从零到一:利用金仓社区数据,LoRa微调与Spring AI 构建私有化千问模型
上次我们在Coze平台上成功搭建了一个针对金仓问题的解决助手。这个智能体的核心工作流程相对简单:每次它通过HTTP接口调用插件,在金仓平台内部进行搜索,随后利用大模型的推理能力对查询结果进行分析,从而为用户提供问题解答。然而,问题也随之而来——金仓内部的搜索功能存在一定的局限性。搜索出来的博文资料之间的关联性并不强,这使得智能体在回答问题时,往往需要检索大量、冗长的资料,甚至有时需要检索上万字的内容才能找到有价值的信息,从而影响了整体的工作效率。

针对这一问题,我们的目标是优化和提高智能体回答问题的准确性与效率。通过深入分析,问题的本质其实就是如何更有效地利用已有资料进行推理和回答。尽管我们无法直接改变金仓社区的搜索机制,但我们可以采取一种间接的方式:提前对社区开放的文档或博文进行检索,并基于这些内容对已有的大模型进行微调。通过这种方法,大模型在处理用户问题时可以更高效地利用已知信息,进而提供更精准的答案,达到与直接优化搜索机制类似的效果。
好的,今天我们的主要目标是利用现有的资料对Qwen2.5-7B-Instruct开源模型进行Lora微调,旨在使其能够真正地在离线环境下回答用户的问题。考虑到社区中关于该模型的博文和文档资料非常丰富,我们今天将聚焦在一特定领域,我们会专注于数据库迁移方面的训练,确保模型能够在没有网络连接的情况下,依然具备有效的知识查询与处理能力。
什么是LoRa
智能体(AI)技术已经广泛应用并逐渐深入人们的日常生活,大家对它有了较为全面的了解。然而,当前大规模语言模型的微调技术尚未真正普及,其原因主要在于高门槛的问题。首先,微调大模型不仅需要强大的计算资源,像高性能的服务器、GPU等硬件设备,而且还需要解决诸如各种复杂的参数设置等技术难题,这使得很多企业和个人难以承受。
此外,真正从零开始训练一个大模型,所需的资源和成本也是常规公司难以负担的,因此目前广泛采用的策略是基于已有的预训练模型进行再训练(fine-tuning)。这种方法充分利用了现有大模型的基础架构,再加上企业内部的专有数据进行定制化调整,能够大大降低训练成本并提高模型的适应性和效率。一个典型的技术就是LoRa(Low-Rank Adaptation)技术,它通过优化参数空间,使得企业能够在不重新训练整个模型的情况下,针对特定任务进行快速微调。
这部分技术内容并不是我们目前关注的重点,因此在这里就不再详细展开。
环境准备
要想使用资料库数据进行微调,我们需要做好充分的准备。首先,必须准备好内部资料数据,确保数据的质量和多样性,能够覆盖所需的业务场景或问题。其次,还需要一台配备GPU的服务器,确保能够提供足够的计算能力来处理大量数据,并支持深度学习模型的训练和优化。
资料准备
我们主要致力于针对数据库迁移问题的解决方案进行训练,为了高效获取相关的资料和内容,我们直接访问金仓社区,进行检索并下载与数据库迁移相关的最新数据和文档,具体操作步骤如图所示:
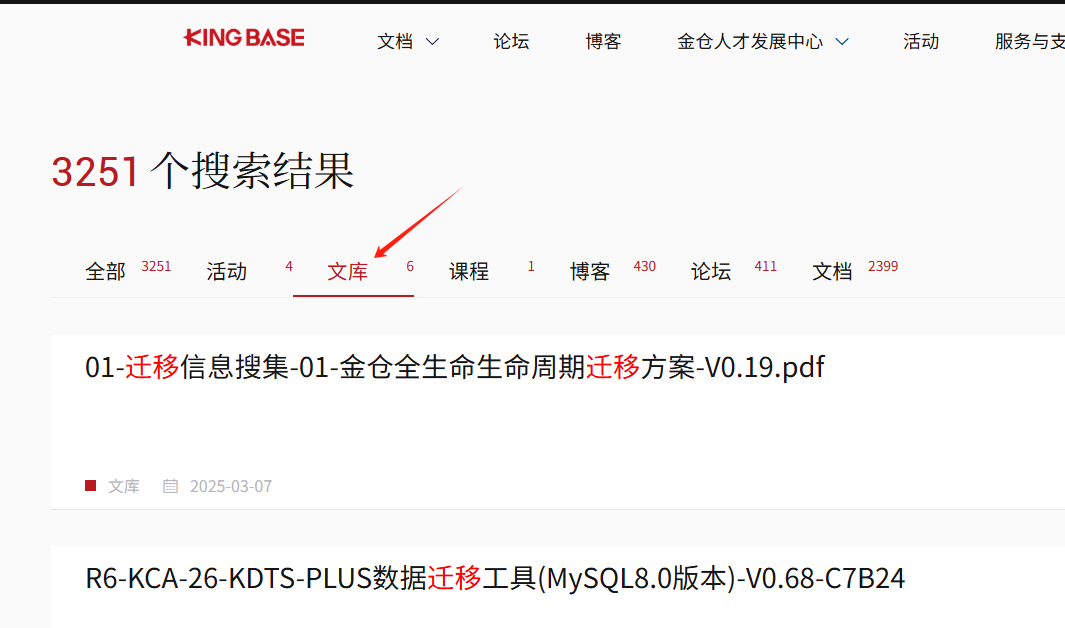
数据下载
接下来,我们将直接下载相关的文档或文库,以便更好地了解和使用相关资源,具体操作如下图所示:
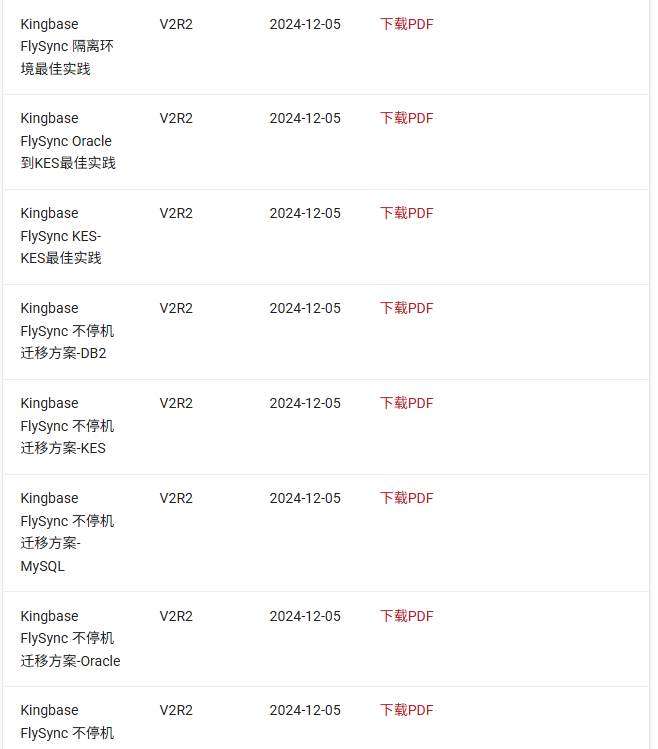
另外,还有一些资料来源,例如博客、论坛等在线资源。我们可以直接选择使用爬虫进行抓取,但为了避免对社区服务器造成过多负担,我们决定采取更为温和的方式,即将相关数据直接保存到本地,随后进行解析和信息提取。具体操作如图所示:

指令集构建
好的,有了这些基本数据之后,接下来我们需要将其解析成我们所需的数据集格式,以便进行后续的处理和分析。LLM(大语言模型)的微调,通常是指指令微调过程。所谓指令微调,指的是通过特定格式的微调数据来引导模型学习如何根据给定的指令进行响应。这些微调数据通常具有如下的结构和形式::
[{
"instruction": "KES是什么?",
"input": "",
"output": "KES是人大金仓的简称。"
}]
其中,instruction 是用户指令,告知模型其需要完成的任务;input 是用户输入,是完成用户指令所必须的输入内容;output 是模型应该给出的输出。
既然我们已经获得了目标格式的内容,接下来需要做的就是对这些文档进行解析。为此,我们将采用Spring AI,它支持对多种文件格式的解析,包括但不限于PDF、HTML、Markdown、JSON、Docx等。当前,我们所处理的文档格式仅限于PDF和HTML,因此Spring AI完全能够满足我们的需求。
文档提取
首先需要创建一个新的 Spring Boot 项目,并在项目中引入所需的相关依赖。项目的基本结构安排如下所示:
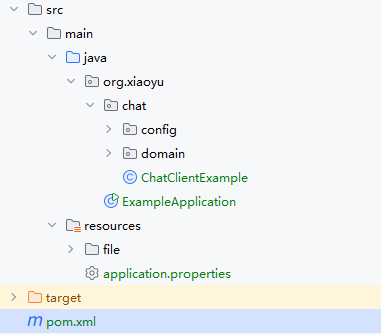
