Java集合系列[2]----LinkedList源码分析
上篇我们分析了ArrayList的底层实现,知道了ArrayList底层是基于数组实现的,因此具有查找修改快而插入删除慢的特点。本篇介绍的LinkedList是List接口的另一种实现,它的底层是基于双向链表实现的,因此它具有插入删除快而查找修改慢的特点,此外,通过对双向链表的操作还可以实现队列和栈的功能。LinkedList的底层结构如下图所示。
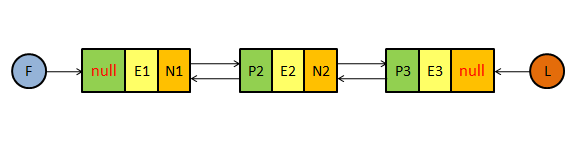
F表示头结点引用,L表示尾结点引用,链表的每个结点都有三个元素,分别是前继结点引用(P),结点元素的值(E),后继结点的引用(N)。结点由内部类Node表示,我们看看它的内部结构。
//结点内部类
private static class Node<E> {
E item; //元素
Node<E> next; //下一个节点
Node<E> prev; //上一个节点 Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
Node这个内部类其实很简单,只有三个成员变量和一个构造器,item表示结点的值,next为下一个结点的引用,prev为上一个结点的引用,通过构造器传入这三个值。接下来再看看LinkedList的成员变量和构造器。
//集合元素个数
transient int size = 0; //头结点引用
transient Node<E> first; //尾节点引用
transient Node<E> last; //无参构造器
public LinkedList() {} //传入外部集合的构造器
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
LinkedList持有头结点的引用和尾结点的引用,它有两个构造器,一个是无参构造器,一个是传入外部集合的构造器。与ArrayList不同的是LinkedList没有指定初始大小的构造器。看看它的增删改查方法。
//增(添加)
public boolean add(E e) {
//在链表尾部添加
linkLast(e);
return true;
} //增(插入)
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size) {
//在链表尾部添加
linkLast(element);
} else {
//在链表中部插入
linkBefore(element, node(index));
}
} //删(给定下标)
public E remove(int index) {
//检查下标是否合法
checkElementIndex(index);
return unlink(node(index));
} //删(给定元素)
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
//遍历链表
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
//找到了就删除
unlink(x);
return true;
}
}
}
return false;
} //改
public E set(int index, E element) {
//检查下标是否合法
checkElementIndex(index);
//获取指定下标的结点引用
Node<E> x = node(index);
//获取指定下标结点的值
E oldVal = x.item;
//将结点元素设置为新的值
x.item = element;
//返回之前的值
return oldVal;
} //查
public E get(int index) {
//检查下标是否合法
checkElementIndex(index);
//返回指定下标的结点的值
return node(index).item;
}
LinkedList的添加元素的方法主要是调用linkLast和linkBefore两个方法,linkLast方法是在链表后面链接一个元素,linkBefore方法是在链表中间插入一个元素。LinkedList的删除方法通过调用unlink方法将某个元素从链表中移除。下面我们看看链表的插入和删除操作的核心代码。
//链接到指定结点之前
void linkBefore(E e, Node<E> succ) {
//获取给定结点的上一个结点引用
final Node<E> pred = succ.prev;
//创建新结点, 新结点的上一个结点引用指向给定结点的上一个结点
//新结点的下一个结点的引用指向给定的结点
final Node<E> newNode = new Node<>(pred, e, succ);
//将给定结点的上一个结点引用指向新结点
succ.prev = newNode;
//如果给定结点的上一个结点为空, 表明给定结点为头结点
if (pred == null) {
//将头结点引用指向新结点
first = newNode;
} else {
//否则, 将给定结点的上一个结点的下一个结点引用指向新结点
