从ConcurrentHashMap的演进看Java多线程核心技术 Java进阶(六)
本文分析了HashMap的实现原理,以及resize可能引起死循环和Fast-fail等线程不安全行为。同时结合源码从数据结构,寻址方式,同步方式,计算size等角度分析了JDK 1.7和JDK 1.8中ConcurrentHashMap的实现原理。
原创文章,同步首发自作者个人博客,转载请在文章开头处以超链接注明出处。http://www.jasongj.com/java/concurrenthashmap/
线程不安全的HashMap
众所周知,HashMap是非线程安全的。而HashMap的线程不安全主要体现在resize时的死循环及使用迭代器时的fast-fail上。
注:本章的代码均基于JDK 1.7.0_67
HashMap工作原理
HashMap数据结构
常用的底层数据结构主要有数组和链表。数组存储区间连续,占用内存较多,寻址容易,插入和删除困难。链表存储区间离散,占用内存较少,寻址困难,插入和删除容易。
HashMap要实现的是哈希表的效果,尽量实现O(1)级别的增删改查。它的具体实现则是同时使用了数组和链表,可以认为最外层是一个数组,数组的每个元素是一个链表的表头。
HashMap寻址方式
对于新插入的数据或者待读取的数据,HashMap将Key的哈希值对数组长度取模,结果作为该Entry在数组中的index。在计算机中,取模的代价远高于位操作的代价,因此HashMap要求数组的长度必须为2的N次方。此时将Key的哈希值对2N-1进行与运算,其效果即与取模等效。HashMap并不要求用户在指定HashMap容量时必须传入一个2的N次方的整数,而是会通过Integer.highestOneBit算出比指定整数小的最大的2N值,其实现方法如下。
public static int highestOneBit(int i) {
i |= (i >> 1);
i |= (i >> 2);
i |= (i >> 4);
i |= (i >> 8);
i |= (i >> 16);
return i - (i >>> 1);
}
