kafka学习笔记2:生产者
这次的笔记主要记录一下kafka的生产者的使用和一些重要的参数。
文中主要截图均来自kafka权威指南
主要涉及到两个类KafkaProducer和ProducerRecord.
总览
生产者的主要架构如下:
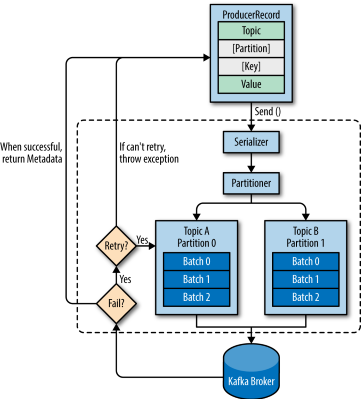
首先创建了一个ProducerRecord
进行序列化 kv变为ByteArray
进入Partitioner 如果之前指定了分区 那这一步什么都不会做
接着将Record放入要被发送到的同样的topic和分区的batch中
另一个单独的thread会进行发送操作
发送成功会返回RecordMetadata(包含topic 分区 偏移量)
失败的话会返回错误 producer会重试几次(retries配置)直到成功或者放弃返回错误
构造Kafka Producer
示例代码如下:
Properties properties = new Properties();
properties.put("bootstrap.servers", "192.168.56.101:9092");
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("metadata.fetch.timeout.ms", 5000);
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);
ProducerRecord<String, String> record = new ProducerRecord<String, String>("CustomerCountry",
"Precision Products", "France");
Future<RecordMetadata> f = producer.send(record);
返回的是一个Future,有以下处理方式:
- 不在乎异常 可以不处理
- 直接get拿到结果 同步的获取方式
另外send方法也支持传入回调的方式进行异步处理
bootstrap.servers
指定了要连接到的broker,可以用,分隔写入多个,连接broker cluster时不需要写入全部的broker地址,broker本身会同步其他broker的信息,但最少放两个以免写一个对应的broker挂了。
在实际使用中,可能会出现org.apache.kafka.common.errors.TimeoutException: Failed to update metadata after 60000 ms.这个错误,请求本身是发送成功的,检查zk topic也建立了,但就是获取不到metadata。
这是因为填入的broker服务器和kafka在zk上注册的host不一致导致的(在zk上可以通过get /brokers/ids/{id}查看),可以通过修改kafka的server.properties的advertised.host.name和advertised.port改正。
但是要注意hosts文件会影响,比如配置了自己ip到一个域名上导致失败,注意代码在运行时log打出的实际的值。
例如电脑上装了银联控件,结果把localhost映射到了一个奇怪的地址:

例子中已经改为了ip。
另外实验环境也迁移至了虚拟机上,上一节用bash on windows搭建好的环境不知道为什么无论怎么改都获取不到metadata
key.serialization
用来指定key的序列化器(下面会提到)
配置Producers
文档:http://kafka.apache.org/documentation.html#producerconfigs
因为用的是0.9.0.1,一些参数在最新版已经被弃用了,自己使用多注意下。
这些的默认配置在ProducerConfig的static块中定义:
static {
CONFIG = new ConfigDef().define(BOOTSTRAP_SERVERS_CONFIG, Type.LIST, Importance.HIGH, CommonClientConfigs.BOOSTRAP_SERVERS_DOC)
.define(BUFFER_MEMORY_CONFIG, Type.LONG, 32 * 1024 * 1024L, atLeast(0L), Importance.HIGH, BUFFER_MEMORY_DOC)
.define(RETRIES_CONFIG, Type.INT, 0, between(0, Integer.MAX_VALUE), Importance.HIGH, RETRIES_DOC)
.define(ACKS_CONFIG,
Type.STRING,
"1",
in("all", "-1", "0", "1"),
Importance.HIGH,
ACKS_DOC)
... ...
