Hadoop 3、Hadoop 分布式存储系统 HDFS(好多彩色图)
HDFS是Hadoop Distribute File System 的简称,也就是Hadoop的一个分布式文件系统。
一、HDFS的优缺点
1.HDFS优点:
a.高容错性
.数据保存多个副本
.数据丢的失后自动恢复
b.适合批处理
.移动计算而非移动数据
.数据位置暴露给计算框架
c.适合大数据处理
.GB、TB、甚至PB级的数据处理
.百万规模以上的文件数据
.10000+的节点
d.可构建在廉价的机器上
.通过多副本存储,提高可靠性
.提供了容错和恢复机制
2.HDFS缺点
a.低延迟数据访问处理较弱
.毫秒级别的访问响应较慢
.低延迟和高吞吐率的请求处理较弱
b.大量小文件存取处理较弱
.会占用大量NameNode的内存
.寻道时间超过读取时间
c.并发写入、文件随机修改
.一个文件仅有一个写者
.仅支持Append写入
二、HDFS的架构
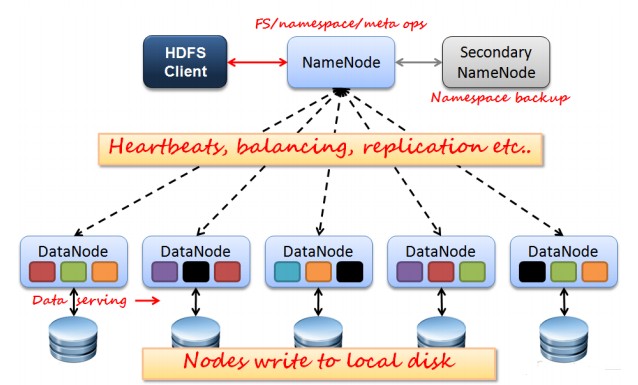
如上图所示,HDFS也是按照Master和Slave的结构。分NameNode、SecondaryNameNode、DataNode这几个角色。
NameNode:是Master节点,是大领导。管理数据块映射;处理客户端的读写请求;配置副本策略;管理HDFS的名称空间;
SecondaryNameNode:是一个小弟,分担大哥namenode的一部分工作量;是NameNode的冷备份;合并fsimage和fsedits然后再发给namenode。
DataNode:Slave节点,奴隶,干活的。负责存储client发来的数据块block;执行数据块的读写操作。
热备份:b是a的热备份,如果a坏掉。那么b马上运行代替a的工作。
冷备份:b是a的冷备份,如果a坏掉。那么b不能马上代替a工作。但是b上存储a的一些信息,减少a坏掉之后的损失。
fsimage:元数据镜像文件(文件系统的目录树。)
edits:元数据的操作日志(针对文件系统做的修改操作记录)
namenode内存中存储的是=fsimage+edits。
SecondaryNameNode负责定时默认1小时,从namenode上,获取fsimage和edits来进行合并,然后再发送给namenode。减少namenode的工作量。
三、HDFS数据存储单元(block)
1.文件被切割成固大小的数据块
a.默认数据块大小是64MB,数据块大小可配置
b.若数据块大小不到64MB,则单独成一个数据块
2.一个文件存储方式
a.按大小切割成若干个block,存储在不同的节点上
b.每个block默认存三个副本
block大小和副本数由Client上传文件的时候设置,文件上传成功以后,副本数可以变更,但是Block 大小不可变。
四、HDFS设计思想
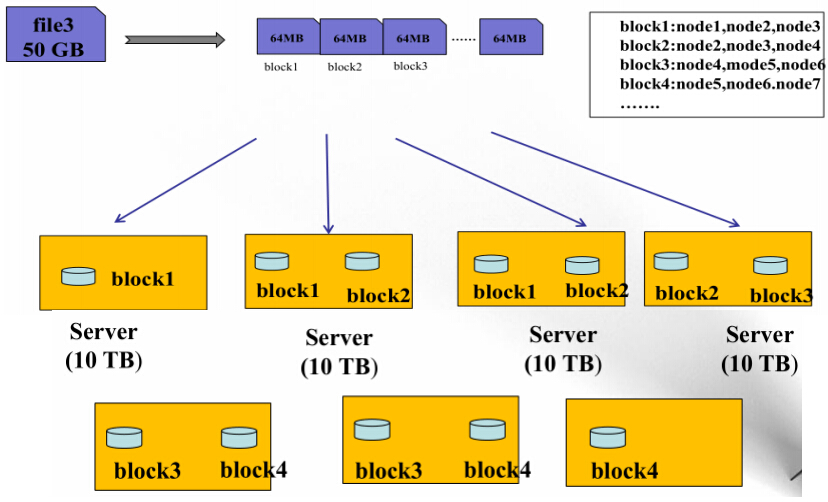