由于Key的哈希值的分布直接决定了所有数据在哈希表上的分布或者说决定了哈希冲突的可能性,因此为防止糟糕的Key的hashCode实现(例如低位都相同,只有高位不相同,与2^N-1取与后的结果都相同),JDK 1.7的HashMap通过如下方法使得最终的哈希值的二进制形式中的1尽量均匀分布从而尽可能减少哈希冲突。
int h = hashSeed;
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
resize死循环
transfer方法
当HashMap的size超过Capacity*loadFactor时,需要对HashMap进行扩容。具体方法是,创建一个新的,长度为原来Capacity两倍的数组,保证新的Capacity仍为2的N次方,从而保证上述寻址方式仍适用。同时需要通过如下transfer方法将原来的所有数据全部重新插入(rehash)到新的数组中。
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
该方法并不保证线程安全,而且在多线程并发调用时,可能出现死循环。其执行过程如下。从步骤2可见,转移时链表顺序反转。
- 遍历原数组中的元素
- 对链表上的每一个节点遍历:用next取得要转移那个元素的下一个,将e转移到新数组的头部,使用头插法插入节点
- 循环2,直到链表节点全部转移
- 循环1,直到所有元素全部转移
单线程rehash
单线程情况下,rehash无问题。下图演示了单线程条件下的rehash过程
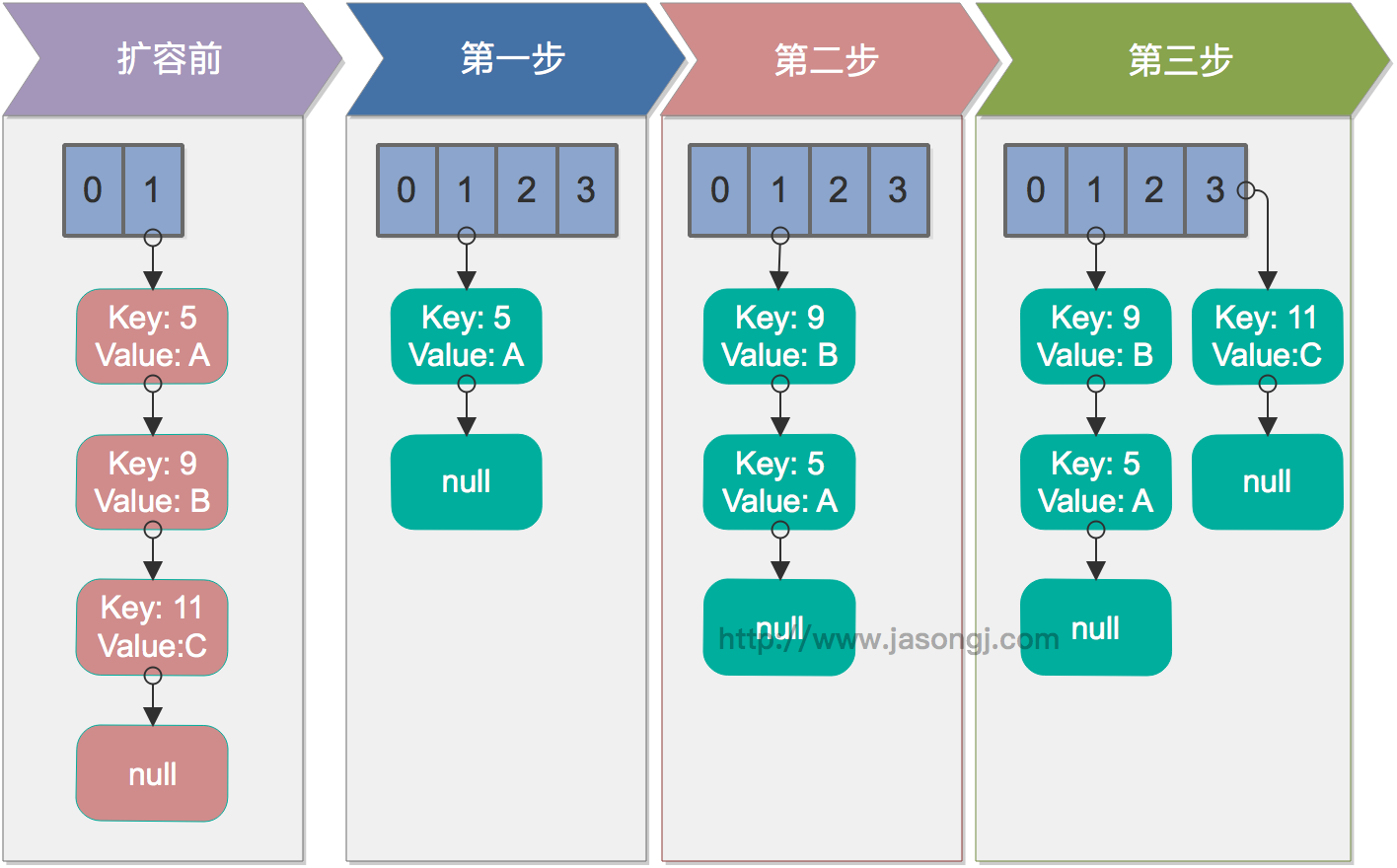
多线程并发下的rehash
这里假设有两个线程同时执行了put操作并引发了rehash,执行了transfer方法,并假设线程一进入transfer方法并执行完next = e.next后,因为线程调度所分配时间片用完而“暂停”,此时线程二完成了transfer方法的执行。此时状态如下。
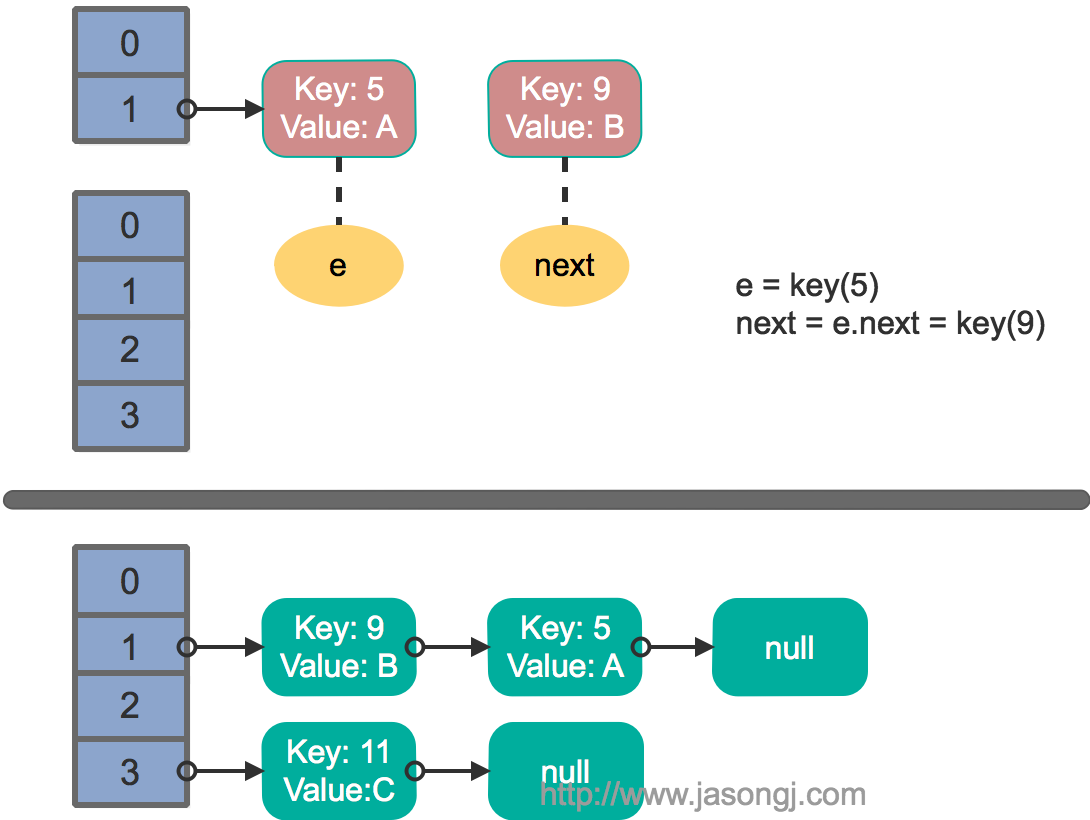
接着线程1被唤醒,继续执行第一轮循环的剩余部分
e.next = newTable[1] = null
newTable[1] = e = key(5)
e = next = key(9)
结果如下图所示
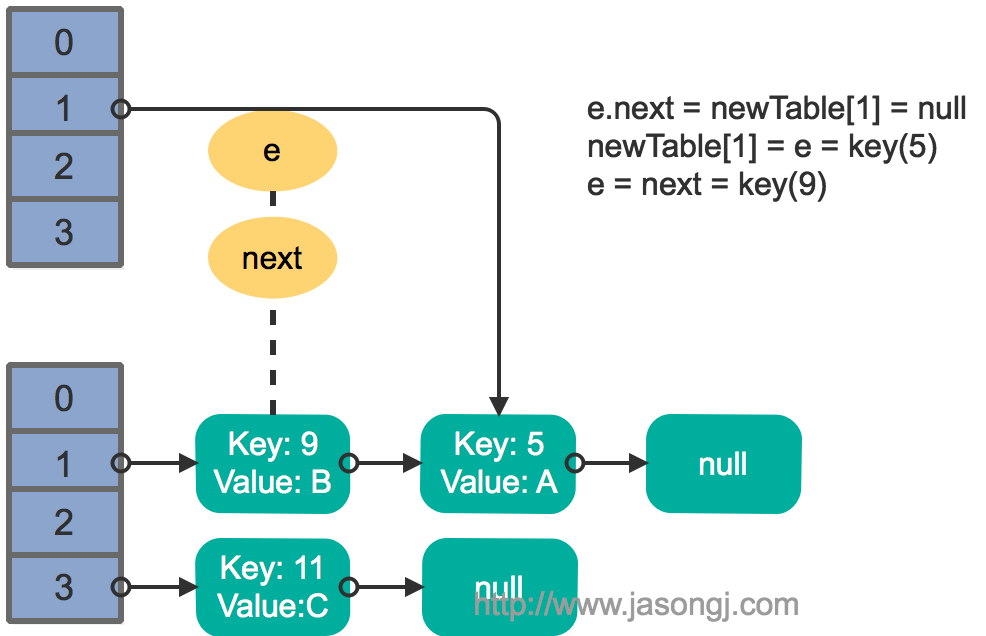
