HIVE---基于Hadoop的数据仓库工具讲解
Hadoop:
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用来开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
Hadoop框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,MapReduce则为海量的数据提供了计算。
Hadoop体系结构:
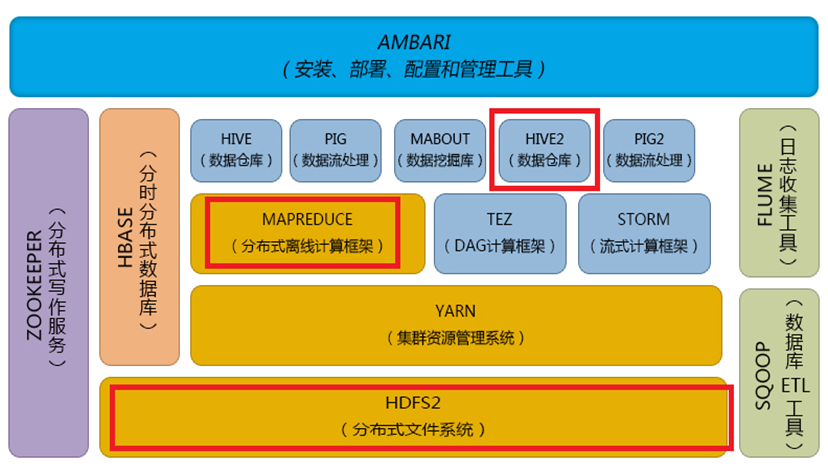
hive:
一、什么是hive
Hive是部署在hadoop集群上的数据仓库工具。
数据库和数据仓库的区别:
数据库(如常用关系型数据库)可以支持实时增删改查。
数据仓库不仅仅是为了存放数据,它可以存放海量数据,而且可以查询、分析和计算存储在Hadoop 中的大规模数据。但他有一个弱点,他不能进行实时的更新、删除等操作。也就是一次写入多次读取。
Hive 也定义了简单的类 SQL 查询语言,称为 QL ,它允许熟悉 SQL 的用户查询数据。现在hive2.0也支持更新、索引和事务,几乎SQL的其它特征都能支持。
Hive支持SQL92大部分功能,我们暂时可以把 hive理解成一个关系型数据库,语法和MySQL是几乎是一样的。
Hive是Hadoop 上的数据仓库基础构架之一,是SQL解析引擎,它可以将SQL转换成MapReduce任务,然后在Hadoop执行。
二、hive的部署与安装
Hive只在一个节点上安装即可
1.上传tar包
apache-hive-1.2.1-bin.tar.gz
2.解压
tar -zxvf hive-0.9.0.tar.gz -C /cloud/
3.配置mysql metastore 元数据库(切换到root用户)
配置HIVE_HOME环境变量
rpm -qa | grep mysql
rpm -e mysql-libs-5.1.66-2.el6_3.i686 --nodeps
rpm -ivh MySQL-server-5.1.73-1.glibc23.i386.rpm
rpm -ivh MySQL-client-5.1.73-1.glibc23.i386.rpm
修改mysql的密码
/usr/bin/mysql_secure_installation
(注意:删除匿名用户,允许用户远程连接)
登陆mysql
mysql -u root -p
4.配置hive
cp hive-default.xml.template hive-site.xml
修改hive-site.xml(删除所有内容,只留一个<property></property>)
添加如下内容:
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://xcloud36:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123</value>
<description>password to use against metastore database</description>
</property>
5.安装hive和mysq完成后,将mysql的连接jar包拷贝到$HIVE_HOME/lib目录下
如果出现没有权限的问题,在mysql授权(在安装mysql的机器上执行)
mysql -uroot -p
#(执行下面的语句 *.*:所有库下的所有表 %:任何IP地址或主机都可以连接)
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123' WITH GRANT OPTION;
FLUSH PRIVILEGES;
6.启动hive
进入hive的安装的home目录下的bin目录
[Neo@iZ25at60yr9Z bin]$ pwd
/home/Neo/apache-hive-1.2.1-bin/bin
执行hive脚本
[Neo@iZ25at60yr9Z bin]$ ./hive
Cannot find hadoop installation: $HADOOP_HOME or $HADOOP_PREFIX must be set or hadoop must be in the path
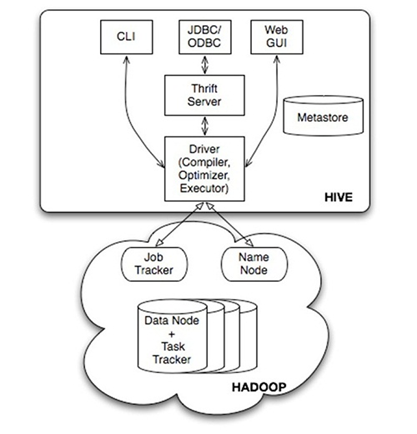
三、Hive的系统架构
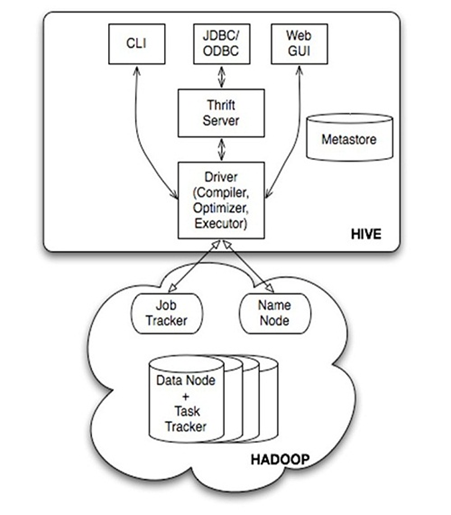
• 用户接口,包括 CLI(Shell命令行),JDBC/ODBC,WebUI
• MetaStore元数据库,通常是存储在关系数据库如 mysql, derby 中
• Driver 包含解释器、编译器、优化器、执行器
• Hadoop:用 HDFS 进行存储,利用 MapReduce 进行计算
Hive的表和数据库,对应的其实是HDFS( Hadoop分布式文件系统)的目录/文件,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在MapReduce Job里使用这些数据。
