python网络数据采集(伴奏曲)
这里是前章,我们做一下预备。之前太多事情没能写博客~。。 (此博客只适合python3x,python2x请自行更改代码)
首先你要有bs4模块
windows下安装:pip3 install bs4,如果你电脑有python2x和python3x的话,在python3x中安装bs4请已管理员的身份运行cmd执行pip3 install bs4安装bs4。
linux下安装:sudo pip3 install bs4
还有urllib.request模块
windows下安装:pip3 install urllib.request,如果你电脑有python2x和python3x的话,在python3x中安装bs4请已管理员的身份运行cmd执行pip3 install urllib.request安装urllib.request模块
例子1:获取源码
from urllib.request import urlopen
from bs4 import BeautifulSoup
html=urlopen("http://wikipedia.org")
dgc=BeautifulSoup(html)
print(dgc)
输出图如下:
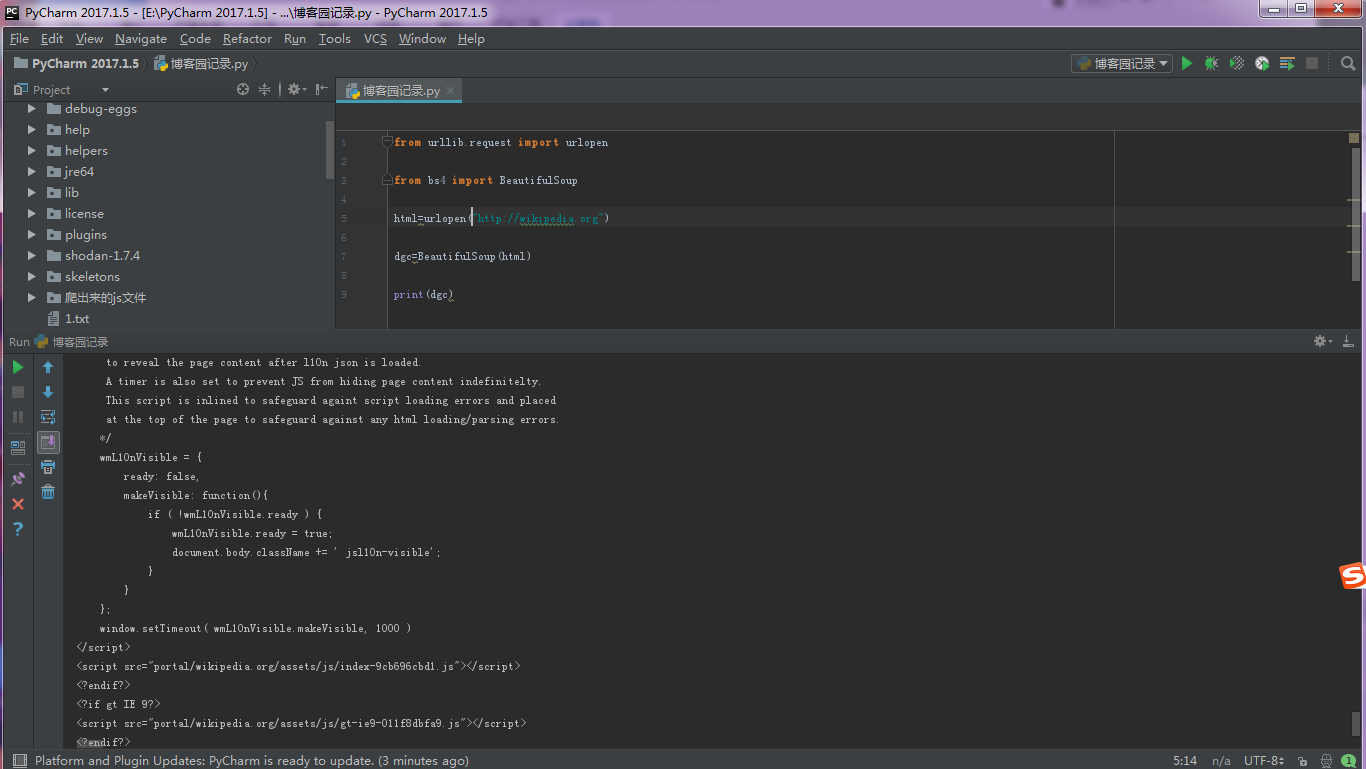
