Hadoop之HDFS及NameNode单点故障解决方案
Hadoop之HDFS
版权声明:本文为yunshuxueyuan原创文章。
如需转载请标明出处: http://www.cnblogs.com/sxt-zkys/
QQ技术交流群:299142667
HDFS介绍
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统。是根据google发表的论文翻版的。
什么是分布式文件系统
分布式文件系统(Distributed File System)是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连。分布式文件系统的设计基于客户机/服务器模式。
[优点]
支持超大文件 超大文件在这里指的是几百M,几百GB,甚至几TB大小的文件。
检测和快速应对硬件故障在集群的环境中,硬件故障是常见的问题。因为有上千台服务器连接在一起,这样会导致高故障率。因此故障检测和自动恢复是hdfs文件系统的一个设计目标
流式数据访问应用程序能以流的形式访问数据集。主要的是数据的吞吐量,而不是访问速度。
简化的一致性模型 大部分hdfs操作文件时,需要一次写入,多次读取。在hdfs中,一个文件一旦经过创建、写入、关闭后,一般就不需要修改了。这样简单的一致性模型,有利于提高吞吐量。
[缺点]
低延迟数据访问如和用户进行交互的应用,需要数据在毫秒或秒的范围内得到响应。由于hadoop针对高数据吞吐量做了优化,牺牲了获取数据的延迟,所以对于低延迟来说,不适合用hadoop来做。
大量的小文件Hdfs支持超大的文件,是通过数据分布在数据节点,数据的元数据保存在名字节点上。名字节点的内存大小,决定了hdfs文件系统可保存的文件数量。虽然现在的系统内存都比较大,但大量的小文件还是会影响名字节点的性能。
多用户写入文件、修改文件Hdfs的文件只能有一次写入,不支持写入,也不支持修改。只有这样数据的吞吐量才能大。
不支持超强的事务没有像关系型数据库那样,对事务有强有力的支持。
[HDFS结构]
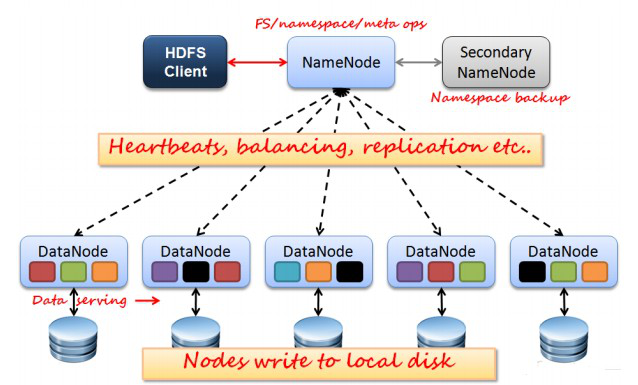
NameNode:分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。NameNode会将文件系统的Meta-data存储在内存中,这些信息主要包括了文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode的信息等。
SecondaryNameNode:合并fsimage和fsedits然后再发给namenode。
DataNode:是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data同时周期性地将所有存在的Block信息发送给NameNode。
Client:就是需要获取分布式文件系统文件的应用程序。
fsimage:元数据镜像文件(文件系统的目录树。)
edits:元数据的操作日志(针对文件系统做的修改操作记录)
NameNode、DataNode和Client之间通信方式:
client和namenode之间是通过rpc通信;
datanode和namenode之间是通过rpc通信;
client和datanode之间是通过简单的socket通信。
Client读取HDFS中数据的流程
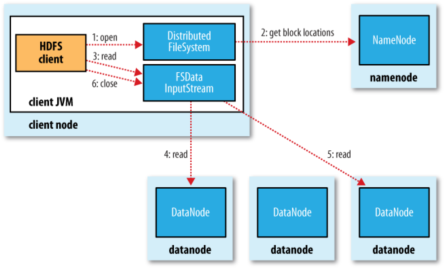
1. 客户端通过调用FileSystem对象的open()方法打开希望读取的文件。
2. DistributedFileSystem通过使用RPC来调用namenode,以确定文件起始块的位置。[注1]
3. Client对输入流调用read()方法。
