shp系列(六)——利用C++进行Dbf文件的写(创建)
上一篇介绍了shp文件的创建,接下来介绍dbf的创建。
推荐结合读取dbf的博客一起看!
推荐结合读取dbf的博客一起看!
推荐结合读取dbf的博客一起看!
1.Dbf头文件的创建
Dbf头文件的结构如下:

记录项数组说明:
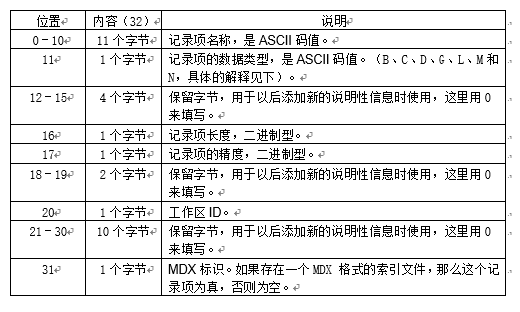
字段类型说明:

关于每项的具体含义参照读取dbf文件的解释,这里重点解释几项:
- HeaderByteNum指dbf头文件的字节数,数值不用除于2,具体为:从version到Reserved2(共32) + n个字段 * 每一个字段长度 32 + terminator。
- RecordByteNum指每条记录的字节数,数值不用除于2,RecordByteNum根据记录的实际长度来写,具体为:∑每个字段的字节数(字段数量根据读取打开shp的字段数决定)。例如我的例子中写了八个字段,则一条记录的实际长度为:1(deleteFlag) + 10 + 32 + 16 + 10 + 10 + 8 + 19 + 19 = 1 + 124 =125。
2.Dbf记录实体的创建
记录实体就是每条记录,一个记录有多个字段,部分字段上存储必要的信息。由于实际上每个shp文件的表的字段数可能不一样,并且每个字段的类型不固定,需要每次判定字段类型,然后根据不同类型设置来输出信息。
但是这费时费力,根据实际情况,简化一下,读取已知字段数和字段类型的DBF的信息,或者说,根据实际需要的字段数和字段类型来输出,牺牲普遍性来获取快速结果,以后修改也不困难。
3.创建Dbf的代码
void WriteDbf(CString filename)
{
//创建与Shp文件同名的指针
int n = filename.ReverseFind('.');
filename = filename.Left(n);
filename = filename + ".dbf";
FILE* m_DbfFile_fp;
if ((m_DbfFile_fp = fopen(filename, "wb")) == NULL)
return; //****创建dbf文件的文件头
int i, j;
BYTE version = 4;
fwrite(&version, 1, 1, m_DbfFile_fp);
CTime t = CTime::GetCurrentTime();
int d = t.GetDay();
int y = t.GetYear() % 2000;
int m = t.GetMonth();
BYTE date[3];
date[0] = y;
date[1] = m;
date[2] = d;
for (i = 0; i<3; i++) //记录时间
fwrite(date + i, 1, 1, m_DbfFile_fp); int RecordNum = map->layer->objects.size(); //文件中的记录条数
fwrite(&RecordNum, sizeof(int), 1, m_DbfFile_fp);
short HeaderByteNum = 0; //文件头中的字节数,暂时写0,后面要返回来修改
fwrite(&HeaderByteNum, sizeof(short), 1, m_DbfFile_fp);
short RecordByteNum = 0; //一条记录中的字节长度,暂时写0,后面要返回来修改
fwrite(&RecordByteNum, sizeof(short), 1, m_DbfFile_fp);
short Reserved1 = 0;
fwrite(&Reserved1, sizeof(short), 1, m_DbfFile_fp);
BYTE Flag4s = 0;
fwrite(&Flag4s, sizeof(BYTE), 1, m_DbfFile_fp);
BYTE EncrypteFlag = 0;
fwrite(&EncrypteFlag, sizeof(BYTE), 1, m_DbfFile_fp);
int Unused[3] = { 0,0,0 };
for (i = 0; i<3; i++)
fwrite(Unused + i, sizeof(int), 1, m_DbfFile_fp);
BYTE MDXFlag = 0;
fwrite(&MDXFlag, sizeof(BYTE), 1, m_DbfFile_fp);
BYTE LDriID = 0;
fwrite(&LDriID, sizeof(BYTE), 1, m_DbfFile_fp);
short Reserved2 = 0;
fwrite(&Reserved2, sizeof(short), 1, m_DbfFile_fp); //****写记录项数组
int fieldscount = fieldscount_final; //字段数量可以根据读取的shp文件确定
for (i = 0; i< fieldscount; i++)
{
RecordItem recordItem = recordItems[i]; //recordItems是自己设置的记录项数组(字段)的数组,