接下来,我们将引入项目中所需的POM依赖,以确保相关的库和工具能够被正确加载和使用,具体的依赖项如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.0</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<artifactId>02-example-RAG-backend</artifactId>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<knife4j-version>4.1.0</knife4j-version>
<hutool-version>5.8.2</hutool-version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0-M8</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-openapi3-jakarta-spring-boot-starter</artifactId>
<version>${knife4j-version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-jsoup-document-reader</artifactId>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>${hutool-version}</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
<repository>
<name>Central Portal Snapshots</name>
<id>central-portal-snapshots</id>
<url>https://central.sonatype.com/repository/maven-snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
</project>
在这里,我们引入了当前 M8 版本的 Spring AI 以及 OpenAI 提供的相关模型接口。这是因为在完成文档提取后,我们需要将提取到的数据进行解析,转化为指令集格式。借助 AI我们能够显著减少传统手工数据清理所需的工作量。此外,我们还引入了与相关模型接口配套的秘钥配置信息,确保系统能够访问并使用这些服务。具体的配置如下所示:
server.port=9166
spring.ai.openai.base-url=
spring.ai.openai.api-key=
spring.ai.openai.chat.options.model=
这里主要是配置OpenAI接口的相关信息。如果你没有国外的API访问权限,实际上国内的大部分大模型也能兼容这种接口配置,你可以直接填入相应的国内大模型接口,基本也能顺利调用。
接下来,我们将利用Spring AI的文档提取器对文档进行解析,具体的实现代码如下:
public List<Document> getDocsFromHTML() throws IOException {
ResourcePatternResolver resolver = new PathMatchingResourcePatternResolver(resourceLoader);
org.springframework.core.io.Resource[] resourceArray = resolver.getResources("classpath:/file/*.html");
List<Document> documentList = Arrays.stream(resourceArray)
.flatMap(resource -> {
JsoupDocumentReader reader = new JsoupDocumentReader(resource,
JsoupDocumentReaderConfig.builder()
.selector("p") // 可根据实际结构调整选择器
.charset("UTF-8")
.build());
return reader.get().stream();
})
.collect(Collectors.toList());
return documentList;
}
这里主要解析如何从HTML文件中提取文本内容。由于下载的HTML文件通常包含了各种样式、脚本以及其他无关信息,因此我们仅关注其中的文本段落部分,即<p>标签中的文字内容。除此之外,我们还讨论了如何从PDF文档中提取文本,具体实现方法如下所示:
public List<Document> getDocsFromPDF() throws IOException {
ResourcePatternResolver resolver = new PathMatchingResourcePatternResolver(resourceLoader);
