TensorFlow框架(3)之MNIST机器学习入门
1. MNIST数据集
1.1 概述
Tensorflow框架载tensorflow.contrib.learn.python.learn.datasets包中提供多个机器学习的数据集。本节介绍的是MNIST数据集,其功能都定义在mnist.py模块中。
MNIST是一个入门级的计算机视觉数据集,它包含各种手写数字图片:

图 11
它也包含每一张图片对应的标签,告诉我们这个是数字几。比如,上面这四张图片的标签分别是5,0,4,1
1.2 加载
有两种方式可以获取MNIST数据集:
TensorFlow框架提供了一个函数:read_data_sets,该函数能够实现自动下载的功能。如下所示的程序,就能够自动下载数据集。
|
from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) |
|
//由于input_data只是对read_data_sets进行了包装,其什么也没有做,所以我们可以直接使用read_data_sets. From tensorflow.contrib.learn.python.learn.datasets.mnist import read_data_sets Mnist=read_data_sets("MNIST_data",one_hot=True) |
用户也能够手动下载数据集,然后向read_data_sets函数传递所在的本地目录,如下所示:
|
from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("/tmp/MNIST_data/", False, one_hot=True) |
PS:
MNIST数据集可以Yann LeCun's website进行下载,如所示是下载后的目录:/tmp/MNIST_data/
图 12
1.3 结构
自动下载方式的数据集被分成如表 11所示的三部分。这样的切分很重要,在机器学习模型设计时必须有一个单独的测试数据集不用于训练,而是用来评估这个模型的性能,从而更加容易把设计的模型推广到其他数据集上(泛化)。
表 11
|
数据集 |
目的 |
|
mnist.train |
55000 组图片和标签, 用于训练。 |
|
mnist.test |
10000 组图片和标签, 用于最终测试训练的准确性。 |
|
mnist.validation |
5000 组图片和标签, 用于迭代验证训练的准确性。 |
PS:
若是手动下载则只有两部分,即表中的train和test两部分。
正如前面提到的一样,每一个MNIST数据单元有两部分组成:一张包含手写数字的图片和一个对应的标签。我们把这些图片设为"X",把这些标签设为"Y"。训练数据集和测试数据集都包含X和Y,比如训练数据集的图片是 mnist.train.images ,训练数据集的标签是 mnist.train.labels。
其中每一张图片包含28像素*28像素。我们可以用一个数字数组来表示这张图片:
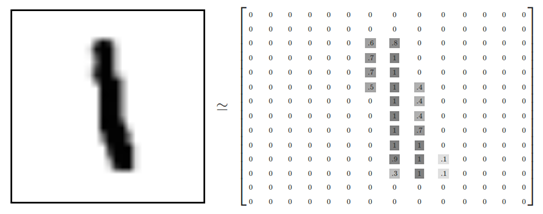
图 13
TensorFlow把这个数组展开成一个向量(数组),长度是 28x28 = 784,即TensorFlow将一个二维的数组展开成一个一维的数组,从[28, 28]数组转换为[784]数组。因此,在MNIST训练数据集中,mnist.train.images 是一个形状为 [60000, 784] 的张量,第一个维度数字用来索引图片,第二个维度数字用来索引每张图片中的像素点。在此张量里的每一个元素,都表示某张图片里的某个像素的灰度值,值介于0和1之间,如图 14所示的二维结构。
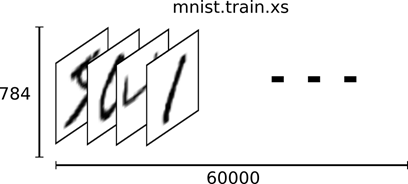
图 14
相对应的MNIST数据集的标签是介于0到9的数字,用来描述给定图片里表示的数字。为了用于这个教程,我们使标签数据是"one-hot vectors"。一个one-hot向量除了某一位的数字是1以外其余各维度数字都是0。所以在此教程中,数字n将表示成一个只有在第n维度(从0开始)数字为1的10维向量。比如,标签0将表示成([1,0,0,0,0,0,0,0,0,0,0])。因此,mnist.train.labels 是一个 [60000, 10] 的数字矩阵。
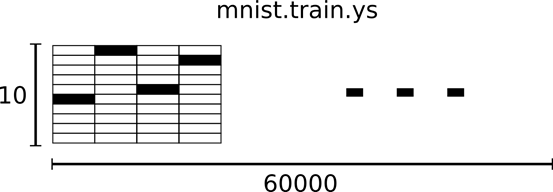
图 15
2. MNIST分类学习
2.1 实现理论
2.1.1 M-P神经元模型