一个50G的文件上传到HDFS上,首先该文件被切割成了若干个64MB的block,block1在node1,node2,node3上存储了3(默认3个,可以设置)个副本,block2在node2,node3,node4上存储了3个副 本block3....直到所有的block都存储3个副本;
五、NameNode(NN)、 SencondryNameNode (SNN)、DataNode(DN)
1.NameNode (NN) 的工作
a.接受客户端的读写服务
b.保存metadata的信息,包括:文件的owership和permissions、文件包含哪些block、block保存在哪些DataNode节点上(在启动时由DataNode上报)
c.NameNode 的metadata信息会在启动后加载到内存中
.metadata信息在磁盘上存储的文件为“fsimage”
.Block的位置信息不保存在fsimage中(由DataNode上报)
.edits中保存对metadata的操作日志
2.SecondryNameNode(SNN) 的工作
a.它不是NN的备份(但可以做NN的部分备份的工作),它的主要工作是帮助NN合并edits log 减少NN的启动时间
b.SNN合并时机
.根据配置文件设置的时间间隔fs.checkpoint.period 默认3600秒
.根据配置文件设置的edits log的大小 fs.checpoint.size 默认的edits log 大小为64MB
c.SNN合并流程
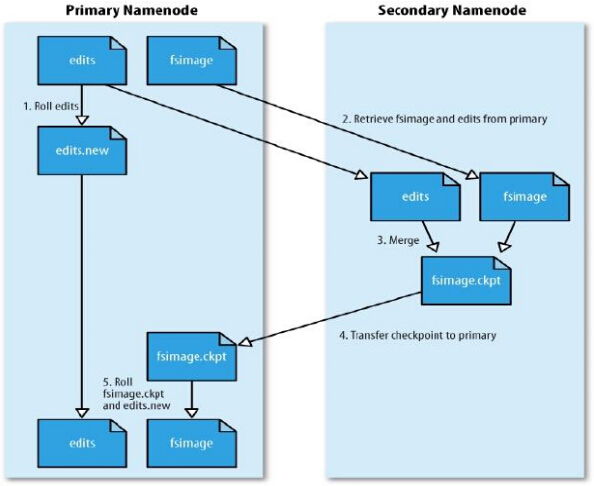
1>NN 创建一个新的edits log 来接替老的 edits 的工作
2>NN 将fsimage 和 旧的edits 拷备到 SNN上
3>SNN上进行合并操作,产生一个新的fsimage
4>将新的fsimage 复制一份到NN上
5>使用新的fsimage 和 新的edits log
3.DataNode (DN)
a.存储数块(block)
b.启动DN线程时,DN会自动向NN汇报Block的信息
c.NN向DN发送心跳检测,与其DN保持联系(3秒一次) 如果NN 连续10分钟没有收到DN的心跳,则认为该DN已经lost,并从其他DN中备份一份该DN上的所有block
d.block的放置策略
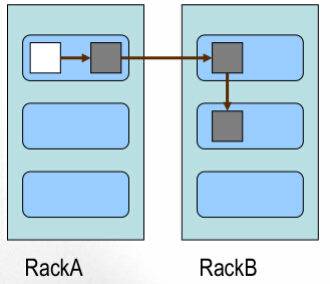
.第一个副本,放置在上传文件的DN上,如果是集群外提交,则随便选择一台磁盘、内存、CPU不太忙的节点存储
.第二个副本,放置在与第一个副本不同机架上的节点上
.第三个副本,放置在与第二个副本相同机架上的相邻的节点上
.更多副本随机放置
六、HDFS的写流程和读流程
1.HDFS写流程
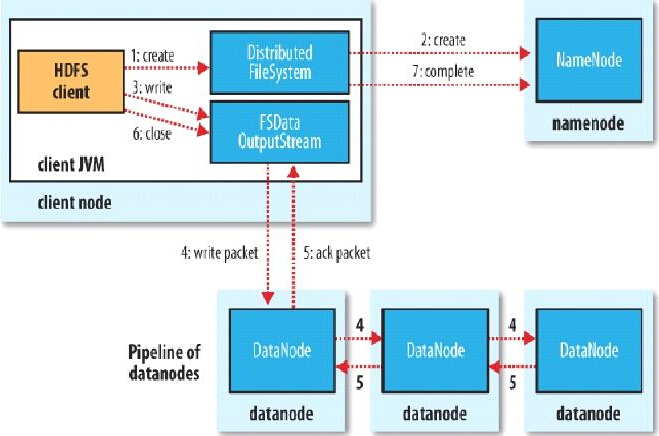