四、hive的元数据库以及数据存储方式
Hive的MetaStore,集中存储元数据的一个库,可以叫它元数据库。
元数据库保存的是不是我们要计算的数据?不是,元数据库中并没有保存我们要计算的数据,我们要计算的数据是存放在HDFS(分布式文件系统)里。
Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等表的描述信息。真正要处理的数据在HDFS里。
元数据通常是存储在关系数据库如 mysql, derby 中。
Metastore默认使用内嵌的derby数据库作为存储引擎
Derby引擎的缺点:不支持多链接,一次只能打开一个会话
使用MySql作为外置存储引擎,支持多用户同时访问,所以一般将MySQL作为Hive的MetaStore。
Hive 的数据存储在 HDFS 中,大部分SQL转换成 MapReduce 任务来完成。(全表扫描,比如 select * from table 不会就生成 MapRedcue 任务)
hive> create table test(id int,name string) row format delimited fields terminated by '\t'; hive> load data local inpath ‘/home/hadoop/test/test.txt’ into table test;
五、hive 数据类型
Hive数据类型分为基础数据类型和复杂数据类型。
基础数据类型包括:
数字 TINYINT,SMALLINT,INT/INTEGER,BIGINT,FLOAT,DOUBLE
字符串:
STRING,CHAR,VARCHAR
日期/时间类型
TIMESTAMP,DATE,INTERVAL (没有datetime)
其他类型
BOOLEAN
复杂类型包括 ARRAY,MAP,STRUCT,UNION,这些复杂类型是由基础类型组成的。
arrays: ARRAY<data_type>
maps: MAP<primitive_type, data_type>
structs: STRUCT<col_name : data_type [COMMENT col_comment],...>
union: UNIONTYPE<data_type, data_type,...>
六、hive与依赖环境的交互
与linux交互:
hive> !pwd; #查看路径
hive> !ls; #查看有哪些文件
与hdfs交互:
hive> dfs -ls / ; #查看hdfs下目录
hive> dfs -mkdir /haha; #hdfs下创建目录haha
七、hive表的基本操作
Hive的数据模型-表的分类:
Table 内部表
External Table 外部表
Partition 分区表
Bucket Table 桶表
Hive的数据模型-内部表
与数据库中的 Table 在概念上是类似,每一个 Table 在 Hive 中都有一个相应的目录存储数据。例如,一个表 test,它在 HDFS 中的路径为:/warehouse/test。
warehouse是在 hive-site.xml 中由${hive.metastore.warehouse.dir} 指定的数据仓库目录。
所有的 Table 数据(不包括 External Table)都保存在这个目录中。删除表时,元数据与数据都会被删除(对应目录和文件都会被删除)
创建数据文件inner_table.dat
创建表
hive>create table inner_table (id int,key string);
加载数据
hive>load data local inpath '/var/lib/hadoop-hdfs/test/inner_table.dat' into table inner_table;
查看数据
select * from inner_table
select count(*) from inner_table (也可以排序)
删除表
drop table inner_table
Hive的数据模型- External Table 外部表
指向已经在 HDFS 中存在的数据,可以创建 partition
它和内部表 在元数据的组织上是相同的,而实际数据的存储则有较大的差异。
内部表的创建过程和数据加载过程,实际数据会被移动到数据仓库目录中;之后对数据对访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除。
外部表 只有一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中,只是与外部数据建立一个链接。当删除一个 外部表 时,仅删除该链接。
创建数据文件
/data/student/text.txt
创建外部表:
create external table ext_student(id int,
name string) row format delimited fields terminated by '\t' location '/data/student';
加载数据