接着执行下一轮循环,结果状态图如下所示
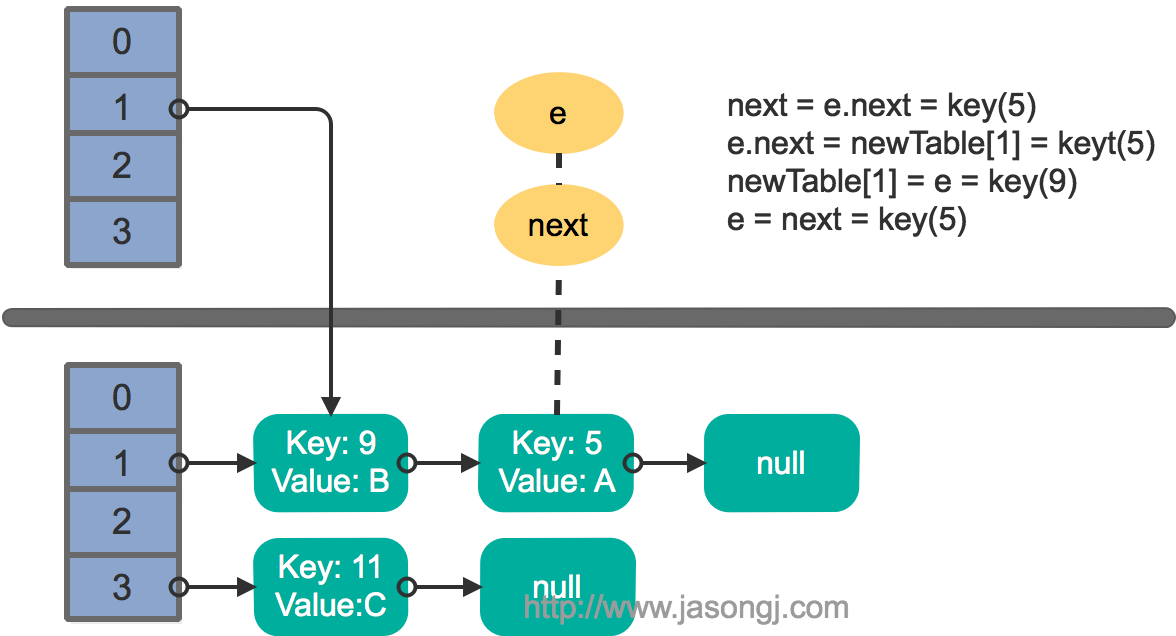
继续下一轮循环,结果状态图如下所示
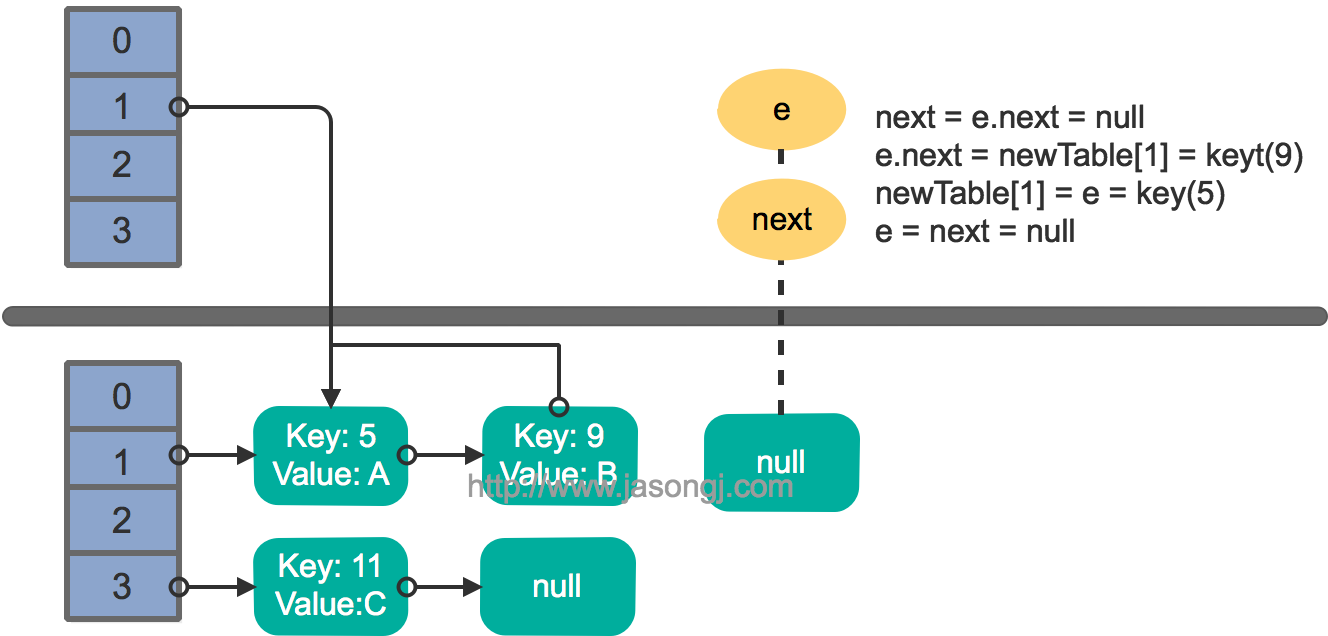
此时循环链表形成,并且key(11)无法加入到线程1的新数组。在下一次访问该链表时会出现死循环。
Fast-fail
产生原因
在使用迭代器的过程中如果HashMap被修改,那么ConcurrentModificationException将被抛出,也即Fast-fail策略。
当HashMap的iterator()方法被调用时,会构造并返回一个新的EntryIterator对象,并将EntryIterator的expectedModCount设置为HashMap的modCount(该变量记录了HashMap被修改的次数)。
HashIterator() {
expectedModCount = modCount;
if (size > 0) { // advance to first entry
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
}
在通过该Iterator的next方法访问下一个Entry时,它会先检查自己的expectedModCount与HashMap的modCount是否相等,如果不相等,说明HashMap被修改,直接抛出ConcurrentModificationException。该Iterator的remove方法也会做类似的检查。该异常的抛出意在提醒用户及早意识到线程安全问题。
线程安全解决方案
单线程条件下,为避免出现ConcurrentModificationException,需要保证只通过HashMap本身或者只通过Iterator去修改数据,不能在Iterator使用结束之前使用HashMap本身的方法修改数据。因为通过Iterator删除数据时,HashMap的modCount和Iterator的expectedModCount都会自增,不影响二者的相等性。如果是增加数据,只能通过HashMap本身的方法完成,此时如果要继续遍历数据,需要重新调用iterator()方法从而重新构造出一个新的Iterator,使得新Iterator的expectedModCount与更新后的HashMap的modCount相等。
