AdaBoost算法的原理及Python实现
一、概述
AdaBoost(Adaptive Boosting,自适应提升)是一种迭代式的集成学习算法,通过不断调整样本权重,提升弱学习器性能,最终集成为一个强学习器。它继承了 Boosting 的基本思想和关键机制,但在具体的实现中有着显著特点,成为具有一定特定性能和适用场景的集成学习算法。
二、算法过程
(1)设置初始样本权重
在算法开始时,为训练数据集中的每一个样本设定一个相同的权重。如对于样本集\(D=\left\{ (x_1,y_1),(x_2,y_2),...,(x_n,y_n) \right\}\),初始权重为\(w^{(1)}=\left( w_{1}^{(1)} ,w_{2}^{(1)},...,w_{n}^{(1)} \right)\) ,其中\(w_{i}^{(1)}=\frac{1}{n}\),即在第一轮训练时,每个样本在模型训练中的重要度是相同的。
(2)训练弱学习器
基于当前的权重分布,训练一个弱学习器。基于当前的权重分布,训练一个弱学习器。弱学习器是指一个性能仅略优于随机猜测的学习算法,例如决策树桩(一种简单的决策树,通常只有一层)。在训练过程中,弱学习器会根据样本的权重来调整学习的重点,更关注那些权重较高的样本。
(3) 计算弱学习器的权重
根据弱学习器在训练集上的分类错误率,计算该弱学习器的权重。错误率越低,说明该弱学习器的性能越好,其权重也就越大;反之,错误率越高的弱学习器权重越小。通常使用的计算公式为
\]
其中\(\varepsilon\)是该弱学习器的错误率。
(4) 更新训练数据的权重分布
根据当前数据的权重和弱学习器的权重,更新训练数据的权重分布。具体的更新规则是,对于被正确分类的样本,降低其权重;对于被错误分类的样本,提高其权重。这样,在下一轮训练中,弱学习器会更加关注那些之前被错误分类的样本,从而有针对性地进行学习。公式为
\]
其中,\(w_{i}^{(t)}\)是第\(t\) 轮中第\(i\)个样本的权重,\(Z_t\)是归一化因子,确保更新后的样本权重之和为 1,\(h_t(x_i)\)是第\(t\)个弱学习器对第\(i\)个样本的预测结果。
(5) 重复以上步骤
不断重复训练弱学习器、计算弱学习器权重、更新数据权重分布的过程,直到达到预设的停止条件,如训练的弱学习器数量达到指定的上限,或者集成模型在验证集上的性能不再提升等。
(6)构建集成模型
将训练好的所有弱学习器按照其权重进行组合,得到最终的集成模型。如训练得到一系列弱学习器\(h_1,h_2,...,h_T\)及其对应的权重\(\alpha_1,\alpha_2,...,\alpha_T\),最终的强学习器\(H(X)\)通过对这些弱学习器进行加权组合得到。对于分类问题,通常采用符号函数\(H\left( X \right)=sign\left( \sum_{t=1}^{T}{\alpha_th_t(X)} \right)\)输出;对于回归问题,则可采用加权平均的方式输出。
过程图示如下
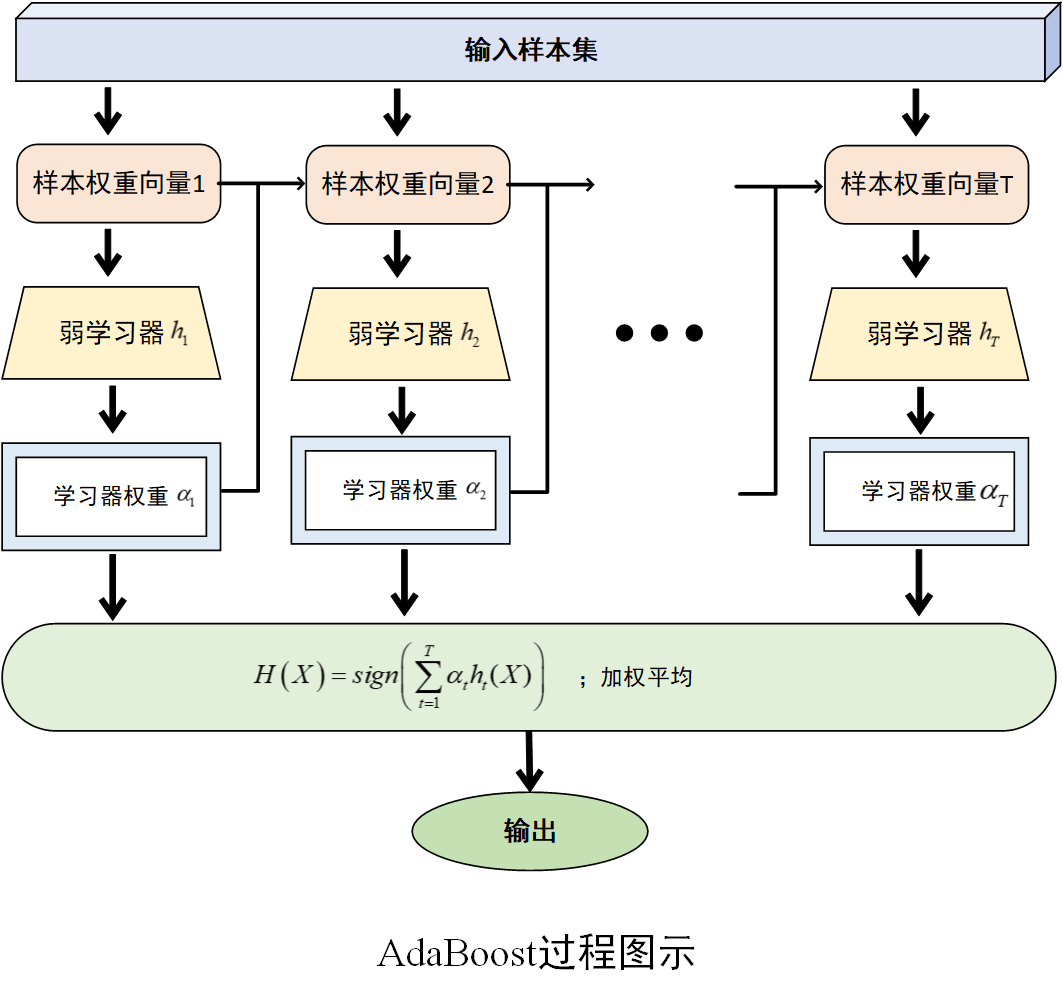
三、算法特性与应用场景
优势:算法通过不断调整样本权重和组合多个弱学习器,能够有效提高预测的准确性;可以自适应地调整样本的学习重点,对于不同分布的数据集有较好的适应性;对数据的分布没有严格的假设,不需要事先知道关于数据的一些先验知识。
不足:如果训练数据中存在噪声或异常值,可能会过度拟合这些数据,导致在测试集上的泛化能力下降;每次迭代都需要重新计算样本权重和训练弱分类器,当训练数据量较大或迭代次数较多时,计算成本较高。