这里我忘记加自定义错误了,当然你也可以不加。保险起见还是加
例子二:匹配对应的标签
from urllib.request import urlopen from bs4 import BeautifulSoup
try:
html=urlopen("http://dlszx.dgjy.net/")
except EOFError as a:
print("404 ")
except:
print("404")
dgc=BeautifulSoup(html)
fbc=dgc.findAll("img",{"src":"uploadfile/201762105219962.jpg"})
print(fbc)
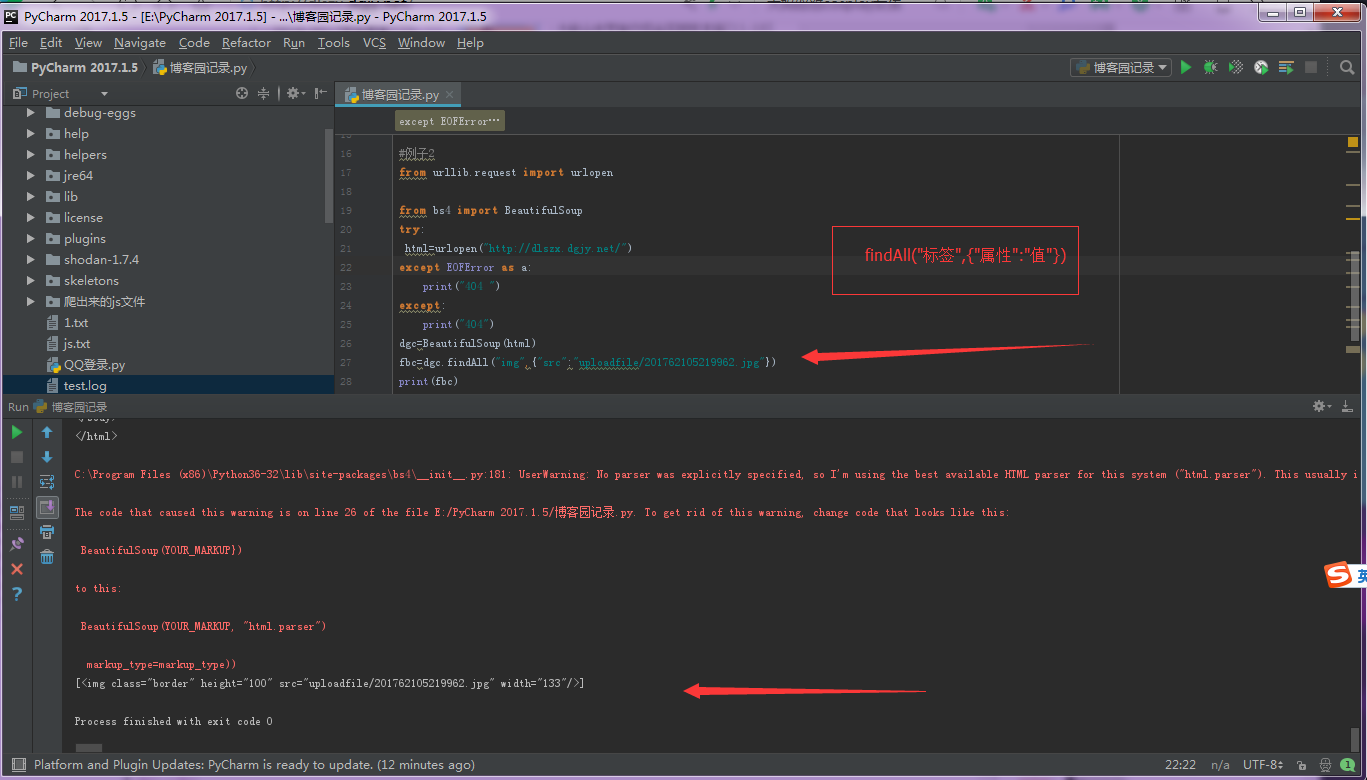
例子3:正则匹配所有对应的标签
不会正则的请去学习
from urllib.request import urlopen
import re
from bs4 import BeautifulSoup
try:
html=urlopen("http://dlszx.dgjy.net/")
except EOFError as a:
print("404 ")
except:
print("404")