org.springframework.core.io.Resource[] resourceArray = resolver.getResources("classpath:/file/*.{pdf,PDF,Pdf}");
List<Document> documentList = Arrays.stream(resourceArray)
.filter(resource -> resource.getFilename() != null &&
resource.getFilename().toLowerCase().endsWith(".pdf"))
.flatMap(resource -> {
//打印文件名字
System.out.println("文件名字:" + resource.getFilename());
try {
ParagraphPdfDocumentReader pdfReader = new ParagraphPdfDocumentReader(resource,
PdfDocumentReaderConfig.builder()
.withPageTopMargin(0)
.withPageExtractedTextFormatter(ExtractedTextFormatter.builder()
.withNumberOfTopTextLinesToDelete(0)
.build())
.withPagesPerDocument(1)
.build());
return pdfReader.read().stream();
}catch (Exception e){
PagePdfDocumentReader pdfReader = new PagePdfDocumentReader(resource,
PdfDocumentReaderConfig.builder()
.withPageTopMargin(0)
.withPageExtractedTextFormatter(ExtractedTextFormatter.builder()
.withNumberOfTopTextLinesToDelete(0)
.build())
.withPagesPerDocument(2)
.build());
return pdfReader.read().stream();
}
})
.collect(Collectors.toList());
return documentList;
}
在文本提取的过程中,我将其分为两种不同的格式进行处理。第一种是使用 ParagraphPdfDocumentReader 类,该类能够提取带有目录的PDF文件,并根据目录内容进行分批提取。另一种是处理没有目录的PDF文件,此时使用 PagePdfDocumentReader 类,该类会根据页数对PDF文件进行逐页文本提取。
无论是通过哪种方式提取文本,最终提取的内容都会被自动封装为适合向量数据库存储的 Document 格式。在此过程中,我们只关注文本内容,其他部分的内容将被忽略,确保AI能够高效地进行提取处理。具体代码实现如下所示:
public List<InputData> aiByHTML() throws IOException {
List<Document> docsFromHTML = getDocsFromHTML();
TokenTextSplitter splitter = new TokenTextSplitter();
List<Document> documentList = splitter.apply(docsFromHTML);
// documentList = enricher.apply(documentList);
List<Future<List<InputData>>> futures = documentList.stream()
.map(doc -> executorService.submit(() -> processDocument(doc).toList()))
.collect(Collectors.toList());
List<InputData> results = new ArrayList<>();
for (Future<List<InputData>> future : futures) {
try {
results.addAll(future.get());
} catch (Exception e) {
log.error("Error processing document in thread: {}", e.getMessage());
}
}
return results;
}