传统的M-P神经元模型中,每个神经元都接收来自n个其它神经元传递过来的输入信号,这些输入信号通过待权重的连接进行传递,神经元接收到的总输入值将与神经元的阈值进行比较,然后通过"激活函数"处理以产生神经元的输出。如图 21所示的一个神经元模型。
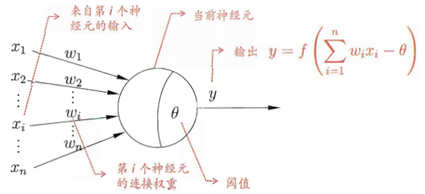
图 21
PS:
图中所示的值都为real value,并非为向量或矩阵。
2.1.2 softmax函数
softmax函数与sigmoid函数类似都可以作为神经网络的激活函数。sigmoid将一个real value映射到(0,1)的区间(当然也可以是(-1,1)),这样可以用来做二分类。
而softmax把一个k维的real value向量[a1,a2,a3,a4….]映射成一个[b1,b2,b3,b4….],其中bi是一个0-1的常数,然后可以根据bi的大小来进行多分类的任务,如取权重最大的一维。
所以对于MNIST分类任务是多分类类型,所以需要使用softmax函数作为神经网络的激活函数。
2.1.3 MNIST模型分析
正如图 14所分析的,输入的训练图片或测试图片为一个[60000, 784]的矩阵,每张图片都是一个[784]的向量;输出为一个[60000, 10]的矩阵,每张图片都对应有一个[10]的向量标签。所以对于每张图片的输入和每个标签的输出,其神经网络模型可表示为错误! 未找到引用源。所示的简化版本,图中所有值都为read value。
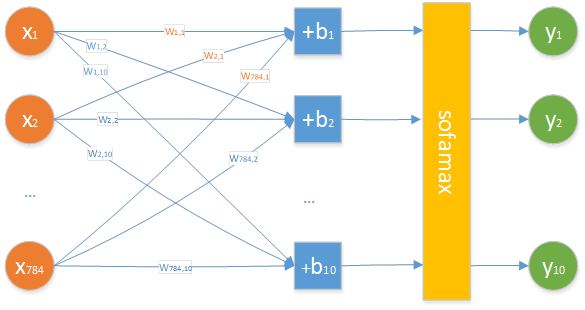
图 22 前馈神经网络(一个带有10个神经元的隐藏层)
如果把它写成一个等式,我们可以得到:
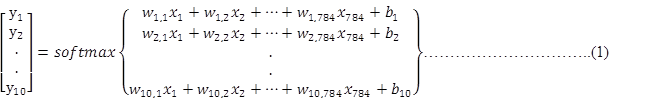
我们也可以用向量表示这个计算过程:用矩阵乘法和向量相加。这有助于提高计算效率。(也是一种更有效的思考方式)
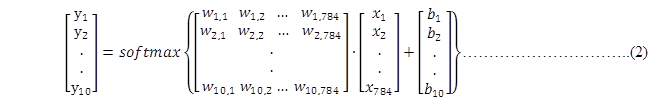
更进一步,可以写成更加紧凑的方式:
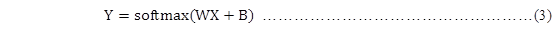
式中, B和Y都为一个[10]类型的向量,X为一个[784]类型的向量,W是一个[10,784]类型的矩阵。
2.2 TensorFlow实现
对于机器学习中的监督学习任务可以分四个步骤完成,如下所示:
- 模型选择:选择一个estimator对象;
- 模型训练:根据训练数据集来训练模型;
- 模型测试:测量模型的泛化能力,即对其评分;
- 模型应用:进行实际预测或应用。
2.2.1 模型选择
由于我们已经选择神经网络为监督学习任务的模型,即式(3)所示的等式,我们可通过使用下标来表明等式中变量的维数,如下所示:
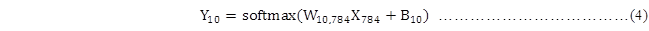
所以在TensorFlow中的实现,就需要定义相应的变量和等式。但是式(4)中的X是一个[784]的向量,而实际待训练的输入数据是一个[60000, 784] 的矩阵,所以需要对式(4)进行稍微的变形,使其满足数据输入和数据输出的要求,即如下所示的等式:

- X是输入参数,为训练数据,即多张图像;
- W和B是未知参数,即通过神经网络来训练的数据;
- Y为输出参数,为图像标签,将使用该值与已知标签进行比较。
如下所示是TensorFlow的实现:
|
# Create the model x = tf.placeholder("float", [None, 784]) W = tf.Variable(tf.zeros([784,10])) b = tf.Variable(tf.zeros([10])) y = tf.nn.softmax(tf.matmul(x,W) + b) |
2.2.2 模型训练
我们可以创建一个模型(model),但我们仍然不知道模型的好坏。为了评估一个TensorFlow模型的性能,我们可以提供一个期望值,然后比较模型产生值和期望值之差来进行评估。
传统方法采用"均分误差"法评估一个模型的性能: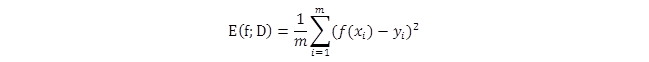 ,首先提供一个期望向量,然后对产生值(f(x))和期望值(y)两个向量的每个元素进行取平方差,然后求出每个元素的总和。
,首先提供一个期望向量,然后对产生值(f(x))和期望值(y)两个向量的每个元素进行取平方差,然后求出每个元素的总和。
由于传递神经网络采用梯度下降法来逐渐调整式(4)中的W和B参数,即逐步减少均分误差的值;然而若以"均分误差"为标准逐步调整参数,其归约的速度非常慢。所以提出以"交叉熵"法为标准评估模型的值,如下所示:
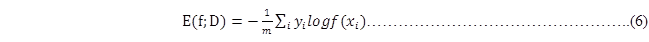
如下所示的TensorFlow实现:
|