pred.next = newNode;
}
//集合元素个数加一
size++;
//修改次数加一
modCount++;
} //卸载指定结点
E unlink(Node<E> x) {
//获取给定结点的元素
final E element = x.item;
//获取给定结点的下一个结点的引用
final Node<E> next = x.next;
//获取给定结点的上一个结点的引用
final Node<E> prev = x.prev; //如果给定结点的上一个结点为空, 说明给定结点为头结点
if (prev == null) {
//将头结点引用指向给定结点的下一个结点
first = next;
} else {
//将上一个结点的后继结点引用指向给定结点的后继结点
prev.next = next;
//将给定结点的上一个结点置空
x.prev = null;
} //如果给定结点的下一个结点为空, 说明给定结点为尾结点
if (next == null) {
//将尾结点引用指向给定结点的上一个结点
last = prev;
} else {
//将下一个结点的前继结点引用指向给定结点的前继结点
next.prev = prev;
x.next = null;
} //将给定结点的元素置空
x.item = null;
//集合元素个数减一
size--;
//修改次数加一
modCount++;
return element;
}

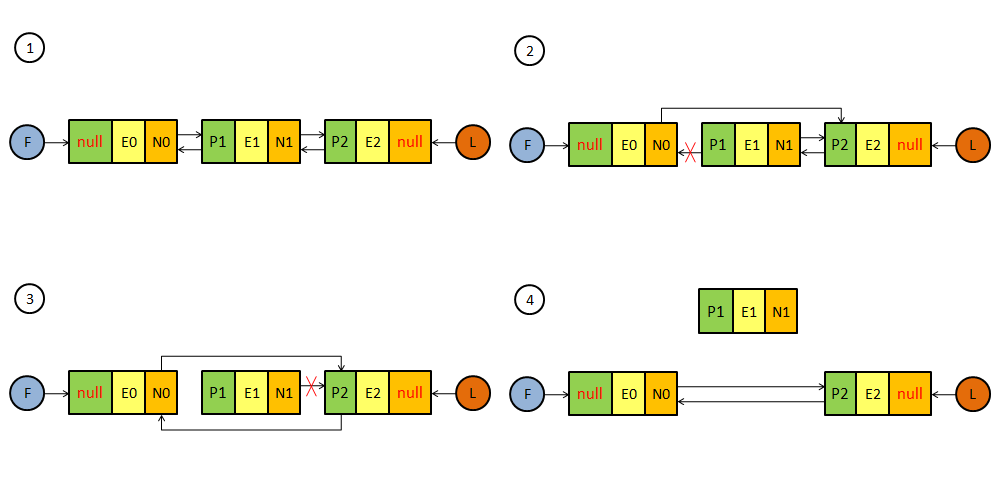
通过上面图示看到对链表的插入和删除操作的时间复杂度都是O(1),而对链表的查找和修改操作都需要遍历链表进行元素的定位,这两个操作都是调用的node(int index)方法定位元素,看看它是怎样通过下标来定位元素的。
//根据指定位置获取结点
Node<E> node(int index) {
//如果下标在链表前半部分, 就从头开始查起
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++) {
x = x.next;
}
return x;
} else {
//如果下标在链表后半部分, 就从尾开始查起
Node<E> x = last;
for (int i = size - 1; i > index; i--) {
x = x.prev;
}
return x;
}
}
//获取头结点
public E peek() {
final Node<E> f = first;
return (f == null) ? null : f.item;
} //获取头结点
public E element() {
return getFirst();
} //弹出头结点
public E poll() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
} //移除头结点
public E remove() {
return removeFirst();
} //在队列尾部添加结点
public boolean offer(E e) {
return add(e);
}
双向队列操作:
//在头部添加
public boolean offerFirst(E e) {
addFirst(e);
return true;
} //在尾部添加
public boolean offerLast(E e) {
addLast(e);
return true;
} //获取头结点
public E peekFirst() {
final Node<E> f = first;
return (f == null) ? null : f.item;
} //获取尾结点
public E peekLast() {
final Node<E> l = last;
return (l == null) ? null : l.item;
}
栈操作:
//入栈
public void push(E e) {
addFirst(e);
} //出栈
public E pop() {
return removeFirst();
}
Java集合系列[2]----LinkedList源码分析的更多相关文章
- java集合系列之LinkedList源码分析
java集合系列之LinkedList源码分析 LinkedList数据结构简介 LinkedList底层是通过双端双向链表实现的,其基本数据结构如下,每一个节点类为Node对象,每个Node节点包含 ...
- Java集合系列[4]----LinkedHashMap源码分析
这篇文章我们开始分析LinkedHashMap的源码,LinkedHashMap继承了HashMap,也就是说LinkedHashMap是在HashMap的基础上扩展而来的,因此在看LinkedHas ...
- java集合系列之ArrayList源码分析
java集合系列之ArrayList源码分析(基于jdk1.8) ArrayList简介 ArrayList时List接口的一个非常重要的实现子类,它的底层是通过动态数组实现的,因此它具备查询速度快, ...