例:
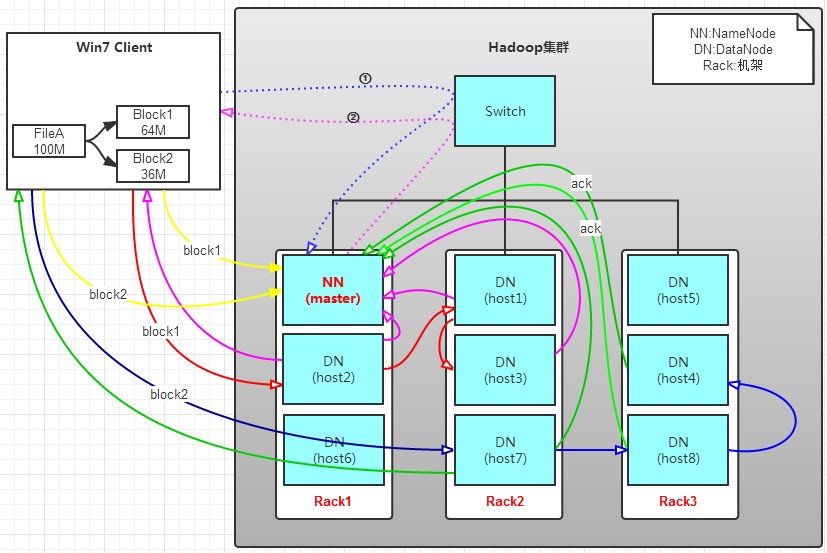
有一个文件FileA,100M大小。Client将FileA写入到HDFS上。
HDFS按默认配置。
HDFS分布在三个机架上Rack1,Rack2,Rack3。
a. Client将FileA按64M分块。分成两块,block1和Block2;
b. Client向nameNode发送写数据请求,如图蓝色虚线①------>。
c. NameNode节点,记录block信息。并返回可用的DataNode,如粉色虚线②--------->。
Block1: host2,host1,host3
Block2: host7,host8,host4
原理:
NameNode具有RackAware机架感知功能,这个可以配置。
若client为DataNode节点,那存储block时,规则为:副本1,同client的节点上;副本2,不同机架节点上;副本3,同第二个副本机架的另一个节点上;其他副本随机挑选。
若client不为DataNode节点,那存储block时,规则为:副本1,随机选择一个节点上;副本2,不同副本1,机架上;副本3,同副本2相同的另一个节点上;其他副本随机挑选。
d. client向DataNode发送block1;发送过程是以流式写入。
1>将64M的block1按64k的package划分;
2>然后将第一个package发送给host2;
3>host2接收完后,将第一个package发送给host1,同时client想host2发送第二个package;
4>host1接收完第一个package后,发送给host3,同时接收host2发来的第二个package。
5>以此类推,如图红线实线所示,直到将block1发送完毕。
6>host2,host1,host3向NameNode,host2向Client发送通知,说“消息发送完了”。如图粉红颜色实线所示。
7>client收到host2发来的消息后,向namenode发送消息,说我写完了。这样就真完成了。如图黄色粗实线
8>发送完block1后,再向host7,host8,host4发送block2,如图蓝色实线所示。
9>发送完block2后,host7,host8,host4向NameNode,host7向Client发送通知,如图浅绿色实线所示。
10>client向NameNode发送消息,说我写完了,如图黄色粗实线。。。这样就完毕了。
分析,通过写过程,我们可以了解到:
①写1T文件,我们需要3T的存储,3T的网络流量贷款。
②在执行读或写的过程中,NameNode和DataNode通过HeartBeat进行保存通信,确定DataNode活着。如果发现DataNode死掉了,就将死掉的DataNode上的数据,放到其他节点去。读取时,要读其他节点去。