多线程条件下,可使用Collections.synchronizedMap方法构造出一个同步Map,或者直接使用线程安全的ConcurrentHashMap。
Java 7基于分段锁的ConcurrentHashMap
注:本章的代码均基于JDK 1.7.0_67
数据结构
Java 7中的ConcurrentHashMap的底层数据结构仍然是数组和链表。与HashMap不同的是,ConcurrentHashMap最外层不是一个大的数组,而是一个Segment的数组。每个Segment包含一个与HashMap数据结构差不多的链表数组。整体数据结构如下图所示。
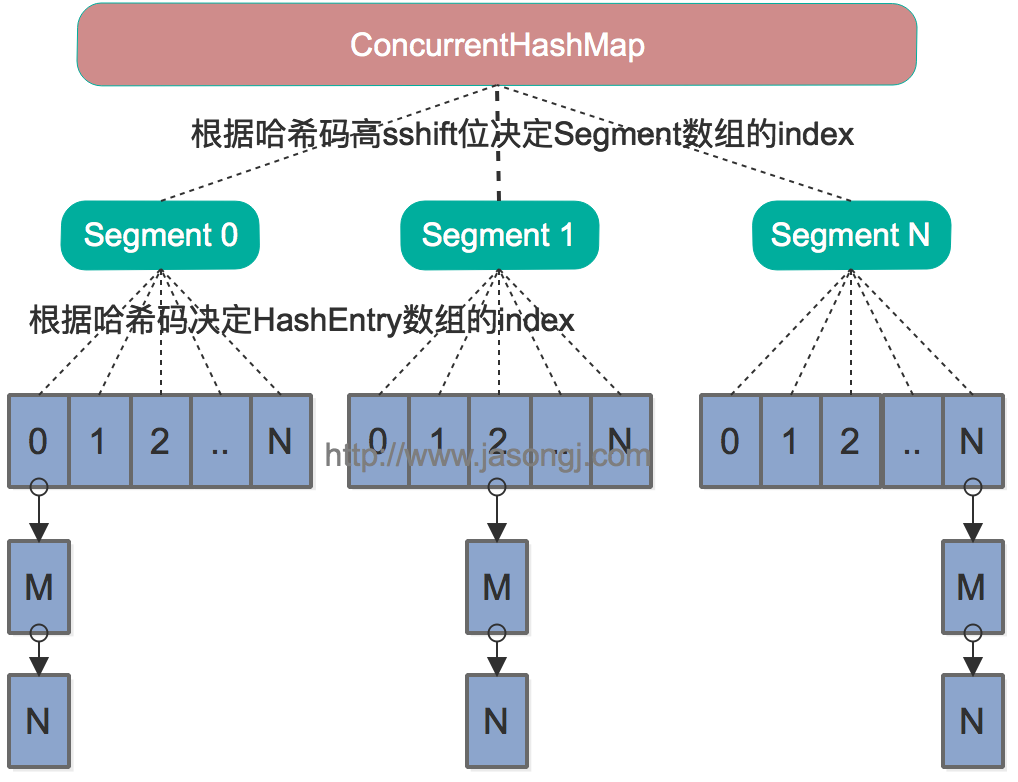
寻址方式
在读写某个Key时,先取该Key的哈希值。并将哈希值的高N位对Segment个数取模从而得到该Key应该属于哪个Segment,接着如同操作HashMap一样操作这个Segment。为了保证不同的值均匀分布到不同的Segment,需要通过如下方法计算哈希值。
private int hash(Object k) {
int h = hashSeed;
if ((0 != h) && (k instanceof String)) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}
同样为了提高取模运算效率,通过如下计算,ssize即为大于concurrencyLevel的最小的2的N次方,同时segmentMask为2^N-1。这一点跟上文中计算数组长度的方法一致。对于某一个Key的哈希值,只需要向右移segmentShift位以取高sshift位,再与segmentMask取与操作即可得到它在Segment数组上的索引。
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
同步方式
Segment继承自ReentrantLock,所以我们可以很方便的对每一个Segment上锁。