- Java集合系列:-----------03ArrayList源码分析
上一章,我们学习了Collection的架构.这一章开始,我们对Collection的具体实现类进行讲解:首先,讲解List,而List中ArrayList又最为常用.因此,本章我们讲解ArrayLi ...
- Java集合系列[3]----HashMap源码分析
前面我们已经分析了ArrayList和LinkedList这两个集合,我们知道ArrayList是基于数组实现的,LinkedList是基于链表实现的.它们各自有自己的优劣势,例如ArrayList在 ...
- Java集合系列[1]----ArrayList源码分析
本篇分析ArrayList的源码,在分析之前先跟大家谈一谈数组.数组可能是我们最早接触到的数据结构之一,它是在内存中划分出一块连续的地址空间用来进行元素的存储,由于它直接操作内存,所以数组的性能要比集 ...
- java多线程系列(九)---ArrayBlockingQueue源码分析
java多线程系列(九)---ArrayBlockingQueue源码分析 目录 认识cpu.核心与线程 java多线程系列(一)之java多线程技能 java多线程系列(二)之对象变量的并发访问 j ...
- Java并发系列[2]----AbstractQueuedSynchronizer源码分析之独占模式
在上一篇<Java并发系列[1]----AbstractQueuedSynchronizer源码分析之概要分析>中我们介绍了AbstractQueuedSynchronizer基本的一些概 ...
- Java并发系列[3]----AbstractQueuedSynchronizer源码分析之共享模式
通过上一篇的分析,我们知道了独占模式获取锁有三种方式,分别是不响应线程中断获取,响应线程中断获取,设置超时时间获取.在共享模式下获取锁的方式也是这三种,而且基本上都是大同小异,我们搞清楚了一种就能很快 ...
随机推荐
- 十四、Spring Boot 日志记录 SLF4J
在开发中打印内容,使用 System.out.println() 和 Log4j 应当是人人皆知的方法了. 其实在开发中我们不建议使用 System.out 因为大量的使用 System.out 会增 ...
- Java filter中的chain
一.Filter Filter:用来拦截请求,处于客户端和被请求资源之间,是为了代码的复用性.Filter链,在web.xml中哪个先配置就先调用哪个 二.FilterChain(过滤链) 服务器会按 ...
- MQTT 设计原则
MQTT 设计原则 简单. 没有杂七杂八的花俏功能,作为一个基础组件构建实用的系统,易于实现. "发布/订阅"消息传递方式. 随时接入随时发布.接收消息,无需太多其他"事 ...
- Android系统拍照之后回显并且获取文件路径
/*调用拍照返回*/ case PHOTO_REQUEST_GALLERY: if (data != null) { Uri uri = data.getData(); String photopat ...
- Java思维导图之Class对象
Class对象相关知识导图: 导图源文件保存地址:https://github.com/wanghaoxi3000/xmind
- 解决vue.js修改数据无法触发视图
data:{checkValue:{}}that.checkValue[key] = [] 赋值无法实时改变变量:(数据其实最终被修改,但是并没有触发检测从而更新视图)原因:Vue 不能检测到对象属性 ...
- iOS Xcode及模拟器SDK下载
原文: Xcode及模拟器SDK下载 如果你嫌在 App Store 下载 Xcode 太慢,你也可以选择从网络上下载: Xcode下载(Beta版打的包是不能提交到App Store上的) 绝对官方 ...
- iOS知识点、面试题 之三
最近面试,发现这些题 还不错,与大家分享一下,分三文给大家: 当然Xcode新版本区别,以及iOS新特性 Xcode8 和iOS 10 在之前文章有发过,感兴趣的可以查阅: http://www.cn ...
- 框架原理第三讲,RTTCreate,运行时类型创建.(以MFC框架讲解)
框架原理第三讲,RTTCreate,运行时类型创建.(以MFC框架讲解) 通过昨天的讲解,我们已经理解了运行时类型识别是什么. 比如 CObject * pthis = (Cobject *)Cre ...
- bzoj 1570: [JSOI2008]Blue Mary的旅行
Description 在一段时间之后,网络公司终于有了一定的知名度,也开始收到一些订单,其中最大的一宗来自B市.Blue Mary决定亲自去签下这份订单.为了节省旅行经费,他的某个金融顾问建议只购买 ...