由于HTML提取后的每篇博文或文档通常包含大量文字,因此我们需要使用 TokenTextSplitter 类对提取的文本进行切割。切割后的文本会被分成多个更小的块,以便更高效地处理。为了加快处理速度,本文还采用了线程池的方式,让AI能够并行地快速解析文档内容。具体的代码实现如下所示:
private Stream<InputData> processDocument(Document document) {
String jsonStr = document.getText();
log.info("Processing document content: {}", jsonStr.length() > 100 ? jsonStr.substring(0, 100) : jsonStr);
try {
List<InputData> dataList = chatClient.prompt()
.system("""
- Role: 数据清洗专家和信息提取工程师
- Background: 用户需要从一系列包含KES人大金仓迁移内容的文档中提取关键信息,但文档中存在大量无关内容,需要高效地筛选出有价值的部分。
- Profile: 你是一位资深的数据清洗专家,擅长从海量文本中提取关键信息,具备强大的文本分析能力和信息筛选能力,能够精准识别与KES人大金仓迁移相关的知识点、注意点和实践经验。
- Skills: 你精通自然语言处理技术、文本挖掘方法和信息筛选策略,能够快速定位和提取文档中的关键内容,同时排除无关信息。
- Goals: 从用户提供的文档中提取与KES人大金仓迁移相关的注意点、知识点和实践经验,必须去除无关内容,确保提取的信息准确、完整且有价值。
- Constrains: 提取的信息应简洁明了,避免冗余,确保与KES人大金仓迁移直接相关,禁止包含无关内容。禁止出现本文、后台获取等字样。
- OutputFormat: 以结构化的形式输出提取的关键信息,包括知识点、注意点和实践经验的分类整理。
- Workflow:
1. 仔细阅读用户提供的文档,理解文档的整体内容和结构。
2. 确定与KES人大金仓迁移相关的关键词和主题,如“迁移注意点”“KES知识点”“迁移实践”等。
3. 运用文本分析技术,必须从文档中提取与这些关键词和主题相关的内容,同时排除无关信息。
4. 对提取的内容进行分类整理,形成结构化的输出。
5. instruction为问题,input固定为"",output为问题答案,问题答案字数必须在200-400字范围之间且必须为Markdown格式。
- Example:
[{
"instruction": "KES是什么?",
"input": "",
"output": "KES是人大金仓的简称。"
}]
""")
.user(jsonStr)
.options(ChatOptions.builder().temperature(0.8).build())
.call()
.entity(new ParameterizedTypeReference<List<InputData>>() {});
log.info("dataList size: {}", dataList != null ? dataList.size() : 0);
return dataList == null ? Stream.empty() : dataList.stream();
} catch (Exception e) {
log.error("Error processing document: {}", ExceptionUtil.stacktraceToString(e));
return Stream.empty();
}
}
我们通过简单的提示词来引导 AI 进行总结和归纳,生成一系列指令集。最后,利用结构化输出,将这些指令封装成具体的类,以便进一步使用和管理。具体的实现代码如下所示:
public record InputData(String instruction, String input, String output) {}
最后,我们将处理后的数组以JSON格式写入文件中,基本的流程就此完成。接下来,我们可以查看最终的提取效果,具体效果如图所示:

综合来看,数据集整体表现尚可,但提示词仍需要进一步优化。最终生成的数据集规模也不理想,只有几百条数据,基本上无法进行有效训练。为了展示整体效果,我多次运行相同的文档,最终凑足了2000多个数据样本。不过,这样的做法肯定存在一定问题。因此,如果时间允许,还是应该多下载一些文献或资料,以确保数据集的质量和规模足够支持更好的训练效果。
服务器准备
接下来,在解析完指令集后,我们需要进行大模型微调。首先,确保你有一台至少具备20GB GPU内存的服务器。如果没有,可以考虑在云端租赁一台。这里我使用的是AutoDL AI算力云,具体细节就不再赘述。
如果你没有微调的经验,我建议从零开始学习。我个人是在一个开源项目中积累经验的,开源项目地址如下:https://github.com/datawhalechina/self-llm