load data inpath '/home/external_table1.dat' into table ext_student;
查看数据
select * from ext_student;
select count(*) from ext_student;
删除表
drop table ext_student;
Hive的数据模型-分区表
创建分区是为了提高查询效率,在数据量非常大的时候一定要优先考虑分区,
partition 分区对应于数据库的 partition 列的密集索引
在 Hive 中,表中的一个 partition 分区对应于表下的一个目录,所有的 partition 数据都存储在对应的目录中
例如:test表中包含 date 和 city 两个 partition,
则对应于date=20130201, city = bj 的 HDFS 子目录为:
/user/hive/warehouse/test/date=20130201/city=beijing
对应于date=20130202, city=sh 的HDFS 子目录为:
/user/hive /warehouse/test/date=20130202/city=shanghai
创建数据文件
beauty_ch.txt beauty_uk.txt beauty_us.txt
创建外部分区表:
create external table beauties(id bigint,name string,age double) partitioned by (nation string) row format delimited fields terminated by '\t' location '/data/beauty';
加载数据到分区
load data local inpath
'/var/lib/hadoop-hdfs/test/beauty_ch.txt' into table beauties partition (nation='China');
修改表分区
alter table beauties add partition (nation='UK') location '/data/beauty/nation=UK';
• 查看数据
select * from partition_table
select count(*) from partition_table
• 删除表
drop table partition_table
Hive的数据模型—桶表
桶表是对数据进行哈希取值,然后放到不同文件中存储。数据加载到桶表时,会对字段取hash值,然后与桶的数量取模。把数据放到对应的文件中。
创建表
create table bucket_t1(id string) clustered by(id) into 6 buckets;
------表里的数据根据ID分成了6桶
加载数据
create table t2(id string); load data local inpath '/var/lib/hadoophdfs/test/bucket_test' into table t2; insert overwrite table bucket_t1 select id from t2;
删除表时,元数据与数据都会被删除(对应目录和文件都会被删除)
drop table bucket_table;
桶表专门用于抽样查询,是很专业性的,不是日常用来存储数据的表,需要抽样查询时,才创建和使用桶表。
抽样查询:
select * from bucket_table tablesample(bucket 1 out of 4 on id);
八、Hive的JDBC/ODBC接口
用户可以像连接传统关系数据库一样使用JDBC或ODBC连接Hive
JDBC的具体连接过程
1.使用jdbc的方式连接Hive,首先做的事情就是需要启劢hive的Thrift Server,否则连接hive的时候会报connection refused的错误。
启动命令如下:
hive --service hiveserver
2.新建java项目,然后将hive/lib下的所有jar包和hadoop的核心jar包hadoop-0.20.2-core.jar添加到项目的类路径上。Jar包版本要和hive版本一致。
HIVE---基于Hadoop的数据仓库工具讲解的更多相关文章
- Hive和SparkSQL: 基于 Hadoop 的数据仓库工具
Hive: 基于 Hadoop 的数据仓库工具 前言 Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的 SQL 查询功能,将类 SQL 语句转 ...
- Hive -- 基于Hadoop的数据仓库分析工具
Hive是一个基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库 ...
- 基于hadoop的数据仓库工具:Hive概述
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行.其优点是学习成本低,可以通过类 ...