③挂掉一个节点,没关系,还有其他节点可以备份;甚至,挂掉某一个机架,也没关系;其他机架上,也有备份。
2.读流程
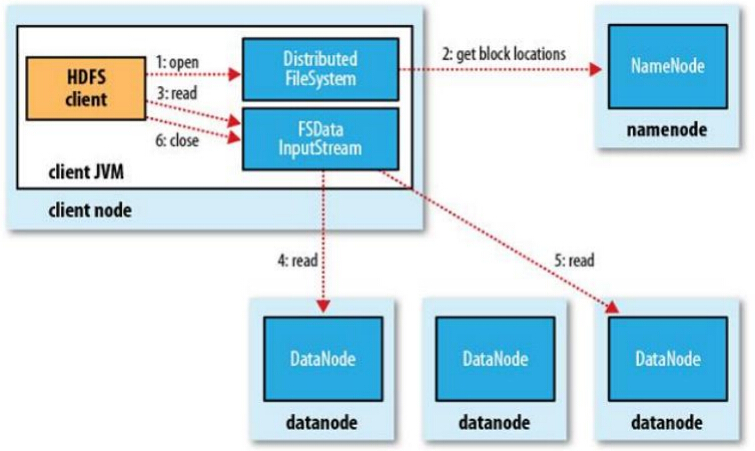
例:
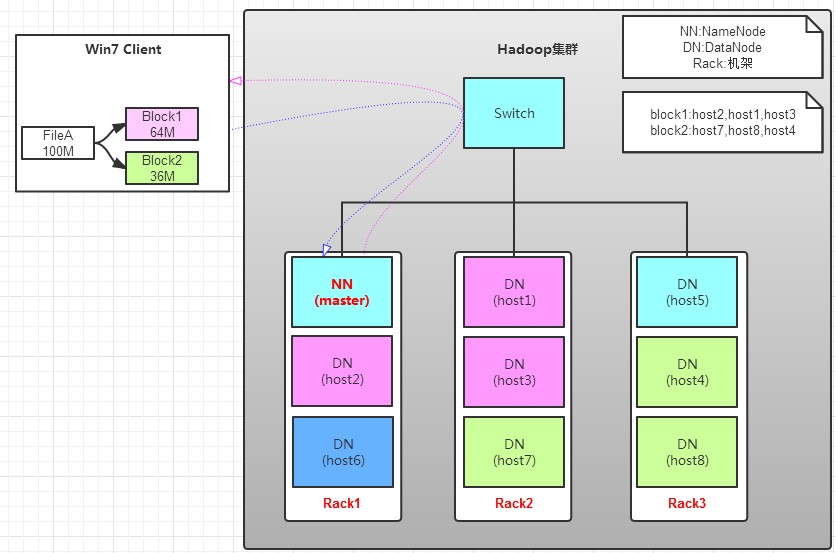
读操作就简单一些了,如图所示,client要从datanode上,读取FileA。而FileA由block1和block2组成。
那么,读操作流程为:
a. client向namenode发送读请求。
b. namenode查看Metadata信息,返回fileA的block的位置。
block1:host2,host1,host3
block2:host7,host8,host4
c. block的位置是有先后顺序的,先读block1,再读block2。而且block1去host2上读取;然后block2,去host7上读取;
七、HDFS文件权限
1.与linux系统文件权限类似
r:read w:write x:execute 权限x对于文件忽略,对于文件夹表示是否允许访问
2.如果linux系统用户zhangsan使用hadoop命令创建一个文件 ,那么该文件在HDFS中的所有者就是zhangsan。
3.HDFS权限的目:阻止好人做错事,而不是阻止坏人做坏事;例:只要是zhangsan上传的文件,那HDFS就认为这个文件属于张三,当下次过来操作的还是zhangsan那就可以操作,而不需要密码验证之类的操作。
八、安全模式
在NameNode启动以后会一段时间是处于安全模式,在安全模式下只可查看不能修进行其他操作,因为在安全模式下NN和DN需要做很多工作;
1.NN 启动的时候首先需要将fsimage 载入内存,并执行编辑日志中的各项操作。
2.一旦在文件系统中建立了一个新的元数据的映射,则创建一个新的fsimage 文件(与SNN配合)和一个空的edits文件
3.安全模式下的NameNode,对客户端是只读的(显示文件目录、内容等 ,其他的删除、修改、重命名操作都会失败)
4.在安全模式下,NameNode会收集来自DataNode汇报的block的信息,如果DN汇报的block的最副本数大于设置的最小副本数,则会认为是“安全”的。
如果有block的副本数没有达到设置的最小副本数,则该block会被复制直到达到设置的最小副本数为止。
https://my.oschina.net/bodi666/blog/797383
Hadoop 3、Hadoop 分布式存储系统 HDFS(好多彩色图)的更多相关文章
- Hadoop 3、Hadoop 分布式存储系统 HDFS
HDFS是Hadoop Distribute File System 的简称,也就是Hadoop的一个分布式文件系统. 一.HDFS的优缺点 1.HDFS优点: a.高容错性 .数据保存多个副本 .数 ...