微调
接下来,我们需要租赁一台服务器,环境依赖可以直接使用社区提供的镜像。开源项目也提供了相关的镜像,大家可以根据自己的需求进行创建。最终的配置如下图所示:

接下来,我们将使用JupyterLab快速连接到服务器。如图所示:
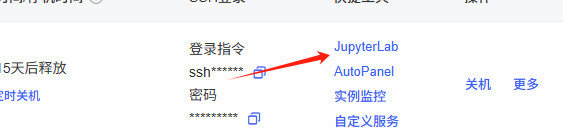
我使用的是从Qwen2.5-7B拉取的镜像,该镜像已包含开源项目所需的所有文件和目录。如图所示:
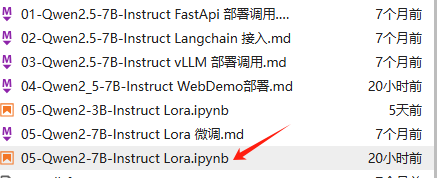
接下来,我们只需将数据集上传至指定位置,并根据需要调整相关文件目录设置,具体操作步骤如下图所示:
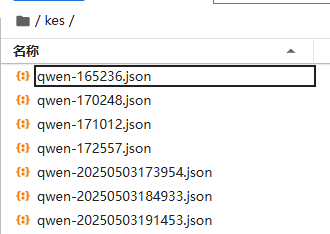
代码只需简单修改数据集地址,由于数据集包含多个 JSON 文件,因此需要在加载所有文件后进行合并。以下是修改后的代码:
import os
import glob
import pandas as pd
from datasets import Dataset
# 设置目录路径
directory_path = 'kes' # 替换为你的目录路径
# 获取目录下所有的 JSON 文件
json_files = glob.glob(os.path.join(directory_path, '*.json'))
# 存储所有加载的 JSON 数据
all_data = []
# 遍历所有 JSON 文件并加载它们
for json_file in json_files:
print(f"正在加载: {json_file}")
df = pd.read_json(json_file) # 加载每个 JSON 文件为 DataFrame
all_data.append(df)
# 合并所有的 DataFrame
combined_df = pd.concat(all_data, ignore_index=True)
# 将 DataFrame 转换为 Hugging Face Dataset
ds = Dataset.from_pandas(combined_df)
在对相关指令进行修改时,主要是将系统提示词更改为“金仓小助手”,具体修改内容如下所示:
def process_func(example):
MAX_LENGTH = 384 # Llama分词器会将一个中文字切分为多个token,因此需要放开一些最大长度,保证数据的完整性
input_ids, attention_mask, labels = [], [], []
instruction = tokenizer(f"<|im_start|>system\n现在你是人大金仓的小助手<|im_end|>\n<|im_start|>user\n{example['instruction'] + example['input']}<|im_end|>\n<|im_start|>assistant\n", add_special_tokens=False) # add_special_tokens 不在开头加 special_tokens
## 省略重复代码
接下来,将进入微调训练的过程,具体步骤如下图所示:
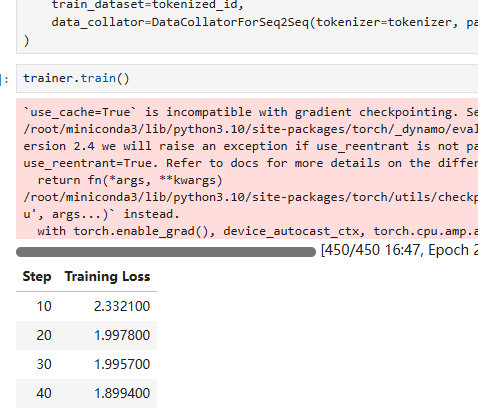
整个过程大约需要花费我们10分钟左右的时间,考虑到目前数据集的规模还相对较小,处理速度不会太慢。
效果演示
最后,训练完成后,我们将进行一个简单的测试,以评估Lora微调的效果。下面是相关的代码实现:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from peft import PeftModel
mode_path = '/root/autodl-tmp/qwen/Qwen2.5-7B-Instruct/'
lora_path = './output/Qwen2.5_instruct_lora/checkpoint-450' # 这里改称你的 lora 输出对应 checkpoint 地址
# 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(mode_path, trust_remote_code=True)
# 加载模型
model = AutoModelForCausalLM.from_pretrained(mode_path, device_map="auto",torch_dtype=torch.bfloat16, trust_remote_code=True).eval()
# 加载lora权重
model = PeftModel.from_pretrained(model, model_id=lora_path)
prompt = "KES数据迁移工具KDTS支持哪些源数据库的迁移?"