//根据需求设定每个记录项数组(字段)的参数,以供调用
//****name--------11 bytes
fwrite(recordItem.name, 11, 1, m_DbfFile_fp); //****FieldType----1 bytes
fwrite(&(recordItem.fieldType), sizeof(BYTE), 1, m_DbfFile_fp); //****Reserved3----4 bytes
fwrite(&(recordItem.Reserved3), sizeof(int), 1, m_DbfFile_fp); //****FieldLength--1 bytes
fwrite(&(recordItem.fieldLength), sizeof(BYTE), 1, m_DbfFile_fp); //****DecimalCount-1 bytes
fwrite(&(recordItem.decimalCount), sizeof(BYTE), 1, m_DbfFile_fp); //****Reserved4----2 bytes
fwrite(&(recordItem.Reserved4), sizeof(short), 1, m_DbfFile_fp); //****WorkID-------1 bytes
fwrite(&(recordItem.workID), sizeof(BYTE), 1, m_DbfFile_fp); //****Reserved5----10 bytes
for (j = 0; j<5; j++)
fwrite(recordItem.Reserved5 + j, sizeof(short), 1, m_DbfFile_fp); //****MDXFlag1-----1 bytes
fwrite(&(recordItem.mDXFlag1), sizeof(BYTE), 1, m_DbfFile_fp);
}
BYTE terminator = 13; //头文件终止标识符
fwrite(&terminator, sizeof(BYTE), 1, m_DbfFile_fp); fseek(m_DbfFile_fp, 8, SEEK_SET); //转到头文件字节数RecordByteNum,开始重写
HeaderByteNum = 32 + 32 * fieldscount + 1; //从version到Reserved2(共32) + n个字段 * 每一个字段长度 32 + terminator
fwrite(&HeaderByteNum, sizeof(short), 1, m_DbfFile_fp); RecordByteNum = 1 + 124; //RecordByteNum根据记录的实际长度来写,∑每个字段的长度
// 1 + 10 + 32 + 16 + 10 + 10 + 8 + 19 + 19 = 1 + 124 =125
fseek(m_DbfFile_fp, 10, SEEK_SET); //转移每条记录长度RecordByteNum
fwrite(&RecordByteNum, sizeof(short), 1, m_DbfFile_fp);
fseek(m_DbfFile_fp, 0, SEEK_END);
//****写dbf文件头结束 //****写每条记录
BYTE deleteFlag;
char media[40];
for (i = 1; i <= RecordNum; i++){
CGeoPolygon* polygon = (CGeoPolygon*)map->layer->objects[i - 1];
deleteFlag = 32; //默认写32
fwrite(&deleteFlag, sizeof(BYTE), 1, m_DbfFile_fp); //读取删除标记 1字节 //****写 ObjectID int
stringstream ss;
ss << (i - 1);
string str = ss.str();
int length = str.length();
memset(media, '\0', 40);
for (int m = 0; m < 10 - length; m++)
media[m] = ' '; for (int c = 10 - length; c < 10; c++)
media[c] = str[c - 10 + length]; for (j = 0; j<10; j++)
fwrite(media + j, sizeof(char), 1, m_DbfFile_fp); //--10 //****写Dest string
memset(media, '\0', 40);
media[0] = '/';
for (int c = 1; c <32; c++)
media[c] = ' '; for (j = 0; j<32; j++)
fwrite(media + j, sizeof(char), 1, m_DbfFile_fp); //--32 //****写Ec string
for (j = 0; j<16; j++)