# Define loss and optimizer y_ = tf.placeholder("float", [None,10]) cross_entropy = -tf.reduce_sum(y_ * tf.log(y)) |
TensorFlow提供多个优化器来逐步优化模型,即逐步优化未知参数。优化器以用户指定的评估的误差为优化目标,即最小化模型评估的误差,或最大化模型评估的误差。
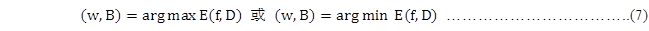
优化器基于梯度下降法自动修改神经网络的训练参数,即W和b的值。
如下是以GradientDescentOptimizer优化器为示例的训练过程:
|
# Train train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy) for i in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys}) |
2.2.3 模型测试
为了评估模型的泛化性能,我们通过比较产生值(f(x))和期望值(y)之间的差异来进行评测性能。
由于本节的MNIST数据标签(输出值)是一个one-hot的便利,向量中的元素直邮一个为"1",所以使用特性的比较方式,如下所示是TensorFlow的实现:
|
# Test trained model correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})) |
其中:
- tf.argmax:能给出某个tensor对象在某一维上的其数据最大值所在的索引值。由于标签向量是由0,1组成,因此最大值1所在的索引位置就是类别标签。
- tf.cast:类型转换,将一个tensor对象的所有元素类型转换为另一种类型。即上述将tf.equal方法生成的布尔值转换成浮点数。
- tf.reduce_mean:求矩阵或向量的平均值。若x=[[1., 1.] [2., 2.]],则tf.reduce_mean(x) ==> 1.5=(1+1+2+2)/4,
上述三个小节的完整程序如下所示:
|
from __future__ import print_function import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data # Import data mnist = input_data.read_data_sets("/tmp/MNIST_data/", False, one_hot=True) # Create the model x = tf.placeholder("float", [None, 784]) W = tf.Variable(tf.zeros([784,10])) b = tf.Variable(tf.zeros([10])) y = tf.nn.softmax(tf.matmul(x,W) + b) # Define loss and optimizer y_ = tf.placeholder("float", [None,10]) cross_entropy = -tf.reduce_sum(y_ * tf.log(y)) train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy) init = tf.initialize_all_variables() sess = tf.Session() sess.run(init) # Train for i in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys}) # Test trained model #下述y的值是在上述训练最后一步已经计算获得,所以能够与原始标签y_进行比较 correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})) |
3. 参考文献
TensorFlow框架(3)之MNIST机器学习入门的更多相关文章
- [转]MNIST机器学习入门
MNIST机器学习入门 转自:http://wiki.jikexueyuan.com/project/tensorflow-zh/tutorials/mnist_beginners.html?plg_ ...
- tensorfllow MNIST机器学习入门
MNIST机器学习入门 这个教程的目标读者是对机器学习和TensorFlow都不太了解的新手.如果你已经了解MNIST和softmax回归(softmax regression)的相关知识,你可以阅读 ...
