玩转Storage Table 的PartitionKey,RowKey设计
参阅的文章
l https://docs.microsoft.com/en-us/rest/api/storageservices/fileservices/designing-a-scalable-partitioning-strategy-for-azure-table-storage
l https://docs.microsoft.com/en-us/azure/storage/storage-table-design-guide
在设计之前你需要知道的
l 对Table Item进行排序时, 对于存储类型是String的字段,“2”大于“111”
l 对于Query中的查询条件,只支持“等于”,“不等于”,“大于”“大于等于”“小于”“小于等于”,相比于Sql来说,查询能力还是非常有限的
l 一个Partition Server 可以承载多个Partition,同一个Partition一定在同一个Server上
l 一个Partition 1秒可以处理500 Entity
l 可以考虑使用多个Partition以避免用同一个Partition导致Server的负载过大
l 一个EGT要小于100个Storage操作以及小于4M的内容
l 一条记录的大小要小于1M
l 一个EGT只记做一次操作的花费,并且可以保证操作的一致性,如果有一些操作不能完成,整个EGT会被回滚
l Unique Value的PartitionKey如果增序或降序排列的话被称为Range Partition,可以很好的提高性能
l PartitionKey和RowKey会被加上索引
l 一个搜索如果如果不指定PartitionKey,他就会搜索所有Partition,效率会很差
| 除了每一条记录大小要小于1M以外,每个Column的大小也有限制,例如类型为string的Column最大不能超过64K
Storage Table 设计模式
1. 同PartitionKey多RowKey模式
适用场景:需要对同一个Entity中的多个字段进行查询,比如分别就ID和邮箱来查询员工信息

2. 多PartitionKey,多RowKey模式
适用场景:需要对同一个Entity中的多个字段进行查询,和上面不同的是可以就多个Partition进行负载分流

3. 数据同步模式
适用场景:同一个Entity存在于不同的Partition,或者不同的Table,或者不同的数据源(比如Blob里, File System等等),他们之间的数据要保持同步的话,可以借助Storage Queue进行管理
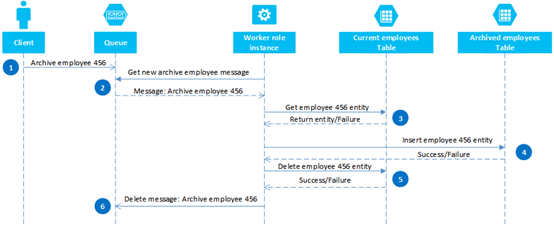
4. 索引模式
适用场景 :希望根据除PartitionKey和RowKey的其他属性进行查找,又不希望存储过多的重复数据,可以建立额外的Entity,专门映射这种关联关系。比如希望查找所有LastName相同的员工信息

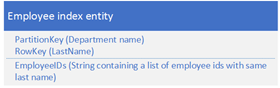
5. 合并数据模式
适用场景:区别于把所需要的数据分别存在两个entity,可以把相关数据融合成一个entity,以减少数据访问的次数,因为Storage Table支持多达256个字段
原先是这样

现在可以改成这样
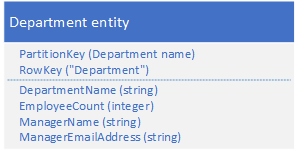
6. 组合键模式
适用场合 :只需要一个Query去获得相关的数据
以前是这样 :
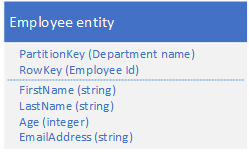

现在是这样:

7. 大规模删除模式
适用场景 :需要根据时间对历史数据进行删除
如何设计 :把时间信息作为Table Name,比如YYYYMMTable,如果要删除历史数据,可以直接删除对应的Table即可
8. 数据序列模式
适用场景:对按有限规则生成的RowKey,可以改变属性的设计,使其可以只使用一个Query获得所需数据
以前是这样:如果要统计一天的消息量,要Query 12次
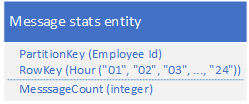
改成这样,只需要Query 1 次
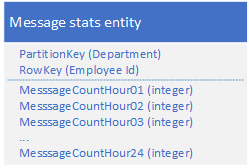
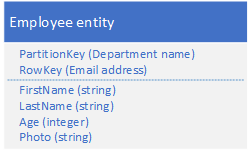
9. 大型Entity模式
适用场景:因为一条Table中的记录的限额是1M,对于比较大的字段,应该把相应内容存储在Blob中,Table中只存储Blob对应记录的地址
10. 分流模式
适用场景 :因为一个Partition的处理能力是每秒500个Entity,所以我们可以对Partition进行适当的切分,缓解访问压力