inputs = tokenizer.apply_chat_template([{"role": "system", "content": "假设你是人大金仓的小助手。"},{"role": "user", "content": prompt}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True
).to('cuda')
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
目前,我们的Lora权重尚未与基础模型合并,而只是被加载到模型中。在此,我们将进行一个简单的测试,目的是查看加载后的效果和验证Lora权重的作用,输出如下所示:
- 支持Oracle、MySQL、SQLServer、Gbase、PostgreSQL、DM、KingbaseES等数据库作为源端进行数据迁移。
- 这些数据库版本均被纳入支持范围,确保迁移过程中的兼容性和稳定性。
如果你希望将可视化的WEB页面暴露出来进行访问,首先需要根据部署文件的要求操作。具体步骤是:创建一个名为 chatbot.py 的新文件,并在该文件中编写以下内容:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import streamlit as st
from peft import PeftModel
# 在侧边栏中创建一个标题和一个链接
with st.sidebar:
st.markdown("## Qwen2.5 LLM")
"[开源大模型食用指南 self-llm](https://github.com/datawhalechina/self-llm.git)"
# 创建一个滑块,用于选择最大长度,范围在 0 到 8192 之间,默认值为 512(Qwen2.5 支持 128K 上下文,并能生成最多 8K tokens)
max_length = st.slider("max_length", 0, 8192, 512, step=1)
# 创建一个标题和一个副标题
st.title(" Qwen2.5 Chatbot")
st.caption(" A streamlit chatbot powered by Self-LLM")
# 定义一个函数,用于获取模型和 tokenizer
@st.cache_resource
def get_model():
# 从预训练的模型中获取 tokenizer
# tokenizer = AutoTokenizer.from_pretrained(mode_name_or_path, trust_remote_code=True)
# 从预训练的模型中获取模型,并设置模型参数
# model = AutoModelForCausalLM.from_pretrained(mode_name_or_path, torch_dtype=torch.bfloat16, device_map="auto")
mode_path = '/root/autodl-tmp/qwen/Qwen2.5-7B-Instruct/'
lora_path = '/root/output/Qwen2.5_instruct_lora/checkpoint-450' # 这里改称你的 lora 输出对应 checkpoint 地址
# 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(mode_path, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
# 加载模型
model = AutoModelForCausalLM.from_pretrained(mode_path, device_map="auto",torch_dtype=torch.bfloat16, trust_remote_code=True).eval()
# 加载lora权重
model = PeftModel.from_pretrained(model, model_id=lora_path)
return tokenizer, model
# 加载 Qwen2.5 的 model 和 tokenizer
tokenizer, model = get_model()
# 如果 session_state 中没有 "messages",则创建一个包含默认消息的列表
if "messages" not in st.session_state:
st.session_state["messages"] = [{"role": "system", "content": "假设你是人大金仓的小助手。"},{"role": "assistant", "content": "我是人大金仓小助手,有什么可以帮您的?"}]
# 遍历 session_state 中的所有消息,并显示在聊天界面上
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])
# 如果用户在聊天输入框中输入了内容,则执行以下操作
if prompt := st.chat_input():
