flink 1.11.2 学习笔记(5)-处理消息延时/乱序的三种机制
在实时数据处理的场景中,数据的到达延时或乱序是经常遇到的问题,比如:
* 按时间顺序发生的数据1 -> 2,本来应该是1先发送,1先到达,但是在1发送过程中,因为网络延时之类的原因,导致1反而到达晚了,变成2先到达,也就造成所谓的接收乱序;
* 发送方本身就延时了,比如:事实上按1 -> 2产生的数据 ,发送方如果是多线程发送数据,可能造成2先发,1后发,中间网络传输就算没有延时,也会导致接收到时已经乱序;
* 有一些比如本来是19:59:59发生的业务数据,由于一些中间环节耗时(比如:最长可能需要5秒),到了发送的时候,已经是20:00:04了,但是在处理时,又希望这条数据能算到上1个小时的统计窗口里(即:数据虽然晚到了,已经错过了上1个时间窗口的计算时机,但是不希望被扔掉)
flink做为一个流批一体的框架,自然也考虑到这个问题,它提供了3种机制来应对,还是以最经典的wordcount为例,先定义WordCount类:
package com.cnblogs.yjmyzz.flink.demo; import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor; import java.util.Date; @Data
@AllArgsConstructor
@NoArgsConstructor
public class WordCount { private String word; private Date eventDateTime; }
为了后面json序列化方便,定义一个Gson工具类(可参考)
package com.cnblogs.yjmyzz.flink.demo; import com.google.gson.Gson;
import com.google.gson.GsonBuilder;
import com.google.gson.JsonDeserializer;
import com.google.gson.JsonPrimitive; import java.text.SimpleDateFormat;
import java.util.Date; /**
* @author jimmy
*/
public enum GsonUtils { INSTANCE; private static Gson gson; public Gson gson() {
if (gson != null) {
return gson;
}
String dateFormatWithMS = "yyyy-MM-dd HH:mm:ss.SSS";
String dateFormatNoMS = "yyyy-MM-dd HH:mm:ss";
GsonBuilder builder = new GsonBuilder();
builder.registerTypeAdapter(Date.class, (JsonDeserializer<Date>) (json, typeOfT, context) -> {
if (json == null || json.toString().equalsIgnoreCase("\"\"")) {
//空字符判断
return null;
}
JsonPrimitive jsonPrimitive = json.getAsJsonPrimitive();
SimpleDateFormat sdfMS = new SimpleDateFormat(dateFormatWithMS);
SimpleDateFormat sdfNoMS = new SimpleDateFormat(dateFormatNoMS);
Date dt = null;
try {
if (jsonPrimitive.isString()) {
if (jsonPrimitive.getAsString().length() == 19) {
//这里只是示例,简单用长度来判断是哪种格式
//yyyy-MM-dd HH:mm:ss格式
dt = sdfNoMS.parse(json.getAsString());
} else {
//yyyy-MM-dd HH:mm:ss.SSS格式
dt = sdfMS.parse(json.getAsString());
}
} else if (jsonPrimitive.isNumber()) { //兼容timestamp类型
dt = new Date(jsonPrimitive.getAsLong());
}
} catch (Exception e) {
//错误日志记录,略
e.printStackTrace();
}
return dt;
});
gson = builder
.setDateFormat(dateFormatWithMS)
.setPrettyPrinting()
.create();
return gson;
}
}
开始flink处理,我们的场景是先启动一个nc模拟网络服务端发送数据,然后flink实时接收,然后按1分钟做为时间窗口,统计窗口内收到的word个数。
发送的数据格式类似:
{"word":"hello","eventDateTime":"2021-05-09 22:01:10.000"}
代码如下:
