返回的是Unicode型的数据。 resp.content返回的是bytes型也就是二进制的数据。、 获取文本一般使用res.text, 获取图片或文件一般使用res.conten
再做几点补充:
text是content经过编码之后的字符串,那编码方式是什么呢? 在返回text时requests会基于 HTTP 头部对响应的编码作出有根据的推测,但不一定准确,有可能出现乱码, 而我们可以手动指定一种编码方式:res.encoding = '需要的编码方式' 或让requests根据body进行猜测:res.encoding = res.apparent_encoding
参考学习:
https://zhidao.baidu.com/question/941417472703558372.html
https://www.cnblogs.com/loveyouyou616/p/8135678.html
https://www.cnblogs.com/chownjy/p/6625299.html
https://www.jianshu.com/p/0e0336b370f3
浅析requests库响应对象的text和content属性的更多相关文章
- requests库响应消息体的四种格式
1.r.text 文本响应内容,返回字符串类型,获取网页html时用: 2.r.content 字节响应内容,返回字节类型,下载图片或者文件时用: 3.r.json json解码响应内容,返回字典 ...
- Requests库的文档高级用法
高级用法 本篇文档涵盖了 Requests 的一些高级特性. 会话对象 会话对象让你能够跨请求保持某些参数.它也会在同一个 Session 实例发出的所有请求之间保持 cookie, 期间使用 url ...
- requests库学习案例
requests库使用流程 使用流程/编码流程 1.指定url 2.基于requests模块发起请求 3.获取响应对象中的数据值 4.持久化存储 分析案例 需求:爬取搜狗首页的页面数据 # 爬取搜狗首 ...
- Python爬虫 requests库基础
requests库简介 requests是使用Apache2 licensed 许可证的HTTP库. 用python编写. 比urllib2模块更简洁. Request支持HTTP连接保持和连接池,支 ...
- express-6 请求和响应对象(1)
URL的组成部分 协议: 协议确定如何传输请求.我们主要是处理http和https.其他常见的协议还有file和ftp. 主机名: 主机名标识服务器.运行在本地计算机(localhost)和本地网络的 ...
- Node+Express中请求和响应对象
在用 Express 构建 Web 服务器时,大部分工作都是从请求对象开始,到响应对象终止. url的组成: 协议协议确定如何传输请求.我们主要是处理 http 和 https.其他常见的协议还有 f ...
- 【转载】requests库的7个主要方法、13个关键字参数以及响应对象的5种属性
Python爬虫常用模块:requests库的7个主要方法.13个关键字参数以及响应对象的5种属性 原文链接: https://zhuanlan.zhihu.com/p/67489739
- 4.爬虫 requests库讲解 GET请求 POST请求 响应
requests库相比于urllib库更好用!!! 0.各种请求方式 import requests requests.post('http://httpbin.org/post') requests ...
- 使用Python的requests库进行接口测试——session对象的妙用
from:http://blog.csdn.net/liuchunming033/article/details/48131051 在进行接口测试的时候,我们会调用多个接口发出多个请求,在这些请求中有 ...
随机推荐
- 在Ubuntu登陆界面输入密码之后,黑屏一闪后,又跳转到登录界面
现象:在Ubuntu登陆界面输入密码之后,黑屏一闪后,又跳转到登录界面.原因:主目录下的.Xauthority文件拥有者变成了root,从而以用户登陆的时候无法都取.Xauthority文件.说明:X ...
- Linux Ubuntu部署web环境及项目tomcat+jdk+mysql
1,下载文件 在官网下载好 tomcat.jdk.mysql的linux压缩包 后缀名为.tar.gz 并通过xftp上传到服务器 或者直接通过linux命令 下在wget文件的下载地址 例如: wg ...
- iOS 不能加载电子签名
问题: 1:使用WKWebView在iOS12.0以上的系统中,可以显示PDF中的电子图章,签名.在iOS12.0以下的系统中不能显示电子签名,图章. 2: 解决方案,使用PDF.js加载. pdf ...
- WannaCry勒索病毒全解读,权威修复指南大集合
多地的出入境.派出所等公安网络疑似遭遇了勒索蠕虫病毒袭击,已暂时停办出入境业务:加油站突然断网,不能支持支付宝.微信.银联卡等联网支付:大批高校师生电脑中的文件被蠕虫病毒加密,需要支付相应的赎金方可解 ...
- Jedis 操作 Redis 工具类
配置类 pom.xml pom.xml 里配置依赖 <dependency> <groupId>redis.clients</groupId> <artifa ...
- 多核CPU配合负载均衡可以这样用,为老板省点钱
负载均衡作为一个处理高并发,大流量的访问的业务场景,已经几乎是常识性的知识了. 而本文的意义在于需求:由于大流量请求,导致服务无法正常响应,在不增加购买机器成本的场景下,如何提高服务器的业务处理能力? ...
- HttpClient实现HTTP文件通用下载类
import java.io.File; import java.io.FileOutputStream; import java.io.InputStream; import org.apache. ...
- PHP画矩形,椭圆,圆,画椭圆弧 ,饼状图
1:画矩形: imagerectangle ( resource $image , int $x1 , int $y1 , int $x2 , int $y2 , int $col ) imagere ...
- Mysql数据库操作命令行小结
-- 创建数据库 create database python_test_1 charset=utf8; -- 使用数据库 use python_test_1; -- students表 create ...
- 【Eclipse】添加builder实现NDK的自动编译
最近在做NDK相关的东西,Eclipse里面java的自动编译很方便,每次改动后就能自己编译显示错误,而NDK的C/C++文件就需要保存后再手动点build. 研究了下发现java code的自动编译 ...