对于读操作,获取Key所在的Segment时,需要保证可见性(请参考如何保证多线程条件下的可见性)。具体实现上可以使用volatile关键字,也可使用锁。但使用锁开销太大,而使用volatile时每次写操作都会让所有CPU内缓存无效,也有一定开销。ConcurrentHashMap使用如下方法保证可见性,取得最新的Segment。
Segment<K,V> s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)
获取Segment中的HashEntry时也使用了类似方法
HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE)
对于写操作,并不要求同时获取所有Segment的锁,因为那样相当于锁住了整个Map。它会先获取该Key-Value对所在的Segment的锁,获取成功后就可以像操作一个普通的HashMap一样操作该Segment,并保证该Segment的安全性。
同时由于其它Segment的锁并未被获取,因此理论上可支持concurrencyLevel(等于Segment的个数)个线程安全的并发读写。
获取锁时,并不直接使用lock来获取,因为该方法获取锁失败时会挂起(参考可重入锁)。事实上,它使用了自旋锁,如果tryLock获取锁失败,说明锁被其它线程占用,此时通过循环再次以tryLock的方式申请锁。如果在循环过程中该Key所对应的链表头被修改,则重置retry次数。如果retry次数超过一定值,则使用lock方法申请锁。
这里使用自旋锁是因为自旋锁的效率比较高,但是它消耗CPU资源比较多,因此在自旋次数超过阈值时切换为互斥锁。
size操作
put、remove和get操作只需要关心一个Segment,而size操作需要遍历所有的Segment才能算出整个Map的大小。一个简单的方案是,先锁住所有Sgment,计算完后再解锁。但这样做,在做size操作时,不仅无法对Map进行写操作,同时也无法进行读操作,不利于对Map的并行操作。
