R语言-方差分析
方差分析指的是不同变量之间互相影响从而导致结果的变化
1.单因素方差分析:
案例:50名患者接受降低胆固醇治疗的药物,其中三种治疗条件使用药物相同(20mg一天一次,10mg一天两次,5mg一天四次),剩下的两种方式是(drugE和drugD),代表候选药物
哪种药物治疗降低胆固醇的最多?
library(multcomp)
attach(cholesterol)
# 1.各组样本大小
table(trt)
# 2.各组均值
aggregate(response,by=list(trt),FUN=mean)
# 3.各组标准差
aggregate(response,by=list(trt),FUN=sd)
# 4.检验组间差异
fit <- aov(response ~ trt)
summary(fit)
library(gplots)
# 5.绘制各组均值和置信区间
plotmeans(response ~ trt,xlab = 'Treatment',ylab = 'Response',main='MeanPlot\nwith 95% CI')
detach(cholesterol)
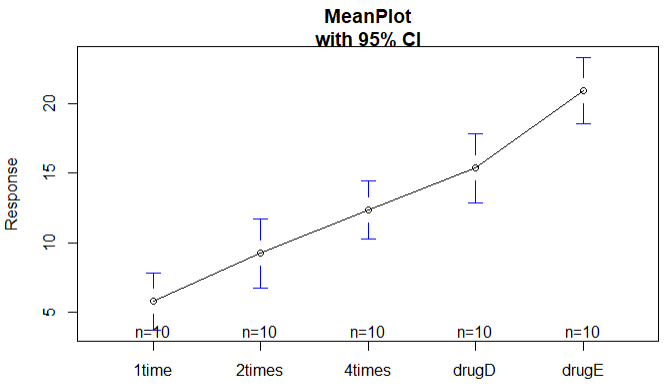
结论:
1.均值显示drugE降低胆固醇最多,1time降低胆固醇最少.
2.说明不同疗法之间的差异很大
多重比较药品和服药次数
library(multcomp)
par(mar=c(5,4,6,2))
tuk <- glht(fit,linfct=mcp(trt='Tukey'))
plot(cld(tuk,level=.05),col='lightgrey')
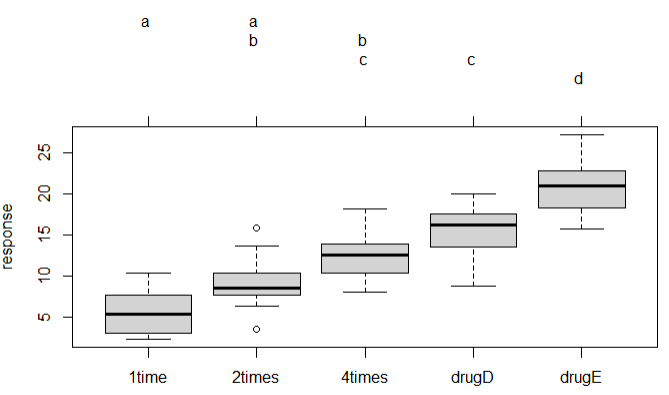
结论:每天复用4次和使用drugE的时候治疗胆固醇效果最好
评估检验的假设条件
library(car)
qqPlot(lm(response ~ trt,data=cholesterol),simulate=T,main='Q-Q Plot',labels=F)
bartlett.test(response ~ trt,data=cholesterol)
# 检测离群点
outlierTest(fit)
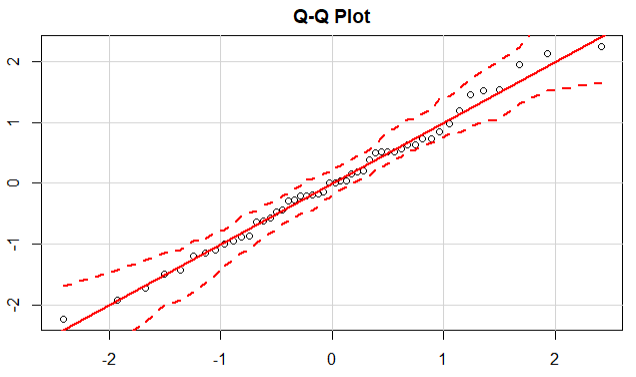
结论:数据落在95%置信区间的范围内,说明数据点满足正态性假设
2.单因素协方差分析
案例:怀孕的小鼠被分为4各小组,每个小组接受不同剂量的药物剂量(0.5,50,500)产下小鼠体重为因变量,怀孕时间为协变量
data(litter,package = 'multcomp')
attach(litter)
table(dose)
aggregate(weight,by=list(dose),FUN=mean)