应用场景:在图像识别、语音识别、目标检测、文本分类、生物信息等方面有着广泛的应用。
四、Python实现
(环境:Python 3.11,scikit-learn 1.6.1)
分类情形
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import accuracy_score
# 生成一个二分类的数据集
X, y = make_classification(n_samples=1000, n_features=10,
n_informative=5, n_redundant=0,
random_state=42,n_classes=2)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建AdaBoost分类器实例
ada_classifier = AdaBoostClassifier(n_estimators=100, learning_rate=0.1, random_state=42)
# 训练模型
ada_classifier.fit(X_train, y_train)
# 进行预测
y_pred = ada_classifier.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")

回归情形
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostRegressor
from sklearn.metrics import mean_squared_error
# 生成模拟回归数据
X, y = make_regression(n_samples=1000, n_features=10, n_informative=5, noise=0.5, random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建 AdaBoost 回归器
ada_reg = AdaBoostRegressor(n_estimators=100, random_state=42)
# 训练模型
ada_reg.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = ada_reg.predict(X_test)
# 计算均方误差评估模型性能
mse = mean_squared_error(y_test, y_pred)
print(f"均方误差: {mse}")

End.
AdaBoost算法的原理及Python实现的更多相关文章
- Adaboost 算法的原理与推导——转载及修改完善
<Adaboost算法的原理与推导>一文为他人所写,原文链接: http://blog.csdn.net/v_july_v/article/details/40718799 另外此文大部分 ...
- [转]Adaboost 算法的原理与推导
看了很多篇解释关于Adaboost的博文,觉得这篇写得很好,因此转载来自己的博客中,以便学习和查阅. 原文地址:<Adaboost 算法的原理与推导>,主要内容可分为三块,Adaboost ...
- 模拟退火算法SA原理及python、java、php、c++语言代码实现TSP旅行商问题,智能优化算法,随机寻优算法,全局最短路径
模拟退火算法SA原理及python.java.php.c++语言代码实现TSP旅行商问题,智能优化算法,随机寻优算法,全局最短路径 模拟退火算法(Simulated Annealing,SA)最早的思 ...