为更好支持并发操作,ConcurrentHashMap会在不上锁的前提逐个Segment计算3次size,如果某相邻两次计算获取的所有Segment的更新次数(每个Segment都与HashMap一样通过modCount跟踪自己的修改次数,Segment每修改一次其modCount加一)相等,说明这两次计算过程中无更新操作,则这两次计算出的总size相等,可直接作为最终结果返回。如果这三次计算过程中Map有更新,则对所有Segment加锁重新计算Size。该计算方法代码如下
public int size() {
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}
不同之处
ConcurrentHashMap与HashMap相比,有以下不同点
- ConcurrentHashMap线程安全,而HashMap非线程安全
- HashMap允许Key和Value为null,而ConcurrentHashMap不允许
- HashMap不允许通过Iterator遍历的同时通过HashMap修改,而ConcurrentHashMap允许该行为,并且该更新对后续的遍历可见
Java 8基于CAS的ConcurrentHashMap
注:本章的代码均基于JDK 1.8.0_111
数据结构
Java 7为实现并行访问,引入了Segment这一结构,实现了分段锁,理论上最大并发度与Segment个数相等。Java 8为进一步提高并发性,摒弃了分段锁的方案,而是直接使用一个大的数组。同时为了提高哈希碰撞下的寻址性能,Java 8在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为O(N))转换为红黑树(寻址时间复杂度为O(long(N)))。其数据结构如下图所示
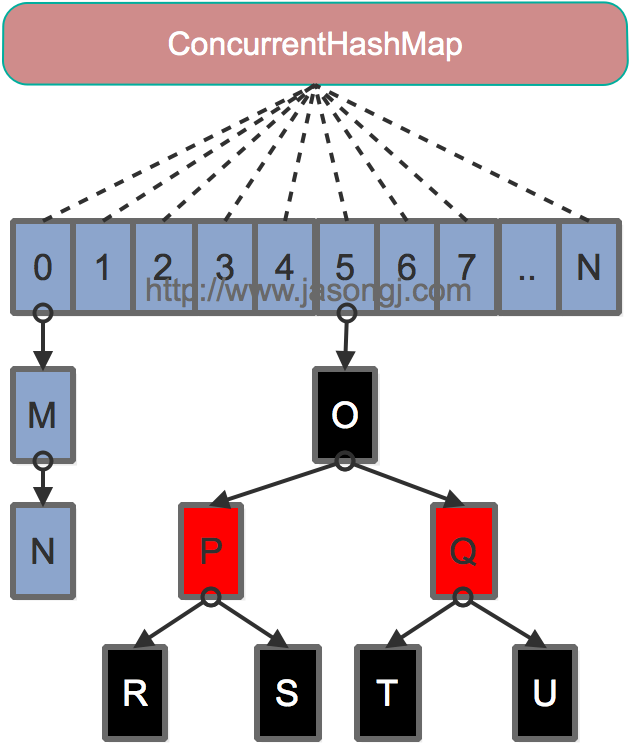
寻址方式
Java 8的ConcurrentHashMap同样是通过Key的哈希值与数组长度取模确定该Key在数组中的索引。同样为了避免不太好的Key的hashCode设计,它通过如下方法计算得到Key的最终哈希值。不同的是,Java 8的ConcurrentHashMap作者认为引入红黑树后,即使哈希冲突比较严重,寻址效率也足够高,所以作者并未在哈希值的计算上做过多设计,只是将Key的hashCode值与其高16位作异或并保证最高位为0(从而保证最终结果为正整数)。