- Tensorflow学习笔记(一):MNIST机器学习入门
学习深度学习,首先从深度学习的入门MNIST入手.通过这个例子,了解Tensorflow的工作流程和机器学习的基本概念. 一 MNIST数据集 MNIST是入门级的计算机视觉数据集,包含了各种手写数 ...
- 21个项目玩转深度学习:基于TensorFlow的实践详解01—MNIST机器学习入门
数据集 由Yann Le Cun建立,训练集55000,验证集5000,测试集10000,图片大小均为28*28 下载 # coding:utf-8 # 从tensorflow.examples.tu ...
- Tensorflow之MNIST机器学习入门
MNIST机器学习的原理: 通过一次次的 输入某张图片的像素值(用784维向量表示)以及这张图片对应的数字(用10维向量表示比如数字1用[0,1,0,0,0,0,0,0,0,0]表示),来优化10*7 ...
- 【TensorFlow篇】--Tensorflow框架初始,实现机器学习中多元线性回归
一.前述 TensorFlow是谷歌基于DistBelief进行研发的第二代人工智能学习系统,其命名来源于本身的运行原理.Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算,T ...
- MNIST机器学习入门(一)
一.简介 首先介绍MNIST 数据集.如图1-1 所示, MNIST 数据集主要由一些手写数字的图片和相应的标签组成,图片一共有10 类,分别对应从0-9 ,共10 个阿拉伯数字. 原始的MNIST ...
- 【TensorFlow官方文档】MNIST机器学习入门
MNIST是一个入门级的计算机视觉数据集,它包含各种手写数字图片:它也包含每一张图片对应的标签,告诉我们这个是数字几.比如,下面这四张图片的标签分别是5,0,4,1. 从一个很简单的数学模型开始:训练 ...
- TensorFlow 学习(3)——MNIST机器学习入门
通过对MNIST的学习,对TensorFlow和机器学习快速上手. MNIST:手写数字识别数据集 MNIST数据集 60000行的训练数据集 和 10000行测试集 每张图片是一个28*28的像素图 ...
随机推荐
- docker~windows版本的安装与使用
回到目录 在面向服务的框架里,docker扮演着十分重要的角色,他使你的部署更轻量,使运维更智能化,事实上微软自己的项目也已经用上了docker了,下面介绍一下在windows环境上使用docker的 ...
- 简单谈谈js中的MVC
MVC是什么? MVC是一种架构模式,它将应用抽象为3个部分:模型(数据).视图.控制器(分发器). 本文将用一个经典的例子todoList来展开(代码在最后). 一个事件发生的过程(通信单向流动): ...
- ASP.NET MVC Bundles 用法和说明(打包javascript和css)
本文主要介绍了ASP.NET MVC中的新功能Bundles,利用Bundles可以将javascript和css文件打包压缩,并且可以区分调试和非调试,在调试时不进行压缩,以原始方式显示出来,以方便 ...
- 有点难度的JS面试题
自己总结了一些JS面试题 希望能够帮助正在找工作的程序猿(●´∀`●) 1.js 实现一个函数对javascript中json 对象进行克隆 var oldObject ="sdf" ...
- GetConsoleTitle 函数--获取控制台窗口标题
GetConsoleTitle函数 来源:https://msdn.microsoft.com/en-us/library/windows/desktop/ms683174(v=vs.85).aspx ...
- (转)log4j(七)——log4j.xml简单配置样例说明
背景:在公司中警察需要做技术支持,查看日志,而查看日志首先要自己清楚日志是如何生成的,所以有必要知道日志的前世今生! 转载出处:http://www.cnblogs.com/godtrue/p/644 ...
- .NET CORE——Console中使用依赖注入
我们都知道,在 ASP.NET CORE 中通过依赖注入的方式来使用服务十分的简单,而在 Console 中,其实也只是稍微绕了个小弯子而已.不管是内置 DI 组件或者第三方的 DI 组件(如Auto ...
- 【Django】中间件
Middleware 这个地方把所有Request 拦截住,用我们自己的方式完成处理以后直接返回 Response.因此了解中间件的构成是非常必要的. Initializer: __init__(se ...
- ES6中的迭代器(Iterator)和生成器(Generator)
前面的话 用循环语句迭代数据时,必须要初始化一个变量来记录每一次迭代在数据集合中的位置,而在许多编程语言中,已经开始通过程序化的方式用迭代器对象返回迭代过程中集合的每一个元素 迭代器的使用可以极大地简 ...
- CSS随笔1(CSS常用样式)
样式 属性 大小 font-size(x-large ; xx-small ; 可用数值单位 : PX,PD) 样式 font-style(oblique 偏斜体 : italic 斜体 : norm ...