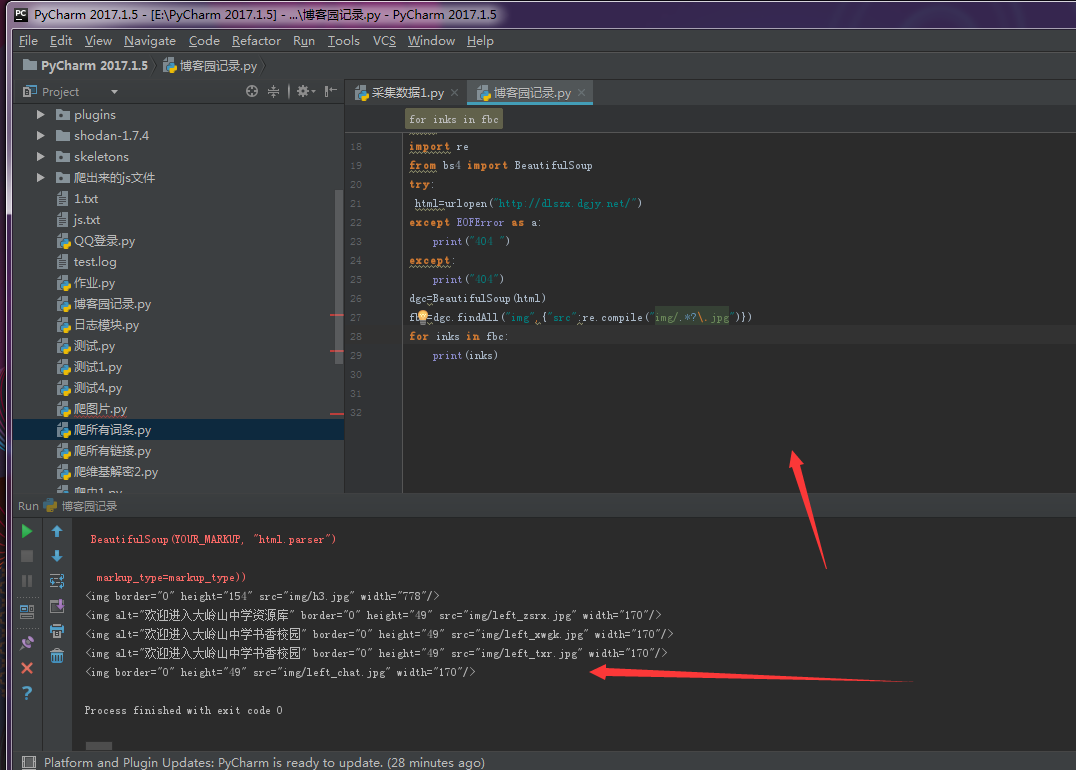
dgc=BeautifulSoup(html)
fbc=dgc.findAll("img",{"src":re.compile("img/.*?\.jpg")})
for inks in fbc:
print(inks)
注意事项!!!:不要拿findAll去搜索引擎匹配,乱的你想死
搜索引擎正则匹配要求很高:http:\/\/[a-zA-z].*?\[a-z]
例子4:
匹配网站所有的链接
from urllib.request import urlopen
import re
from bs4 import BeautifulSoup
try:
html=urlopen("http://wikipeda.org")
except EOFError as a:
print("EOFError")
except:
print("I dont EOFError")
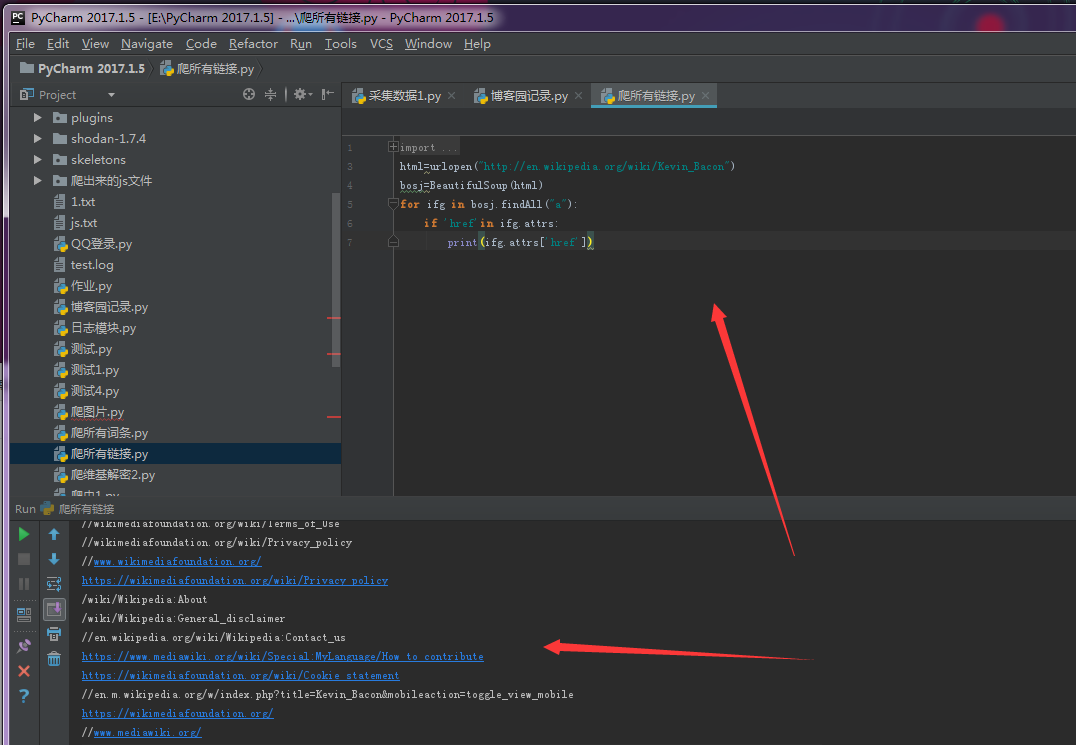
gfc=BeautifulSoup(html)
for inks in gfc.findAll("a")
if 'href' in inks.attrs:
print("inks.attrs["href"]")
现在的时间是
2017-8-13-13:38
python网络数据采集(伴奏曲)的更多相关文章
- 笔记之Python网络数据采集
笔记之Python网络数据采集 非原创即采集 一念清净, 烈焰成池, 一念觉醒, 方登彼岸 网络数据采集, 无非就是写一个自动化程序向网络服务器请求数据, 再对数据进行解析, 提取需要的信息 通常, ...
- Python网络数据采集7-单元测试与Selenium自动化测试
Python网络数据采集7-单元测试与Selenium自动化测试 单元测试 Python中使用内置库unittest可完成单元测试.只要继承unittest.TestCase类,就可以实现下面的功能. ...
- Python网络数据采集6-隐含输入字段
Python网络数据采集6-隐含输入字段 selenium的get_cookies可以轻松获取所有cookie. from pprint import pprint from selenium imp ...
- Python网络数据采集4-POST提交与Cookie的处理
Python网络数据采集4-POST提交与Cookie的处理 POST提交 之前访问页面都是用的get提交方式,有些网页需要登录才能访问,此时需要提交参数.虽然在一些网页,get方式也能提交参.比如h ...