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
同步方式
对于put操作,如果Key对应的数组元素为null,则通过CAS操作将其设置为当前值。如果Key对应的数组元素(也即链表表头或者树的根元素)不为null,则对该元素使用synchronized关键字申请锁,然后进行操作。如果该put操作使得当前链表长度超过一定阈值,则将该链表转换为树,从而提高寻址效率。
对于读操作,由于数组被volatile关键字修饰,因此不用担心数组的可见性问题。同时每个元素是一个Node实例(Java 7中每个元素是一个HashEntry),它的Key值和hash值都由final修饰,不可变更,无须关心它们被修改后的可见性问题。而其Value及对下一个元素的引用由volatile修饰,可见性也有保障。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
}
对于Key对应的数组元素的可见性,由Unsafe的getObjectVolatile方法保证。
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
size操作
put方法和remove方法都会通过addCount方法维护Map的size。size方法通过sumCount获取由addCount方法维护的Map的size。
Java进阶系列
- Java进阶(一)Annotation(注解)
- Java进阶(二)当我们说线程安全时,到底在说什么
- Java进阶(三)多线程开发关键技术
- Java进阶(四)线程间通信方式对比
- Java进阶(五)NIO和Reactor模式进阶
- Java进阶(六)从ConcurrentHashMap的演进看Java多线程核心技术
从ConcurrentHashMap的演进看Java多线程核心技术 Java进阶(六)的更多相关文章
- Java多线程核心技术(六)线程组与线程异常
本文应注重掌握如下知识点: 线程组的使用 如何切换线程状态 SimpleDataFormat 类与多线程的解决办法 如何处理线程的异常 1.线程的状态 线程对象在不同运行时期有不同的状态,状态信息就处 ...