- Hadoop整理二(Hadoop分布式存储系统HDFS)
一.背景 当数据集的大小超过一台独立物理计算机的存储能力时,就有必要对它进行分区(partition) 并存储到若干台单独的计算机上.管理网络中跨多台计算机存储的文件系统称为分布式文件系统 (dist ...
- 分布式存储系统-HDFS
1 HDFS 架构 HDFS作为分布式文件管理系统,Hadoop的基础.HDFS整体架构包括:NameNode.DataNode.Secondary NameNode,如图: HDFS采用主从式的分布 ...
- Hadoop分布式存储系统HDFS
1.hadoop fs 指令 -ls -ls <路径> 查看指定路径的当前目录结构 -lsr -lsr <路径> 递归查看指定路径的目录结构 -du -du <路径> ...
- [Hadoop 周边] Hadoop技术生态圈
Hadoop版本演进 当前Hadoop有两大版本:Hadoop 1.0和Hadoop 2.0. Hadoop1.0被称为第一代Hadoop,由分布式文件系统HDFS和分布式计算框架MapReduce组 ...
- 一图看懂hadoop分布式文件存储系统HDFS工作原理
一图看懂hadoop分布式文件存储系统HDFS工作原理
- Hadoop 三剑客之 —— 分布式文件存储系统 HDFS
一.介绍 二.HDFS 设计原理 2.1 HDFS 架构 2.2 文件系统命名空间 2.3 数据复制 2.4 数据复制的实现原理 2.5 副本的选择 2 ...
- Hadoop入门学习笔记-第一天 (HDFS:分布式存储系统简单集群)
准备工作: 1.安装VMware Workstation Pro 2.新建三个虚拟机,安装centOS7.0 版本不限 配置工作: 1.准备三台服务器(nameNode10.dataNode20.da ...
- 【转载】Hadoop分布式文件系统HDFS的工作原理详述
转载请注明来自36大数据(36dsj.com):36大数据 » Hadoop分布式文件系统HDFS的工作原理详述 转注:读了这篇文章以后,觉得内容比较易懂,所以分享过来支持一下. Hadoop分布式文 ...
随机推荐
- hive 分区表与数据产生关联的三种方式
所谓关联,可以理解为能够使用select查询到 1.load 这是最常用的一种方式 load data [local] inpath "数据路径" into table table ...
- Linux下安装mysql(1)(CentOS)
标题是(1)也就是说这次是基础安装,这种方式安装,没有组的创建,权限管理,配置文件更改等,仅仅是最基本的安装,适合第一次在linux上安装mysql的新手 1.准备好安装包(Linux-Generic ...
- [ACM] POJ 1094 Sorting It All Out (拓扑排序)
Sorting It All Out Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 26801 Accepted: 92 ...
- module.exports输出的属性被ES6如何引用的
阮一峰的ES6教程里有讲: import 命令加载 CommonJS 模块 Node 采用 CommonJS 模块格式,模块的输出都定义在module.exports这个属性上面.在 Node 环境中 ...
- vscode 如何格式化vue(template)html代码 , 保持标签属性不换行
微软的vscode 真心强大 , electron 框架写的 , 用js写的桌面应用 , 有能力的话大家可以分析一下人家的源码 , 反正我是看不了 , 太牛掰了 在一次跟新后我发现莫名奇妙的些在组件( ...
- 王立平--GC
Gabage Collection:垃圾回收 是.net中对内存管理的一种功能. 垃圾回收器跟踪并回收托管内存中分配的对象,定期运行垃圾回收以回收分配给没有有效引用的对象的内存. 当使用可用内存不能满 ...
- Like关系查询
比如:有表1.表2两张相,希望通过like进行关联查询 // mysql中使用concat连接字符串 select t1.id, t1.title, t2.keyword from t1 inner ...
- 机器学习: Tensor Flow +CNN 做笑脸识别
Tensor Flow 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库.节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数 ...
- matlab 高阶(一) —— assignin与evalin
1. assignin assignin(ws, 'var', val) 将 val 值赋值给 ws 空间中的 var 变量,注意这里的变量,必须是 array 类型,而不可以是包含下标索引,如果在指 ...
- hdu2083 简易版之最短距离
点A和点B之间随意一点到A的距离+到B的距离=|AB|,而AB外的一点到A的距离+到B的距离>|AB|: #include<math.h> #include<stdio.h&g ...