- Python网络数据采集3-数据存到CSV以及MySql
Python网络数据采集3-数据存到CSV以及MySql 先热热身,下载某个页面的所有图片. import requests from bs4 import BeautifulSoup headers ...
- Python网络数据采集2-wikipedia
Python网络数据采集2-wikipedia 随机链接跳转 获取维基百科的词条超链接,并随机跳转.可能侧边栏和低栏会有其他链接.这不是我们想要的,所以定位到正文.正文在id为bodyContent的 ...
- Python网络数据采集1-Beautifulsoup的使用
Python网络数据采集1-Beautifulsoup的使用 来自此书: [美]Ryan Mitchell <Python网络数据采集>,例子是照搬的,觉得跟着敲一遍还是有作用的,所以记录 ...
- Python网络数据采集PDF
Python网络数据采集(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/16c4GjoAL_uKzdGPjG47S4Q 提取码:febb 复制这段内容后打开百度网盘手 ...
- python网络数据采集的代码
python网络数据采集的代码 https://github.com/REMitchell/python-scraping
- [python] 网络数据采集 操作清单 BeautifulSoup、Selenium、Tesseract、CSV等
Python网络数据采集操作清单 BeautifulSoup.Selenium.Tesseract.CSV等 Python网络数据采集操作清单 BeautifulSoup.Selenium.Tesse ...
随机推荐
- 项目(1)----用户信息管理系统(4)---(struts开发)
项目开发---实现注册功能 接下就要用到Struts框架了,再用之前先配置好有关操作 1.在web.xml设置前端配置器 2.在src下新建struts.xml 3.写好首页jsp: 4.配置好str ...
- 小型Web页打包优化(下)
之前我们推送了一篇小型Web项目打包优化文章,(链接),我们使用了一段时间, 在这过程中我们也一直在思考, 怎么能把结构做的更好.于是我们改造了一版, 把可以改进的地方和可能会出现的问题, 在这一版中 ...
- springboot 入门八-自定义配置信息(编码、拦截器、静态资源等)
若想实际自定义相关配置,只需要继承WebMvcConfigurerAdapter.WebMvcConfigurerAdapter定义些空方法用来重写项目需要用到的WebMvcConfigure实现.具 ...
- JavaScript基础1——基本概念
关于JS的概念 JavaScript 是一种弱类型语言. JavaScript 是一种客户端脚本语言(脚本语言是一种轻量级的编程语言). JavaScript是基于对象的.(因为面向对象需要具有封装. ...
- The Movie db (TMDB)的API申请
在共享API TMDB中申请时,一只报错Application summary please elaborate on how you plan to use our API,我是用汉字描述的,开始以 ...
- 关于MAX()函数的一点思考
本文同时发表在https://github.com/zhangyachen/zhangyachen.github.io/issues/103 考虑如下表和sql: CREATE TABLE `ikno ...
- Chrome调试折腾记_(1)调试控制中心快捷键详解!!!
转载:http://blog.csdn.net/crper/article/details/48098625 大多浏览器的调试功能的启用快捷键都一致-按下F12;还是熟悉的味道; 或者直接 Ctrl ...
- Spring之DAO一
前面博客把bean.aop简单了解了一下,今天主要是了解Spring中DAO层,如果使用传统的JDBC时需要创建连接.打开.执行sql.关闭连接这一系列的步骤,Spring框架对JDBC进行了封装,我 ...
- css3 UI元素状态伪类选择器
选择器 说明 例子/备注 E:hover 当鼠标移到元素上元素所使用的样式 :hover{}或input:[type="text"]:hover{} E:active 当元素被激活 ...
- CSS3 自定义动画(animation)
除了在之前的文章中介绍过的 CSS3 的变形 (transformation) 和转换 (transition) 外,CSS3 还有一种自由度更大的自定义动画,开发者甚至可以使用变形(transfor ...