fwrite(media + j, sizeof(char), 1, m_DbfFile_fp); //--16 //****写EcRm int
ss << -8888;
str = ss.str();
length = str.length();
memset(media, '\0', 40);
for (int m = 0; m < 10 - length; m++)
media[m] = ' '; for (int c = 10 - length; c < 10; c++)
media[c] = str[c - 10 + length]; for (j = 0; j<10; j++)
fwrite(media + j, sizeof(char), 1, m_DbfFile_fp); //--10 //****写Elevt int
for (j = 0; j<10; j++)
fwrite(media + j, sizeof(char), 1, m_DbfFile_fp); //--10 //****写Cc int
str = polygon->objectAttribute;
memset(media, '\0', 40);
length = str.length();
for (int c = 0; c < length; c++)
media[c] = str[c]; for (int c = length; c < 8; c++)
media[c] = ' '; for (j = 0; j<8; j++)
fwrite(media + j, sizeof(char), 1, m_DbfFile_fp); //--8 //****写shape_length double
CString str1;
double shape_length = polygon->getAllLength();
str1.Format(_T("%.11e"), shape_length);
memset(media, '\0', 40);
media[0] = ' ';
for (int c = 1; c < 16; c++)
media[c] = str1[c - 1]; if (str1.GetLength() == 18)
for (int c = 16; c < 19; c++)
media[c] = str1[c - 1];
else {
media[16] = '0';
media[17] = str1[15];
media[18] = str1[16];
}
//*(media + length ) = '\0';
for (j = 0; j<19; j++)
fwrite(media + j, sizeof(char), 1, m_DbfFile_fp); //--19 //****写shape_Area double
double shape_area = polygon->shapeArea;
str1.Format(_T("%.11e"), shape_area);
memset(media, '\0', 40);
media[0] = ' ';
for (int c = 1; c < 16; c++)
media[c] = str1[c - 1]; if (str1.GetLength() == 18)
for (int c = 16; c < 19; c++)
media[c] = str1[c - 1];
else {
media[16] = '0';
media[17] = str1[15];
media[18] = str1[16];
}
for (j = 0; j<19; j++)
fwrite(media + j, sizeof(char), 1, m_DbfFile_fp); //--19
}
//****写dbf文件记录结束 fclose(m_DbfFile_fp);
}
下一篇将介绍Shx的创建。
shp系列(六)——利用C++进行Dbf文件的写(创建)的更多相关文章
- shp系列(三)——利用C++进行DBF文件的读(打开)
1.DBF文件要点 DBF文件又叫属性文件,也叫dBASE文件,文件后缀是.dbf,实际上ArcGIS打开后的属性表就是DBF的信息.DBF文件遵循以下几个条件: 每个要素在表中必须要包含一个与之相对 ...
- shp系列(七)——利用C++进行Shx文件的写(创建)
之前介绍了Shp文件和Dbf的写(创建),最后来介绍一下Shx文件的写(创建).Shx文件是三者之中最简单的一个,原因有两个:第一是Shx文件的头文件与Shp文件的头文件几乎一样(除了FileLeng ...
- python常识系列07-->python利用xlwt写入excel文件
前言 读书之法,在循序而渐进,熟读而精思.--朱熹 抽空又来写一篇,毕竟知识在于分享! 一.xlwt模块是什么 python第三方工具包,用于往excel中写入数据:(ps:只能创建新表格,不能修改表 ...
- PB导出规定格式DBF文件
最近在做一个给卫计委做数据上报的数据接口,接口要求使用奇葩的dBase 3数据库存储上报数据,忙活了几天总算搞好了,使用开发工具为powerbuild 12,222个字段的上报数据表生成DBF文件,写 ...