fit2 <- aov(weight ~ gesttime + dose)
summary(fit2)
library(effects)
# 取出协变量计算调整的均值
effect('dose',fit2)
contrast <- rbind('no drug vs drug' = c(3,-1,-1,-1))
summary(glht(fit2,linfct=mcp(dose=contrast)))
library(HH)
ancovaplot(weight ~ gesttime + dose,data=litter)



结论:0剂量产仔20个,500剂量产仔17个
0剂量的体重在32左右,500剂量在30左右
怀孕时间和体重相关
用药剂量和体重相关
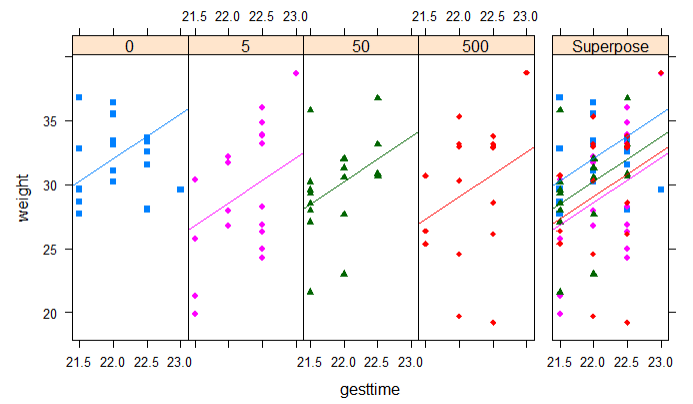
结论:小鼠的体重和怀孕时间成正比和剂量成反比
3.双因素方差分析
案例:随机分配60只豚鼠,分别采用两种喂食方法(橙汁或者维C),各种喂食方法中含有抗坏血酸3钟含量(0.5,1,2)
每种处理组合都分配10只豚鼠,牙齿长度为因变量
attach(ToothGrowth)
table(supp,dose)
aggregate(len,by=list(supp,dose),FUN=mean)
aggregate(len,by=list(supp,dose),FUN=sd)
# 将dose转换为因子变量,这样就不是一个协变量
dose <- factor(dose)
fit3 <- aov(len ~ supp*dose)
summary(fit3)
detach(ToothGrowth)
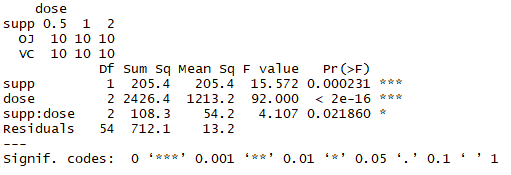
结论:主效应的对豚鼠牙齿影响很大
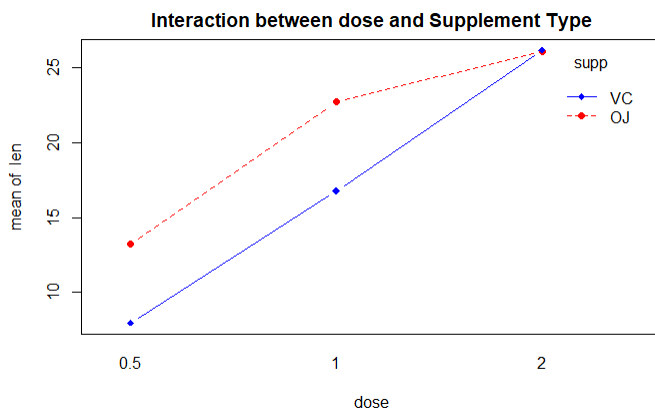
结论:在0.5~1mg的区间中维C的豚鼠的牙齿长度超过使用橙汁的小鼠,在1~2的区间内同理,当超过2mg时,两者对豚鼠牙齿的影响相同
4.重复测量方差
案例:在一定浓度的CO2的环境中比较寒带植物和非寒带植物的光合作用率进行比较
CO2$conc <- factor(CO2$conc)
w1b1 <- subset(CO2,Treatment == 'chilled')
fit4 <- aov(uptake ~ conc*Type + Error(Plant/(conc)),w1b1)
summary(fit4)
par(las=2)
par(mar=c(10,4,4,2))
with(w1b1,interaction.plot(conc,Type,uptake,type='b',col=c('red','blue'),pch=c(16,18),