4. 存储着文件起始块的natanoe地址的DFSInputStream[注2]随即链接距离最近的datanode。通过对数据流反复调用read()方法,可以将数据从datanode传输到Client。[注3]
5. 到达快的末端时,DFSInputStream会关闭与该datanode的连接,然后寻找下一个快递最佳datanode。
6. Client读取数据是按照卡开DFSInputStream与datanode新建连接的顺序读取的。它需要询问namenode来检索下一批所需要的datanode的位置。一旦完成读取,调用FSDataInputStream调用close()方法。
[注1]:对于每一个块,namenode返回存在该块副本的datanode地址。这些datanode根据他们于客户端的距离来排序,如果客户端本身就是一个datanode,并保存有响应数据块的一个副本时,该节点从本地datanode中读取数据。
[注2]:Di是tribute File System类返回一个FSDataInputStream对象给Client并读取数据。FSDataInputStream类转而封装DFSInputStream对象,该对象管理datanode和namenode的I/O。
[注3]:如果DFSInputStream在与datanode通信时遇到错误,它便会尝试从这个块的另外一个最临近datanode读取数据。它也会记住哪个故障的natanode,以保证以后不回反复读取该节点上后续的块。DFSInputStream也会通过校验和确认从datanode发来的数据是否完整。如果发现一个损坏的块,它就会在DFSinputStream视图从其他datanode读取一个块的副本之前通知namenode。
Client将数据写入HDFS流程
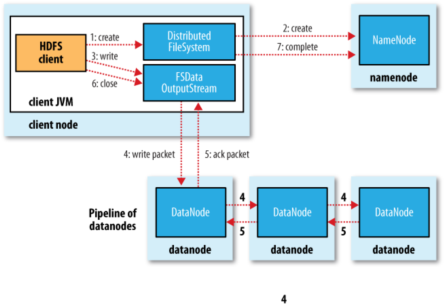
1. Client调用DistributedFileSystem对象的create()方法,创建一个文件输出流
2. DistributedFileSystem对namenode创建一个RPC调用,在文件系统的命名空间中创建一个新文件。
3. Namenode执行各种不同的检查以确保这个文件不存在,并且客户端有创建该文件的权限。如果这些检查均通过,namenode就会为创建新文件记录一条记录,否则,文件创建失败,向Client抛出IOException,DistributedFileSystem向Client返回一个FSDataOutputStream队形,Client可以开始写入数据。
4. DFSOutputStream将它分成一个个的数据包,并写入内部队列。DataStreamer处理数据队列,它的责任时根据datanode列表来要求namenode分配适合新块来存储数据备份。这一组datanode构成一个管线---我们假设副本数为3,管路中有3个节点,DataStreamer将数据包流式床书到管线中第一个datanode,该dananode存储数据包并将它发送到管线中的第二个datanode,同样地,第二个datanode存储该数据包并且发送给管县中的第3个。
5. DFSOutputStream也维护着一个内部数据包队列来等待datanode的收到确认回执(ack queue)。当收到管道中所有datanode确认信息后,该数据包才会从确认队列删除。[注1]
6. Client完成数据的写入后,回对数据流调用close()方法
7. 将剩余所有的数据包写入datanode管线中,并且在练习namenode且发送文件写入完成信号之前。
[注1]:如果在数据写入期间,datanode发生故障,则:1.关闭管线,确认把队列中的任何数据包添加回数据队列的最前端,一去到故障节点下游的datanode不回漏包。2.为存储在另一个正常datanode的当前数据块指定一个新的标志,并将给标志传给namenode,以便故障datanode在恢复后可以删除存储的部分数据块。3.从管线中删除故障数据节点,并且把余下的数据块写入管线中的两个正常的datanode。namenode注意到副本量不足时,会在另一个节点上创建一个新的副本。