这里列举一下比较重要的参数:
ACKS
指定一次写成功需要多少个分区分片必须收到record
0
不会等待broker的返回 不会知道是否成功 高吞吐1
接受leader的 比0安全 但也会有还来不及复制leader就挂掉等导致失败的情况all
所有的复本都接收到消息并回应 最安全的模式 但相对的延迟就比较惨了
默认值为1
BUFFER.MEMORY
缓存等待发送的消息
如果超过了 会在抛错前等待max.block.ms秒
默认32M
COMPRESSION.TYPE
默认是none 不压缩
可以是snappy gzip lz4
snappy用较少的cpu完成还行的压缩 性能和网络带宽的权衡
gzip是使用更多的cpu和时间但是压缩更好 网络带宽是主要限制时使用
RETRIES
重试次数 默认是0
默认间隔100ms (通过retry.backoff.ms控制)
不是所有的错误都会重试(RetriableException)
不要在业务里做重试
BATCH.SIZE
多个record被发送到同一个分区的时候 producer会进行批处理
内存 默认16k
满了就发 但不意味着只有满了才会发(见下一个参数)
设太大不会导致他的延迟 只不过会用更多的内存
设太小就惨了 会导致过于频繁
LINGER.MS
在发送当前batch时等多久额外的信息
默认是0
producer会在batch满了或者这个时间到了发送 默认是0就意味着即时发送
大于0会导致延迟 但是增加吞吐量
CLIENT.ID
任何字符串 自己定义 用来打log和metrics
MAX.IN.FLIGHT.REQUESTS.PER.CONNECTION
可以设置可以发送多少个请求不等回应 也就是允许同时有多少条消息在空中飞
默认是5
设大了会增加内存使用 但是提高吞吐
设过大了会导致降低吞吐 因为batch变得低效了
设置成1可以保证消息即使是在重试下也有序(下面顺序保证中提到)
TIMEOUT.MS, REQUEST.TIMEOUT.MS, METADATA.FETCH.TIMEOUT.MS
第1和第3在0.11.0.1版本中被移除了。。可以参考旧文档
第2 从服务端等待多久回应(默认30s)
MAX.BLOCK.MS
在send()和显式通过partitionsFor()请求元数据中间等待的时间
在send buffer满了 以及metadata没返回阻塞
MAX.REQUEST.SIZE
一次请求的数据大小限制(限制最大的消息 以及批处理的大小)
默认1M 意味着可以同时发1000条1K的消息 或者发一条1M的消息
注意上一节broker里也有自己的配置 最好两个配置相匹配
RECEIVE.BUFFER.BYTES SEND.BUFFER.BYTES
前者默认32K
后者默认128K
TCP发送和接受的buffer 用于socket写入和读取数据
设置为-1是用OS默认的设置
不同数据中心间可以适当提高点这个值因为网络环境会更差
顺序保证
kafka保证在一个分区里消息的顺序
上述可以发现 如果设置了max.in.flights.request.pre.connection大于1(默认5)
并且retries大于0(默认0)那就完蛋了
可能写给同一个分区第一条消息写入失败 进入retry
但第二条写入成功
建议设置per.connection为1 但这会严重限制吞吐 只用于顺序很重要的场合
序列化
自定义可以自己实现org.apache.kafka.common.serialization.Serializer接口。
使用Apache Avro
优点:
- 语言中立的序列化格式
- 兼容性
用于写和读的schema必须兼容
反序列化器必须能够访问用于写数据的schema
保存每个record的schema开销很大(通常是两倍于record)
可以将schema保存在一个注册器中管理 只需要在消息中写入对应的id
Schema Registry - 有很多开源的选项 可以使用confluent platform
文档: http://docs.confluent.io/current/schema-registry/docs/index.html
这个可以单独记一个笔记,等实践后再做整理。
分区
如果key为null并且默认的分区器被使用 会用round-robin来平衡
有key 默认的分区器会hash key(自带的hash算法) 因为要保证同一个key总是写入同样的分区 他会使用所有的分区(不管是否可用) 写到不可用的会报错
如果分区数改变了 映射关系就会改变 同样的key在之后可能会到其他分区中
所以预先确定分区的数量在这种i情况下比较重要
kafka学习笔记2:生产者的更多相关文章
- 大数据 -- kafka学习笔记:知识点整理(部分转载)
一 为什么需要消息系统 1.解耦 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险.许多 ...