# 在聊天界面上显示用户的输入
st.chat_message("user").write(prompt)
# 将用户输入添加到 session_state 中的 messages 列表中
st.session_state.messages.append({"role": "user", "content": prompt})
# 将对话输入模型,获得返回
input_ids = tokenizer.apply_chat_template(st.session_state.messages,tokenize=False,add_generation_prompt=True)
model_inputs = tokenizer([input_ids], return_tensors="pt").to('cuda')
generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=max_length)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 将模型的输出添加到 session_state 中的 messages 列表中
st.session_state.messages.append({"role": "assistant", "content": response})
# 在聊天界面上显示模型的输出
st.chat_message("assistant").write(response)
# print(st.session_state) # 打印 session_state 调试
我在开源项目的基础上进行了一些自定义修改,主要包括对 checkpoint 和系统提示词等参数的调整。最终,我们通过命令行启动该系统,具体命令如下:
streamlit run /root/autodl-tmp/chatBot.py --server.address 127.0.0.1 --server.port 6006

接下来,我们将按照算力云提供的操作步骤,逐步进行相关设置和操作。每个步骤都严格按照指南执行,以确保顺利完成配置和启动,具体流程请参见下图所示:
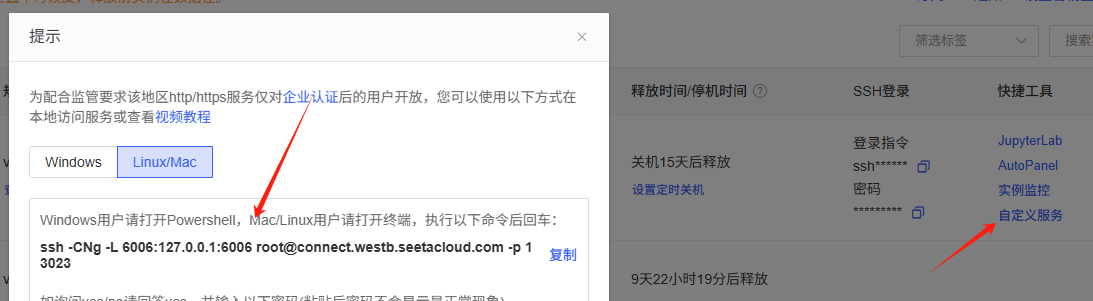
我们通过命令行形式来展示效果,具体情况请参考下方截图:

成功完成上述步骤后,接下来我们可以直接访问本地的 6006 端口,访问地址为:http://localhost:6006,进入相应的界面进行进一步操作。

我就不拿7B的基础模型作对比了,因为其效果显然不如Lora微调后的版本。为了做一个更合适的对比,我选择了我常用的Kimi模型。通过对比可以看出,确实在没有联网的情况下,某些知识的表现不如微调后的效果。然而,由于微调所用的数据集范围相对较窄,这导致了一定程度的过拟合现象。不过,总体来看,整个微调流程大致就是这样展开的。
不过,微调后的效果还算令人满意,而且相较于通过智能体联网搜索社区的方式,回复速度明显提升了许多,响应时间更快。同时,token的花费也显著降低了。更为重要的是,经过微调的模型完全可以进行私有化部署,这样一来,企业内部的数据安全性得到了保障,不用担心数据泄露的问题。
总结
好的,本次关于金仓迁移相关的微调文章就到此结束。我们不仅成功解决了金仓平台中搜索功能导致智能体检索响应慢的问题,还有效控制了token费用的高昂支出。在这个过程中,我们通过利用现有的文档和博文,对大模型进行了微调。通过提前检索和处理金仓社区的相关资料,微调后的大模型能够在没有网络连接的情况下,依靠更加精确的知识库进行问题解答,从而弥补了原有搜索机制的不足之处。
在微调过程中,尽管我们面临了许多挑战,例如文档数据的整理和提取、指令集的构建等问题,但通过借助Spring AI等框架工具,我们成功地将非结构化的文档数据转化为结构化信息,确保了微调过程的顺利进行。最终,我们实现了模型的私有化部署,并使用Streamlit进行了可视化展示和部署,圆满完成了整个微调环节。希望这次分享能够对大家的工作和研究提供一定的帮助和启发!
我是努力的小雨,一个正经的 Java 东北服务端开发,整天琢磨着 AI 技术这块儿的奥秘。特爱跟人交流技术,喜欢把自己的心得和大家分享。还当上了腾讯云创作之星,阿里云专家博主,华为云云享专家,掘金优秀作者。各种征文、开源比赛的牌子也拿了。
想把我在技术路上走过的弯路和经验全都分享出来,给你们的学习和成长带来点启发,帮一把。
欢迎关注努力的小雨,咱一块儿进步!
从零到一:利用金仓社区数据,LoRa微调与Spring AI 构建私有化千问模型的更多相关文章
- 蚂蚁金服首席数据科学家漆远:AI技术开放,与业界融合共创
小蚂蚁说: 11月8日,在第五届世界互联网大会-<人工智能:融合发展新机遇>论坛上,蚂蚁金服副总裁.首席数据科学家漆远认为AI具有控制风险.降本增效和提升用户体验三大作用. 11月8日,第 ...
- Rocky4.2下安装金仓v7数据库(KingbaseES)
1.准备操作系统 1.1 系统登录界面 1.2 操作系统版本信息 jdbh:~ # uname -ra Linux jdbh -x86_64 # SMP Fri Dec :: CST x86_64 G ...