Hadoop中NameNode单点故障解决方案
Hadoop 1.0内核主要由两个分支组成:MapReduce和HDFS,这两个系统的设计缺陷是单点故障,即MR的JobTracker和HDFS的NameNode两个核心服务均存在单点问题,这里只讨论HDFS的NameNode单点故障的解决方案。
[问题]
HDFS仿照google GFS实现的分布式存储系统,由NameNode和DataNode两种服务组成,其中NameNode是存储了元数据信息(fsimage)和操作日志(edits),由于它是唯一的,其可用性直接决定了整个存储系统的可用性。因为客户端对HDFS的读、写操作之前都要访问name node服务器,客户端只有从name node获取元数据之后才能继续进行读、写。一旦NameNode出现故障,将影响整个存储系统的使用。
[解决方案]
Hadoop官方提供了一种quorum journal manager来实现高可用,在高可用配置下,edit log不再存放在名称节点,而是存放在一个共享存储的地方,这个共享存储由若干Journal Node组成,一般是3个节点(JN小集群), 每个JN专门用于存放来自NN的编辑日志,编辑日志由活跃状态的名称节点写入。
要有2个NN节点,二者之中只能有一个处于活跃状态(active),另一个是待命状态(standby),只有active节点才能对外提供读写HDFS服务,也只有active态的NN才能向JN写入编辑日志;standby的名称节点只负责从JN小集群中的JN节点拷贝数据到本地存放。另外,各个DATA NODE也要同时向两个NameNode节点报告状态(心跳信息、块信息)。
一主一从的2个NameNode节点同时和3个JN构成的组保持通信,活跃的NameNode节点负责往JN集群写入编辑日志,待命的NN节点负责观察JN组中的编辑日志,并且把日志拉取到待命节点(接管Secondary NameNode的工作)。再加上两节点各自的fsimage镜像文件,这样一来就能确保两个NN的元数据保持同步。一旦active不可用,standby继续对外提供服。架构分为手动模式和自动模式,其中手动模式是指由管理员通过命令进行主备切换,这通常在服务升级时有用,自动模式可降低运维成本,但存在潜在危险。这两种模式下的架构如下。
[手动模式]
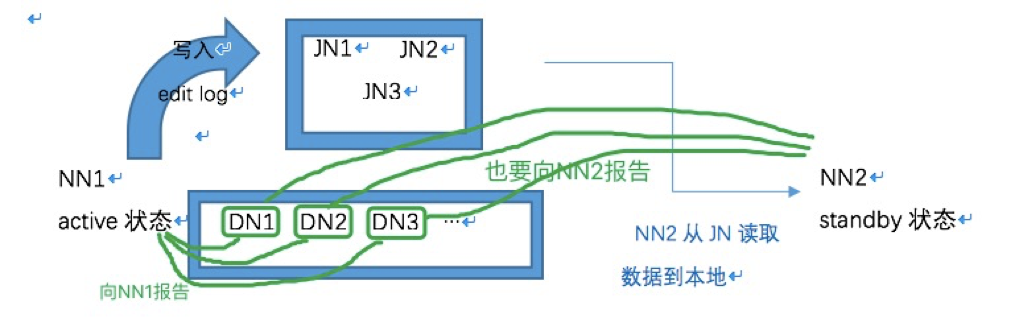
模拟流程:
1. 准备3台服务器分别用于运行JournalNode进程(也可以运行在date node服务器上),准备2台namenode服务器用于运行NameNode进程(两台配置 要一样),DataNode节点数量不限。
2. 分别启动3台JN服务器上的JournalNode进程,分别在date node服务器启动DataNode进程。
3. 需要同步2台name node之间的元数据。具体做法:从第一台NN拷贝元数据到放到另一台NN,然后启动第一台的NameNode进程,再到另一台名称节点上做standby引导。
4. 把第一台名节点的edit日志初始化到JN节点,以供standby节点到JN节点拉取数据。
5. 启动standby状态的NameNode节点,这样就能同步fsimage文件。
6. 模拟故障,手动把active状态的NN故障,转移到另一台NameNode。
[自动模式]
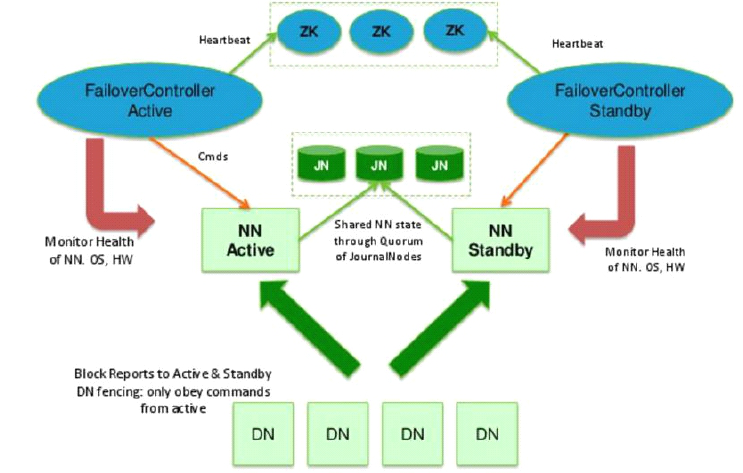
模拟流程:
在手动模式下引入了ZKFC(DFSZKFailoverController)和zookeeper集群
ZKFC主要负责: 健康监控、session管理、leader选举
zookeeper集群主要负责:服务同步
1-6步同手动模式
7. 准备3台主机安装zookeeper,3台主机形成一个小的zookeeper集群.