- Adaboost 算法的原理与推导
0 引言 一直想写Adaboost来着,但迟迟未能动笔.其算法思想虽然简单“听取多人意见,最后综合决策”,但一般书上对其算法的流程描述实在是过于晦涩.昨日11月1日下午,邹博在我组织的机器学习班第8次 ...
- BP算法从原理到python实现
BP算法从原理到实践 反向传播算法Backpropagation的python实现 觉得有用的话,欢迎一起讨论相互学习~Follow Me 博主接触深度学习已经一段时间,近期在与别人进行讨论时,发现自 ...
- AdaBoost算法详解与python实现
1. 概述 1.1 集成学习 目前存在各种各样的机器学习算法,例如SVM.决策树.感知机等等.但是实际应用中,或者说在打比赛时,成绩较好的队伍几乎都用了集成学习(ensemble learning)的 ...
- 神经网络中 BP 算法的原理与 Python 实现源码解析
最近这段时间系统性的学习了 BP 算法后写下了这篇学习笔记,因为能力有限,若有明显错误,还请指正. 什么是梯度下降和链式求导法则 假设我们有一个函数 J(w),如下图所示. 梯度下降示意图 现在,我们 ...
- Apriori算法的原理与python 实现。
前言:这是一个老故事, 但每次看总是能从中想到点什么.在一家超市里,有一个有趣的现象:尿布和啤酒赫然摆在一起出售.但是这个奇怪的举措却使尿布和啤酒的销量双双增加了.这不是一个笑话,而是发生在美国沃尔玛 ...
- Adaboost算法结合Haar-like特征
Adaboost算法结合Haar-like特征 一.Haar-like特征 目前通常使用的Haar-like特征主要包括Paul Viola和Michal Jones在人脸检测中使用的由Papageo ...
- 基于单层决策树的AdaBoost算法原理+python实现
这里整理一下实验课实现的基于单层决策树的弱分类器的AdaBoost算法. 由于是初学,实验课在找资料的时候看到别人的代码中有太多英文的缩写,不容易看懂,而且还要同时看代码实现的细节.算法的原理什么的, ...
随机推荐
- 2021 OWASP TOP 10
OWASP TOP 10 2021年版Top 10有哪些变化? 2021年版Top 10产生了三个新类别,原有四个类别的命名和范围也发生了变化,且进行了一些 整合. 2017年 TOP 10 top ...
- Ansible之二playbook
反星系 连接https://galaxy.ansible.com下载相应的roles 列出所有安装的 galaxy ansible-galaxy list 安装galaxy ansibl ...
- 小程序开发实战案例五 | 小程序如何嵌入H5页面
在接入小程序过程中会遇到需要将 H5 页面集成到小程序中情况,今天我们就来聊一聊怎么把 H5 页面塞到小程序中. 本篇文章将会从下面这几个方面来介绍: 小程序承载页面的前期准备 小程序如何承载 H5 ...
- [JSOI2008]火星人 题解
原题链接:\(luogu\)$\ \ $ \(BZOJ\)$\ \ $ \(LOJ\) 题目大意:有一个可以支持插入和修改的字符串,定义函数 \(\operatorname{LCQ(x,y)}\) 表 ...
- QT5笔记: 32. QPainter 基本绘制
- MySQL - [09] 正则表达式
转载:https://mp.weixin.qq.com/s/7RavuYGs9SthX2pxGJppqw select * from t1 where name rlike '^[a-zA-Z]+$' ...
- 面试题55 - II. 平衡二叉树
地址:https://leetcode-cn.com/problems/ping-heng-er-cha-shu-lcof/ <?php /** 输入一棵二叉树的根节点,判断该树是不是平衡二叉树 ...
- PHP中处理html相关函数集锦
1.html_entity_decode() 函数把 HTML 实体转换为字符. Html_entity_decode() 是 htmlentities() 的反函数. 例子: <?Php $s ...
- [tldr] vscode的remote插件的config文件内容解析
参考VS Code Remote SSH配置 解决了什么问题 vscode的remote插件可以直接通过可视化的UI新建一个连接 通过ssh指令添加服务器的连接方式 但是这种方式添加的服务器名字等于服 ...
- 当你在浏览器中输入 google.com 后按下回车发生了什么?
按下"g"键 接下来的内容介绍了物理键盘和系统中断的工作原理,但是有一部分内容却没有涉及.当你按下"g"键,浏览器接收到这个消息之后,会触发自动完成机制.浏览器 ...