- 润乾配置连接kingbase(金仓)数据库
问题背景 客户根据项目的不同,使用润乾连接的数据库类型各种各样,此文针对前几日使用润乾设计器连接kingbase金仓数据库做一个说明. kingbase金仓数据库是一款国产数据库,操作方式和配置 ...
- 通过ODBC接口访问人大金仓数据库
国产化软件和国产化芯片的窘境一样,一方面市场已经存在性能优越的同类软件,成本很低,但小众的国产化软件不仅需要高价买入版权,并且软件开发维护成本高:另一方面,国产软件目前普遍难用,性能不稳定,Bug ...
- 金仓Kingbase数据库网页数据维护分析工具
金仓Kingbase是优秀的国产数据库产品,在能源,政务,国防等领域广泛使用, 现在TreeSoft数据库管理系统已支持Kingbase了,直接在浏览器中就可以操作查看Kingbase数据了,十分方便 ...
- DBeaver连接达梦|虚谷|人大金仓等国产数据库
前言 工作中有些项目可能会接触到「达梦.虚谷.人大金仓」等国产数据库,但通常这些数据库自带的连接工具使用并不方便,所以这篇文章记录一下 DBeaver 连接国产数据库的通用模版,下文以达梦为例(其他国 ...
- QT 之 ODBC连接人大金仓数据库
QT 之 使用 ODBC 驱动连接人大金仓数据库 获取数据库驱动和依赖动态库 此操作可在人大金仓官网下载与系统匹配的接口动态库,或者从架构数据库的源码中获取驱动和依赖动态库 分别为: 驱动动态库:kd ...
- 教你10分钟对接人大金仓EF Core 6.x
前言 目前.NET Core中据我了解到除了官方的EF Core外,还用的比较多的ORM框架(恕我孤陋寡闻哈,可能还有别的)有FreeSql.SqlSugar(排名不分先后).FreeSql和SqlS ...
- 通过jmeter连接人大金仓数据库
某项目用的人大金仓数据库,做性能测试,需要用jmeter来连接数据库处理一批数据.jmeter连接人大金仓,做个记录. 1. 概要 在"配置元件"中添加"JDBC Con ...
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
随机推荐
- 支付宝 v3 自签名如何实现
今天在看文档的时候,发现支付宝新出了一个 v3 版本的接口调用方式,感觉有点意思,花了点时间研究了下这个版本要怎么实现自签名,大家有兴趣可以看看. 什么是支付宝 API v3 版本? 官网上给的解释是 ...
- autMan奥特曼机器人-定时推送的用法
一.定时推送功能简介 "定时推送"位于"系统管理"目录 主要有两个功能: 一是定时向某人或某群发送信息. 二是定时运行某指令,就是机器人给自己发指令,让自己运行 ...
- 深入理解 Docker 容器技术
一.引言 在当今的云计算和软件开发领域,Docker 容器技术已经成为了一项不可或缺的工具.它极大地改变了应用程序的部署和运行方式,为开发者和运维人员带来了诸多便利. 二.Docker 容器是什么? ...
- gitlab - [01] 概述
gitlab! 一.GitLab是什么 GitLab是一个集成了Git仓库管理.持续集成(CI/CD).项目管理.代码审查.包管理和发布在内的全方位DevOps平台.它为软件开发团队提供了从项目规划到 ...
- 【Matlab】输出变量内容到xls文件
版本: matlab 2017a 功能:将矩阵输出一个excel文件 代码: function [ statu ] = write2xls( x,filename,sheet) % 返回值: % 1 ...
- Nginx: stat() failed (13: permission denied)
解决 server { listen [::]:80 default_server; # SSL configuration # # listen 443 ssl default_server; # ...
- PostgreSQL configure: error: readline library not found
前言 安装 PostgreSQL 时报错,以下 configure: error: readline library not found If you have readline already in ...
- Netty基础—7.Netty实现消息推送服务
大纲 1.Netty实现HTTP服务器 2.Netty实现WebSocket 3.Netty实现的消息推送系统 (1)基于WebSocket的消息推送系统说明 (2)消息推送系统的PushServer ...
- IvorySQL 4.4 发布
IvorySQL 4.4 已于 2025 年 3 月 10 日正式发布.新版本全面支持 PostgreSQL 17.4,新增多项新功能,并修复了已知问题. 增强功能 PostgreSQL 17.3 增 ...
- windows端5款mysql客户端工具
1. MySQL Workbench 这属于mysql官方出品,免费,功能强大,是首选. 2. HeidiSQL 免费,功能强大,强烈推荐. 3. dbForge Studio for MySQL 收 ...