- PB导出规定格式DBF文件 dBase 3 格式 222个字段
最近在做一个给卫计委做数据上报的数据接口,接口要求使用奇葩的dBase 3数据库存储上报数据,忙活了几天总算搞好了,使用开发工具为powerbuild 12,222个字段的上报数据表生成DBF文件,写 ...
- shp系列(五)——利用C++进行shp文件的写(创建)
之前介绍了shp文件.dbf文件和shx文件的的读取,接下来将分别介绍它们的创建过程.一般来说,读和写的一一对应的,写出的文件就是为了保存数据供以后读取的.写的文件要符合shapefile的标准.之前 ...
- shp系列(一)——利用C++进行shp文件的读(打开)与写(创建)开言
博客背景和目的 最近在用C++写一个底层的东西,需要读取和创建shp文件.虽然接触shp文件已经几年了,但是对于shp文件内到底包含什么东西一直是一知半解.以前使用shp文件都是利用软件(如ArcGI ...
- shp系列(二)——利用C++进行shp文件的读(打开)
1.各数据类型及其字节数 BYTE 1; char 1; short 2; int 4; double 8; 2.位序big和little及其转换 对于位序是big的 ...
- Java读取Level-1行情dbf文件极致优化(3)
最近架构一个项目,实现行情的接入和分发,需要达到极致的低时延特性,这对于证券系统是非常重要的.接入的行情源是可以配置,既可以是Level-1,也可以是Level-2或其他第三方的源.虽然Level-1 ...
随机推荐
- 国外AI界牛人主页 及资源链接
感觉 好博客要收集,还是贴在自己空间里难忘!!! 原文链接:http://blog.csdn.net/hitwengqi/article/details/7907366 http://people.c ...
- 输出字符串格式化/ Linq对数组操作 /一个按钮样式
textBox1.Text = dateTimePicker1.Value.ToString("yyyy-MM-dd HH:mm:ss"); , , , , , , , , , , ...
- grep命令总结
grep (缩写来自Globally search a Regular Expression and Print)是一种强大的文本搜索工具,它能使用特定模式匹配(包括正则表达式)搜索文本,并默认输出匹 ...
- 【剑指Offer】10、矩形覆盖
题目描述: 我们可以用2 X 1的小矩形横着或者竖着去覆盖更大的矩形.请问用n个2 X 1的小矩形无重叠地覆盖一个2 X n的大矩形,总共有多少种方法? 解题思路: 我们可以以2 X ...
- USACO 4.1 Fence Rails
Fence RailsBurch, Kolstad, and Schrijvers Farmer John is trying to erect a fence around part of his ...
- uwsgi部署django,里的request调用的接口响应慢解决方法
解决方法,增加2个线程 uwsgi.ini 配置如下 chdir=/var/www/Ultramanpidfile=/tmp/uwsgi.pidmodule=Ultraman.wsgimaster=t ...
- javascript实现:在N个字符串中找出最长的公子串
'use strict' module.exports = function 找出最长公子串 (...strings) { let setsOfSubstrings = [] strings.redu ...
- 自己总结的php开发中用到的工具
需要一个编辑器IDE,推荐用phpstorm. IDE安装完了,还要搞个Xdebug,这个很有用,程序断点跟踪调试就靠他了. phpstom平时使用的时候,编辑界面感觉很枯燥的时候,可以换个主题,换主 ...
- android网络类型之2G-3G切换
在android手机‘设置’-‘移动网络类型’里可以看到有关网络类型的选项,一般默认为3G优先. 如果有需要在程序中切换网络类型的朋友,不妨试试下面的方法.这里提供了几种思路,虽然可能对待 手机的方式 ...
- MDK(KEIL5)如何生成.bin文件 【转】
最近要做个bin文件,网上找了好多都说的不够清楚,后来找到一篇实测可用,说明清楚的,转过来以便学习用. 参考传送门:https://blog.csdn.net/nx505j/article/detai ...