8. 启动ZK集群每个节点上的QuorumPeerMain进程
9. 登录其中一台NN, 在ZK中初始化HA状态
10. 模拟故障:停掉活跃的NameNode进程,提前配置的zookeeper会把standby节点自动变为active,继续提供服务。
脑裂
脑裂是指在主备切换时,由于切换不彻底或其他原因,导致客户端和Slave误以为出现两个active master,最终使得整个集群处于混乱状态。解决脑裂问题,通常采用隔离(Fencing)机制。
共享存储fencing:确保只有一个Master往共享存储中写数据,使用QJM实现fencing。
Qurom Journal Manager,基于Paxos(基于消息传递的一致性算法),Paxos算法是解决分布式环境中如何就某个值达成一致。
[原理]
a. 初始化后,Active把editlog日志写到JN上,每个editlog有一个编号,每次写editlog只要其中大多数JN返回成功(过半)即认定写成功。
b. Standby定期从JN读取一批editlog,并应用到内存中的FsImage中。
c. NameNode每次写Editlog都需要传递一个编号Epoch给JN,JN会对比Epoch,如果比自己保存的Epoch大或相同,则可以写,JN更新自己的Epoch到最新,否则拒绝操作。在切换时,Standby转换为Active时,会把Epoch+1,这样就防止即使之前的NameNode向JN写日志,也会失败。
客户端fencing:确保只有一个Master可以响应客户端的请求。
[原理]
在RPC层封装了一层,通过FailoverProxyProvider以重试的方式连接NN。通过若干次连接一个NN失败后尝试连接新的NN,对客户端的影响是重试的时候增加一定的延迟。客户端可以设置重试此时和时间
Slave fencing:确保只有一个Master可以向Slave下发命令。
[原理]
a. 每个NN改变状态的时候,向DN发送自己的状态和一个序列号。
b. DN在运行过程中维护此序列号,当failover时,新的NN在返回DN心跳时会返回自己的active状态和一个更大的序列号。DN接收到这个返回是认为该NN为新的active。
b. 如果这时原来的active(比如GC)恢复,返回给DN的心跳信息包含active状态和原来的序列号,这时DN就会拒绝这个NN的命令。
最后在此感谢尚学堂周老师在我学习过程中给予的帮助。
版权声明:本文为yunshuxueyuan原创文章。
如需转载请标明出处: http://www.cnblogs.com/sxt-zkys/
QQ技术交流群:299142667
Hadoop之HDFS及NameNode单点故障解决方案的更多相关文章
- hadoop中HDFS的NameNode原理
1. hadoop中HDFS的NameNode原理 1.1. 组成 包括HDFS(分布式文件系统),YARN(分布式资源调度系统),MapReduce(分布式计算系统),等等. 1.2. HDFS架构 ...
- hadoop中HDFS文件系统 nameNode出现的问题 nameNode无法打开
1,修改core-site.xml文件,先改成localhost,将所有进程关闭stop-all.sh(或者是先关闭所有进程,然后再修改文件),然后重启,在修改core-site.xml文件成ip地址 ...
- Hadoop(9)-HDFS的NameNode和SecondaryNameNode详解
1.NN和2NN工作机制 首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低.因此,元数据需要存放在内存中.但如果只存在内存中,一旦 ...