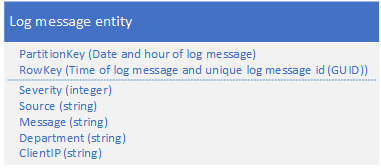
11. 日志存储模式
适用场景 :首先通过PartitionKey进行粗粒度时间分流,缓解存取压力,继而以查询条件开头来设计RowKey,有助于后续查询
玩转Storage Table 的PartitionKey,RowKey设计的更多相关文章
- Writing DynamicTableEntity to Azure Storage Table
There are ample of samples available to show how to insert an object/entity to Azure Storage Table. ...
- Hbase rowkey设计+布隆过滤器+STORE FILE & HFILE结构
Rowkey设计 Rowkey设计原则 Rowkey设计应遵循以下原则: 1.Rowkey的唯一原则 必须在设计上保证其唯一性.由于在HBase中数据存储是Key-Value形式,若HBase中同一表 ...
- HBase之六:HBase的RowKey设计
数据模型 我们可以将一个表想象成一个大的映射关系,通过行健.行健+时间戳或行键+列(列族:列修饰符),就可以定位特定数据,Hbase是稀疏存储数据的,因此某些列可以是空白的, Row Key Time ...
- Hbase rowkey设计一
转自 http://blog.csdn.net/lifuxiangcaohui/article/details/40621067 hbase所谓的三维有序存储的三维是指:rowkey(行主键),col ...
- HBase的rowkey设计(含实例)
转自:http://www.aboutyun.com/thread-7119-1-1.html 对于任何系统的数据设计,我们都想提高性能,达到资源最大化利用,那么对于hbase我们产生如下问题: 1. ...
- Hbase Rowkey设计
转自:http://www.bcmeng.com/hbase-rowkey/ 建立Schema Hbase 模式建立或更新可以通过 Hbase shell 工具或者使用Hbase Java API 中 ...
- HBase总结(十八)Hbase rowkey设计一
hbase所谓的三维有序存储的三维是指:rowkey(行主键),column key(columnFamily+qualifier),timestamp(时间戳)三部分组成的三维有序存储. 1.row ...
- hbase实践之rowkey设计
rowkey设计的重要性 rowkeys是HBase表设计中唯一重要的一点. rowkey设计要求 唯一性 存储特性 按照字典顺序排序存储 查询特性 由于其存储特性导致查询特性: 查询单个记录: 查定 ...
- hbase 利用rowkey设计进行多条件查询
摘要 本文主要内容是通过合理Hbase 行键(rowkey)设计实现快速的多条件查询,所采用的方法将所有要用于查询中的列经过一些处理后存储在rowkey中,查询时通过rowkey进行查询,提高rowk ...
随机推荐
- 一个web应用的诞生(11)--在探首页
就要面对本章的一个难点了,说是难点可能仅仅对于我来说,毕竟我是一个js渣,既然首页打算使用动态加载的形式,那么与后台交互的方式就要进行选择,目前比较流行的为RESTful的形式,关于RESTful的文 ...
- java多线程基本概述(五)——线程通信
线程之间的通信可以通过共享内存变量的方式进行相互通信,也可以使用api提供的wait(),notify()实现线程之间的通信.wait()方法是Object类的方法,改方法用来将当前的线程置入&quo ...
- canvas画图
这个元素负责在页面中设定一个区域,然后就可以通过JS动态的在这个区域中绘制图形. <canvas>由几组API构成. <canvas>还建议一个名为WebGL的3D上下文 (1 ...
- avalon2对比avalon1 新增的功能汇总
avalon2.0 与1.4,1.5相比, 2.0是移除了ms-repeat, ms-each, ms-with, ms-include, ms-include-src,ms-data, ms-sca ...
- SpringMVC4+MyBatis+SQL Server2014 基于SqlSession实现读写分离(也可以实现主从分离)
前言 上篇文章我觉的使用拦截器虽然方便快捷,但是在使用读串还是写串上你无法控制,我更希望我们像jdbc那样可以手动控制我使用读写串,那么这篇则在sqlsession的基础上实现读写分离, 这种方式则需 ...
- PHP 学习笔记(3)
<?phpif (isset($_POST['action']) && $_POST['action'] == 'submitted') { echo '<pre&g ...
- DOS(Disk Operation System:磁盘操作系统)常见命令
学习Java语言的第一节课总是练习DOS命令,用记事本敲出自己的第一个Java语言的HelloWorld程序案例,在此特意总结一下基本的DOS命令以作记录和分享. Windows+R快捷键---> ...
- 图论算法-Dijkstra
原理 Dijkstra是一个神奇的最短路径算法,它的优点在于它可以稳定的时间内求出一张图从某点到另一点的距离.它的工作原理非常简单,思路类似于广搜.在搜索前,将每个点的颜色设为白色,第一次将源点Ins ...
- 分针网—每日分享: 怎么轻松学习JavaScript
js给初学者的印象总是那么的"杂而乱",相信很多初学者都在找轻松学习js的途径. 我试着总结自己学习多年js的经验,希望能给后来的学习者探索出一条"轻松学习js之路& ...
- 分针网—IT教育:调皮的JavaScript
JavaScript是一门有趣的语言,不仅有趣而且调皮,不同的内核的浏览器在解析的时候表现会有些差异,今天主要是抛砖引玉,和大家一起讨论一些在实际开发中比较常见但同时可能并没有过于在意的JavaScr ...