main='Interaction plot for plant type and concentration'))
boxplot(uptake~Type*conc,data=w1b1,col=c('gold','green'),
main = 'Chilled Quebec and Mississippi Plants',
ylab="Carbon dioxide uptake rate (umol/m^2 sec)")
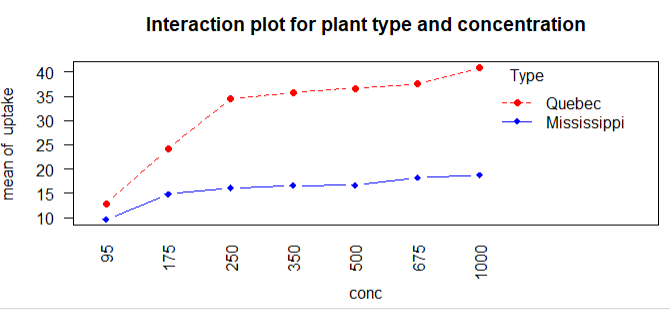
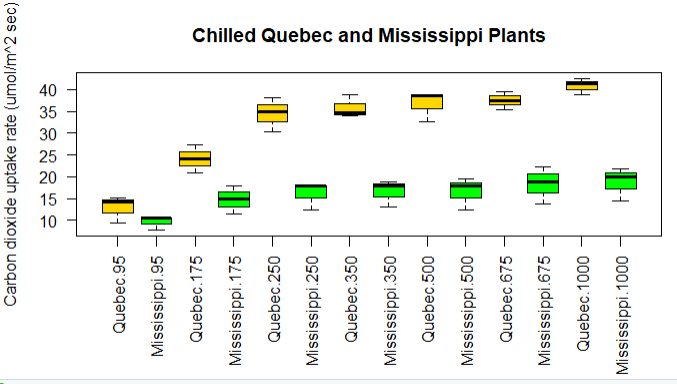
结论:魁北克的植物比密西西比州的二氧化碳的吸收率高,随着CO2的浓度体高,效果越明显
5.多元方差分析
案例:研究美国食物中的卡路里,脂肪,糖分是否会因货架的不同而不同
library(MASS)
attach(UScereal)
shelf <- factor(shelf)
y <- cbind(calories,fat,sugars)
aggregate(y,by=list(shelf),FUN=mean)
cov(y)
fit5 <- manova(y ~ shelf)
summary(fit5)
summary.aov(fit5)
找出离群点
center <- colMeans(y)
n <- nrow(y)
p <- ncol(y)
cov <- cov(y)
d <- mahalanobis(y,center,cov)
coord <- qqplot(qchisq(ppoints(n),df=p),d,
main="QQ Plot Assessing Multivariate Normality",
ylab="Mahalanobis D2")
abline(a=0,b=1)
identify(coord$x,coord$y,labels = row.names(UScereal))
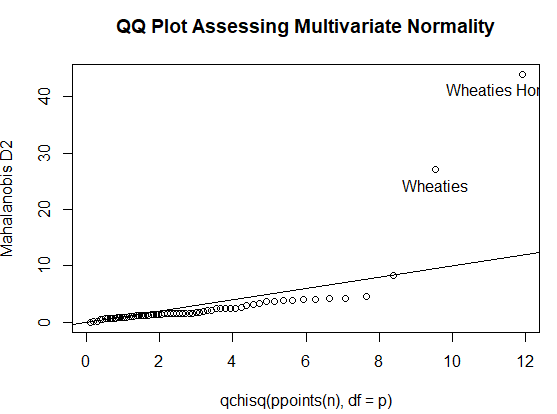
结论:在不同的货架上的谷物营养成分不同,有两个产品不符合多元正态分布
library(rrcov)
# 稳健多元方差分析
Wilks.test(y,shelf,method='mcd')
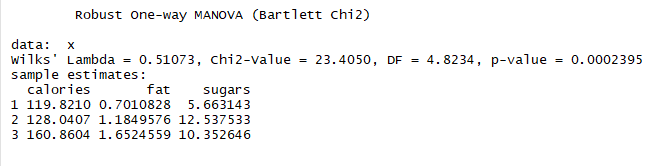
结论:稳健检测对离群点和违反MANOVA不敏感,证明了在不同货架的谷物营养成分不同的结论
R语言-方差分析的更多相关文章
- 实验的方差分析(R语言)
实验设计与数据处理(大数据分析B中也用到F分布,故总结一下,加深印象)第3课小结--实验的方差分析(one-way analysis of variance) 概述 实验结果\(S\)受多个因素\(A ...