- kafka学习笔记(一)消息队列和kafka入门
概述 学习和使用kafka不知不觉已经将近5年了,觉得应该总结整理一下之前的知识更好,所以决定写一系列kafka学习笔记,在总结的基础上希望自己的知识更上一层楼.写的不对的地方请大家不吝指正,感激万分 ...
- Kafka 学习笔记之 Kafka0.11之console-producer/console-consumer
Kafka 学习笔记之 Kafka0.11之console-producer/console-consumer: 启动Zookeeper 启动Kafka0.11 创建一个新的Topic: ./kafk ...
- kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- [Big Data - Kafka] kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- KafKa——学习笔记
学习时间:2020年02月03日10:03:41 官网地址 http://kafka.apache.org/intro.html kafka:消息队列介绍: 近两年发展速度很快.从1.0.0版本发布就 ...
- Kafka学习笔记-如何保证高可用
一.术语 1.1 Broker Kafka 集群包含一个或多个服务器,服务器节点称为broker. broker存储topic的数据. 如果某topic有N个partition,集群有N个broker ...
- kafka学习笔记(三)kafka的使用技巧
概述 上一篇随笔主要介绍了kafka的基本使用包括集群参数,生产者基本使用,consumer基本使用,现在来介绍一下kafka的使用技巧. 分区机制 我们在使用 Apache Kafka 生产和消费消 ...
- Kafka学习笔记3--Kafka的生产者和消费者配置
下载解压 kafka 后,在 kafka/config 下有 3 个配置文件与主题及其生产.消费相关. server.properties--服务端配置 producer.properties--生产 ...
随机推荐
- Egg + Vue 服务端渲染工程化实现
在实现 egg + vue 服务端渲染工程化实现之前,我们先来看看前面两篇关于Webpack构建和Egg的文章: 在 Webpack工程化解决方案easywebpack 文章中我们提到了基于 Vue ...
- ionic2+Angular2:套接口明细步骤,以登录功能为例
1.在app.module.ts引用HttpModul,并在imports内引用.截图如下: 2.在src目录下新建http服务.命令行:ionic g provider HttpService ...
- Day3 Python基础学习——文件操作、函数
一.文件操作 1.对文件操作流程 打开文件,得到文件句柄并赋值给一个变量 通过文件句柄对文件进行操作 关闭文件 #打开文件,读写文件,关闭文件 http://www.cnblogs.com/linha ...
- Python selenium 文件自动下载 (自动下载器)
MyGithub:https://github.com/williamzxl 最新代码已经上传到Github,以下版本为stupid版本. 由于在下载过程中需要下载不同文件,所以可以把所有类型放在Va ...
- Python实战之int学习笔记及简单练习
['__abs__', '__add__', '__and__', '__bool__', '__ceil__', '__class__', '__delattr__', '__dir__', '__ ...
- Jquery仿京东分类导航层简单实现
<script src="/js/jquery-1.11.1.min.js" type="text/javascript"></script& ...
- 微服务架构中API网关的角色
[上海尚学堂的话]:本文主要讲述了Mashape的首席技术执行官Palladino对API网关的详细介绍,以及API网关在微服务中所起的作用,同时介绍了Mashape的一款开源API网关Kong. A ...
- 记一次vscode升级后,格式化Vue出现的问题
一.VSCode中使用vetur插件格式化vue文件时,stylus代码会自动加上大括号.冒号和分号 本来就是简写比较方便舒服,结果一个格式化回到十年前 解决方案: vscode 文件 ->首 ...
- 利用大白菜制作多系统启动U盘(win+ubuntu+PE+...)
网上提供的方法很多都过时了,不适用,要不就是讲的不清楚 我结合http://www.xuebuyuan.com/848003.html大神的方案,加以研究,整理出了此篇文章 先看下最终成果: 好了,感 ...
- Docker中搭建zookeeper集群
1.获取官方镜像 从dockerhub获取官方的zookeeper镜像: docker pull zookeeper 2.了解镜像内容 拉取完镜像后,通过 docker inspect zookeep ...