- Hadoop 2.0中单点故障解决方案总结
Hadoop 1.0内核主要由两个分支组成:MapReduce和HDFS,众所周知,这两个系统的设计缺陷是单点故障,即MR的JobTracker和HDFS的NameNode两个核心服务均存在单点问题, ...
- HDFS超租约异常总结(org.apache.hadoop.hdfs.server.namenode.LeaseExpiredException)
HDFS超租约异常总结(org.apache.hadoop.hdfs.server.namenode.LeaseExpiredException) 转载 2014年02月22日 14:40:58 96 ...
- org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /user/hive/warehouse/page_view. Name node is in safe mode
FAILED: Error in metadata: MetaException(message:Got exception: org.apache.hadoop.ipc.RemoteExceptio ...
- hadoop错误FATAL org.apache.hadoop.hdfs.server.namenode.NameNode Exception in namenode join java.io.IOException There appears to be a gap in the edit log
错误: FATAL org.apache.hadoop.hdfs.server.namenode.NameNode Exception in namenode join java.io.IOExcep ...
- hadoop 的HDFS 的 standby namenode无法启动事故处理
standby namenode无法启动 现象:线上使用的2.5.0-cdh5.3.2版本Hadoop,开启了了NameNode HA,HA采用QJM方式.hadoop的集群的namenode的sta ...
- 启动HDFS之后一直处于安全模式org.apache.hadoop.hdfs.server.namenode.SafeModeException: Log not rolled. Name node is in safe mode.
一.现象 三台机器 crxy99,crxy98,crxy97(crxy99是NameNode+DataNode,crxy98和crxy97是DataNode) 按正常命令启动HDFS之后,HDFS一直 ...
随机推荐
- 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比算法 ...
- 软件raid 5
软件raid 5的实现 RAID 5 是一种存储性能.数据安全和存储成本兼顾的存储解决方案. RAID 5可以理解为是RAID 0和RAID 1的折中方案.RAID 5可以为系统提供数据安全保障,但保 ...
- java之内部类
最近学了java,对内部类有一点拙见,现在分享一下 所谓内部类(nested classes),即:面向对象程序设计中,可以在一个类的内部定义另一个类. 内部类不是很好理解,但说白了其实也就是一个类中 ...
- 使用外部容器运行spring-boot项目:不使用spring-boot内置容器让spring-boot项目运行在外部tomcat容器中
前言:本项目基于maven构建 spring-boot项目可以快速构建web应用,其内置的tomcat容器也十分方便我们的测试运行: spring-boot项目需要部署在外部容器中的时候,spring ...
- 使用OTP动态口令(每分钟变一次)进行登录认证
GIT地址:https://github.com/suyin58/otp-demo 在对外网开放的后台管理系统中,使用静态口令进行身份验证可能会存在如下问题: (1) 为了便于记忆,用户多选择有特征作 ...
- eclipse汉化教程,新手神器
网盘下载地址:http://pan.baidu.com/s/1i5ed6ZF 下载汉化包 将汉化包里的两个文件存放到eclipse安装目录中的dropins文件夹中 重启eclipse 汉化成功
- JS中函数参数值传递和引用传递
也许大家对于函数的参数都不会太在意,简单来说,把函数外部的值复制给函数内部的参数,就和把值从一个变量复制到另一个变量一样.深入研究,你会发现其实没那么简单,这个传参是要分俩种情况(其实这是个错误的说法 ...
- 机器学习:保序回归(IsotonicRegression):一种可以使资源利用率最大化的算法
1.数学定义 保序回归是回归算法的一种,基本思想是:给定一个有限的实数集合,训练一个模型来最小化下列方程: 并且满足下列约束条件: 2.算法过程说明 从该序列的首元素往后观察,一旦出现乱序现象停止该轮 ...
- Netty方法误解ChannelHandlerContext.writeAndFlush(Object msg)
乍一看这个方法,以为什么消息都能输出,因为参数是Object类型的,但实际上,netty内部只支持两种类型,如图
- H5JS二维动画制作!two.js的基本操作class1
今天介绍一个网络上并不常用的插件two.js,刚开始学习的过程中,发现网上并没有合适的教程,在此发表基本操作 two.js是一款网页二维绘图软件,可以在指定区域内产生自设的各种动画效果 下载网址如下: ...