- R语言实战(五)方差分析与功效分析
本文对应<R语言实战>第9章:方差分析:第10章:功效分析 ================================================================ ...
- 用R语言的quantreg包进行分位数回归
什么是分位数回归 分位数回归(Quantile Regression)是计量经济学的研究前沿方向之一,它利用解释变量的多个分位数(例如四分位.十分位.百分位等)来得到被解释变量的条件分布的相应的分位数 ...
- 如何在R语言中使用Logistic回归模型
在日常学习或工作中经常会使用线性回归模型对某一事物进行预测,例如预测房价.身高.GDP.学生成绩等,发现这些被预测的变量都属于连续型变量.然而有些情况下,被预测变量可能是二元变量,即成功或失败.流失或 ...
- R语言实战(三)基本图形与基本统计分析
本文对应<R语言实战>第6章:基本图形:第7章:基本统计分析 =============================================================== ...
- R语言书籍的学习路线图
现在对R感兴趣的人越来越多,很多人都想快速的掌握R语言,然而,由于目前大部分高校都没有开设R语言课程,这就导致很多人不知道如何着手学习R语言. 对于初学R语言的人,最常见的方式是:遇到不会的地方,就跑 ...
- R语言实战
教材目录 第一部分 入门 第一章 R语言介绍 第二章 创建数据集 第三章 图形初阶 第四章 基本数据管理 第五章 高级数据管理 第二部分 基本方法 第六章 基本图形 第七章 基本统计方法 第三部分 中 ...
- 机器学习 1、R语言
R语言 R是用于统计分析.绘图的语言和操作环境.R是属于GNU系统的一个自由.免费.源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具. 特点介绍 •主要用于统计分析.绘图.数据挖掘 •R内置 ...
- 数据分析与R语言
数据结构 创建向量和矩阵 函数c(), length(), mode(), rbind(), cbind() 求平均值,和,连乘,最值,方差,标准差 函数mean(), sum(), min(), m ...
随机推荐
- 暑假集训-WHUST 2015 Summer Contest #0.2
ID Origin Title 10 / 55 Problem A Gym 100625A Administrative Difficulties 4 / 6 Problem B Gym 1006 ...
- 记录一下sql两个表关联的查询使用方法
SELECT * FROM t_yymp_user_info where user_id = (select b.user_id from t_yymp_auth_role as a,t_yymp_a ...
- codeforces 140E.New Year Garland
传送门: 解题思路: 要求相邻两行小球颜色集合不同,并且限制行内小球相邻不同. 由此可得:每行小球排列都是独立与外界的, 所以答案应该是对于所有行的颜色集合分类,在将行内的答案乘到上面. 先考虑如何分 ...
- cache基本结构
下图为direct mapped set associative fully associative图示 direct mapped,相当于set number为1 fully ...
- 洛谷 P3585 [POI2015]PIE
P3585 [POI2015]PIE 题目描述 一张n*m的方格纸,有些格子需要印成黑色,剩下的格子需要保留白色.你有一个a*b的印章,有些格子是凸起(会沾上墨水)的.你需要判断能否用这个印章印出纸上 ...
- ArcGIS 空间查询一例
ISpatialFilter spatialFilter = new SpatialFilterClass(); spatialFilter.Geometry = Polygon ;//设置用于筛选几 ...
- android 获取蓝牙已连接设备
蓝牙如果手动配对并已连接,获取连接的设备: 1.检测连接状态: int a2dp = bluetoothAdapter.getProfileConnectionState(BluetoothProfi ...
- layer:web弹出层解决方案
layer:web弹出层解决方案 一.总结 一句话总结:http://layer.layui.com/ 1.layer中弹出层tips的使用(代码)是怎样的? 使用还是比较简单方便的 //tips层- ...
- js--基于面向对象的组件开发及案例
组件的开发:多组对象之间想兄弟关系一样,代码复用的形式. 问题:1).参数不写会报错:利用对象复制————配置参数和默认惨啊书的覆盖关系(逻辑或也可以)2).参数特别多时会出现顺序问题:json解决 ...
- HTML中行内元素与块级元素有哪些及区别
二.行内元素与块级元素有什么不同? 块级元素和行内元素的区别是,块级元素会占一行显示,而行内元素可以在一行并排显示. 通过样式控制,它们可以相互转换. 1.尺寸-块级元素和行内元素之间的一个重要的不同 ...