- Hive和SparkSQL:基于 Hadoop 的数据仓库工具
Hive 前言 Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的 SQL 查询功能,将类 SQL 语句转换为 MapReduce 任务执行. ...
- 基于Hadoop的数据仓库Hive
Hive是基于Hadoop的数据仓库工具,可对存储在HDFS上的文件中的数据集进行数据整理.特殊查询和分析处理,提供了类似于SQL语言的查询语言–HiveQL,可通过HQL语句实现简单的MR统计,Hi ...
- 大数据之路week07--day05 (一个基于Hadoop的数据仓库建模工具之一 HIve)
什么是Hive? 我来一个短而精悍的总结(面试常问) 1:hive是基于hadoop的数据仓库建模工具之一(后面还有TEZ,Spark). 2:hive可以使用类sql方言,对存储在hdfs上的数据进 ...
- Hadoop整理五(基于Hadoop的数据仓库Hive)
数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合.它是单个数据存储,出于分析性报告和决策支持目的而创建. 为需要业务智能的企业,提供指导业务流程改进.监视时间.成本.质量以及控 ...
- 数据仓库工具:Hive
转载请标明出处: http://blog.csdn.net/zwto1/article/details/46430823: 本文出自:[明月的博客] 为什么要选择Hive 基于Hadoop的大数据的计 ...
- [转] X-RIME: 基于Hadoop的开源大规模社交网络分析工具
转自http://www.dataguru.cn/forum.php?mod=viewthread&tid=286174 随着互联网的快速发展,涌现出了一大批以Facebook,Twitter ...
随机推荐
- MySQL的简单使用-(一)
MySQL的简单使用 使用MySQL命令行工具 Windows 用户使用: MySQL Client, 输入密码 Linux: mysql -u用户名 -p密码 mysql -uroot -p 显示数 ...
- zbrush曲面增加厚度
把曲面增加厚度方便雕刻机雕刻. 可以使用zbrush中的边循环功能. 1.准备好需要增加厚度的曲面,把曲面的边缘调整好,尽量的变得平滑. 2.将模型导入到zbrush中,开启双面显示,以方便观察模型的 ...
- java基础学习——集合
-------|List: 有存储顺序, 可重复-----------|ArrayList: 数组实现, 查找快, 增删慢,由于是数组实现, 在增和删的时候会牵扯到数组增容, 以及拷贝元素. 所以慢. ...
- 汇编指令-位置无关码(BL)与绝对位置码(LDR)(2)
位置无关码,即该段代码无论放在内存的哪个地址,都能正确运行.究其原因,是因为代码里没有使用绝对地址,都是相对地址. 位置相关码,即它的地址与代码处于的位置相关,是绝对地址 BL :带链接分支跳转指令 ...
- C#后台调用浏览器打开下载连接地址的三种方法
一.从注册表中读取到本地计算机默认浏览器,然后调用下载. private void button1_Click(object sender, EventArgs e) { //从注册表 ...
- 【beta】阶段 第七次 Scrum Meeting
每日任务 1.本次会议为第七次 Meeting会议: 2.本次会议在下午14:45,课间休息时间在陆大楼召开,召开本次会议为10分钟. 一.今日站立式会议照片 二.每个人的工作 (有work item ...
- 微信小程序wx.navigateTo层叠5次限制,特殊情况的建议
小程序页面的实例使用栈的数据结构存储,栈内元素最多5个(换一种方式说,就是用户最多能点击5次返回),微信小程序能在栈中相对高层某个页面调用其他相对低层的页面实例的方法. 小程序三种页面跳转API 的区 ...
- 201521123098 《Java程序设计》 第4周学习总结
1. 本周学习总结 1.1 尝试使用思维导图总结有关继承的知识点. 1.2 使用常规方法总结其他上课内容. 1. 学习了继承的基本含义,用"class 子类名 extend 父类名" ...
- 201521123053 <<Java基本语法与类库>>第二周
1.本周学习总结 这是第二周学习了,还是感觉吃力,慢慢来吧 .知识总是一点一点进到脑子里,虽然头小,但总会进来不是! 知识储备: A.整形变量按照长度分为byte.short.int.long. ...
- 201521123045java课程设计---定时器
#课程设计--定时器(201521123045 郑子熙) 1.团队课程设计博客链接 http://www.cnblogs.com/chendajia/p/7065730.html 2.个人负责模块或任 ...