- Java多线程核心技术(五)单例模式与多线程
本文只需要考虑一件事:如何使单例模式遇到多线程是安全的.正确的 1.立即加载 / "饿汉模式" 什么是立即加载?立即加载就是使用类的时候已经将对象创建完毕,常见的实现办法就是直接 ...
- Java多线程核心技术(四)Lock的使用
本文主要介绍使用Java5中Lock对象也能实现同步的效果,而且在使用上更加方便. 本文着重掌握如下2个知识点: ReentrantLock 类的使用. ReentrantReadWriteLock ...
- 160711、Java 多线程核心技术梳理
本文对多线程基础知识进行梳理,主要包括多线程的基本使用,对象及变量的并发访问,线程间通信,lock 的使用,定时器,单例模式,以及线程状态与线程组. java 多线程 基础知识 创建线程的两种方式:1 ...
- Java多线程(Java总结篇)
Java总结篇:Java多线程 多线程作为Java中很重要的一个知识点,在此还是有必要总结一下的. 一.线程的生命周期及五种基本状态 关于Java中线程的生命周期,首先看一下下面这张较为经典的图: 上 ...
- [转载] java多线程学习-java.util.concurrent详解(一) Latch/Barrier
转载自http://janeky.iteye.com/blog/769965 Java1.5提供了一个非常高效实用的多线程包:java.util.concurrent, 提供了大量高级工具,可 ...
- “全栈2019”Java多线程第三十六章:如何设置线程的等待截止时间
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 下一章 "全栈2019"J ...
- 关于Java多线程(JAVA多线程实现的四种方式)
Java多线程实现方式主要有四种:继承Thread类.实现Runnable接口.实现Callable接口通过FutureTask包装器来创建Thread线程.使用ExecutorService.Cal ...
- java多线程核心技术——第四章总结
第一节使用ReentrantLock类 1.1使用ReentrantLock实现同步:测试1 1.2使用ReentrantLock实现同步:测试2 1.3使用Condition实现等待/同步错误用法与 ...
随机推荐
- React入门---开始前的准备(下)-3
React开始前的准备(下): ·配置webpack热加载(热加载就是修改js文件,点击保存之后,浏览器会自动刷新,提高开发效率) 1. 全局安装: npm install webpack -g np ...
- python课时二
通过上个博客的学习,相信大家已经对Python是什么东西应该有了相对应的了解,这里也包括Python的一些语法(比如Python在写for循环和if判断的时候都是会有缩进的).这张博客大概会对Pyth ...
- 基于HTML5快速搭建TP-LINK电信拓扑设备面板
今天我们以真实的TP-LINK设备面板为模型,完成设备面板的搭建,和指示灯的闪烁和图元流动. 先来目睹下最终的实现效果:http://www.hightopo.com/demo/blog_tplink ...
- Longest Substring Without Repeating Characters2015年6月9日
Given a string, find the length of the longest substring without repeating characters. For example, ...
- JSP中include指令和include动作区别
首先 <%@ include file=” ”%>:为指令元素 <jsp:include page=” ” flush=”true”/>:为 动作元素 先说指令元素: incl ...
- 开涛spring3(9.4) - Spring的事务 之 9.4 声明式事务
9.4 声明式事务 9.4.1 声明式事务概述 从上节编程式实现事务管理可以深刻体会到编程式事务的痛苦,即使通过代理配置方式也是不小的工作量. 本节将介绍声明式事务支持,使用该方式后最大的获益是简 ...
- Windows 7 蓝屏代码大全 & 蓝屏全攻略
关于Windows 7.Vista等系统的蓝屏,之前软媒在Win7之家和Vista之家都有很多文章讨论过,但是都是筛选的常见的一些问题,今天这个文章是个大全,希望大家看着别头痛,文章收藏下来以后待查即 ...
- 06.04 html
域名跟ip地址是绑定的看某个网站的ip地址 可以ping网址知道ip地址 最终访问的都是ip地址 每个ip地址都对应了一个空间(一块区域 要用来存储内容)网页访问的原理: 客户端电脑发动请求到服 ...
- 使用SQL语句使数据从坚向排列转化成横向排列(排班表)
知识重点: 1.extract(day from schedule01::timestamp)=13 Extract 属于 SQL 的 DML(即数据库管理语言)函数,同样,InterBase 也支持 ...
- Jquery取属性值(复选框、下拉列表、单选按钮)、做全选按钮、JSON存储、去空格
1.jquery取复选框的值 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "htt ...