package com.cnblogs.yjmyzz.flink.demo; import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.api.java.typeutils.TupleTypeInfo;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow; import java.text.SimpleDateFormat;
import java.util.Date; public class WorkCountSample { public static void main(String[] args) throws Exception { SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS"); // 1 设置环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment
.getExecutionEnvironment()
.setParallelism(1); //指定使用eventTime作为时间标准
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); SingleOutputStreamOperator<Tuple3<String, Integer, String>> count = env
.socketTextStream("127.0.0.1", 9999)
.map((MapFunction<String, WordCount>) value -> {
//将接收到的json转换成WordCount对象
WordCount wordCount = GsonUtils.INSTANCE.gson().fromJson(value, WordCount.class);
return wordCount;
})
//这里先不指定任何水印延时
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<WordCount>(Time.milliseconds(0)) {
@Override
public long extractTimestamp(WordCount element) {
//指定事件时间的字段
return element.getEventDateTime().getTime();
}
})
.flatMap((FlatMapFunction<WordCount, Tuple3<String, Integer, String>>) (value, out) -> {
String word = value.getWord();
//辅助输出窗口信息,方便调试
String windowTime = sdf.format(new Date(TimeWindow.getWindowStartWithOffset(value.getEventDateTime().getTime(), 0, 60 * 1000)));
if (word != null && word.trim().length() > 0) {
out.collect(new Tuple3<>(word.trim(), 1, windowTime));
}
})
.returns(((TypeInformation) TupleTypeInfo.getBasicTupleTypeInfo(String.class, Integer.class, String.class)))
.keyBy(0)
//按每分钟开窗
.timeWindow(Time.minutes(1))
.sum(1); count.print(); env.execute("wordCount"); }
}
来测试一下,先启用1个网络服务端,mac或linux上,终端输入 nc -l 9999,再启用上面的flink程序,在终端依次输入下面3条json(即:模拟发送了3条数据)
{"word":"hello","eventDateTime":"2021-05-09 22:01:10.000"}
{"word":"hello","eventDateTime":"2021-05-09 22:01:00.999"}
{"word":"hello","eventDateTime":"2021-05-09 22:02:00.000"}
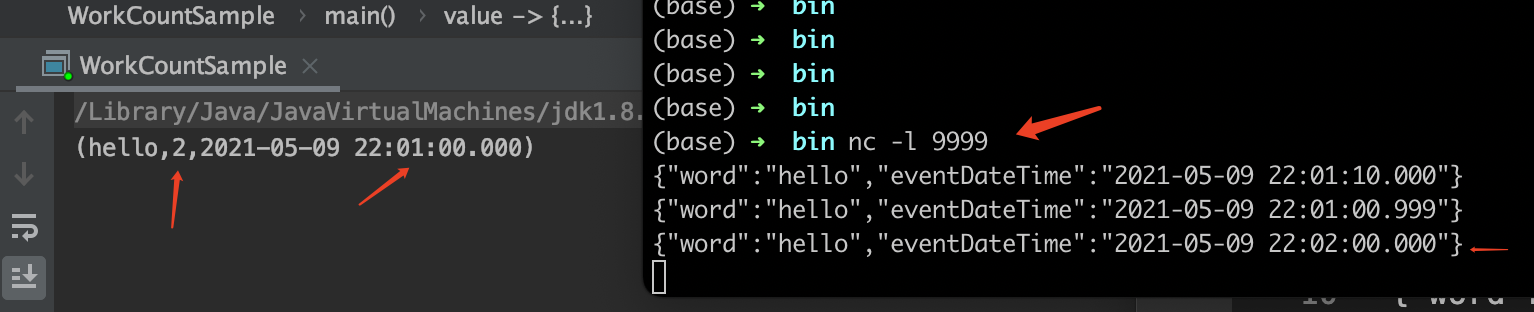
可以看到,在输入到第3条时,因为事件时间已经到了第2分钟,所以上1分钟的窗口被关闭,触发了计算,输出了hello:2,符合预期。
注意一下:第1条与第2条的事件时间,正好的是反的,第1条是22:01:10,而第2条是更早的22:01:00,也就是乱序,但是仍然都正确的统计在了22:01:00这个1分钟的窗口里。所以按时间开窗的场景,flink天然就能兼容一些乱序情况。
如果是延时问题,比如希望延时1秒才开始触发上1个时间窗口的计算,即: 22:02.00.999 的事件时间数据到达时,才开始计算22:01:00 开始的这个1分钟窗口(相当于多等1秒),可以调整第40行代码,即所谓的水印WaterMark机制
一、Watermark延时设置
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<WordCount>(Time.milliseconds(1000))
很简单对吧?只要把40行这里的0,调整成1000,也就是延时1000ms触发计算,注:这是一个左闭右开的区间,即[0,1000)的延时范围都是允许的。
再测试一下:
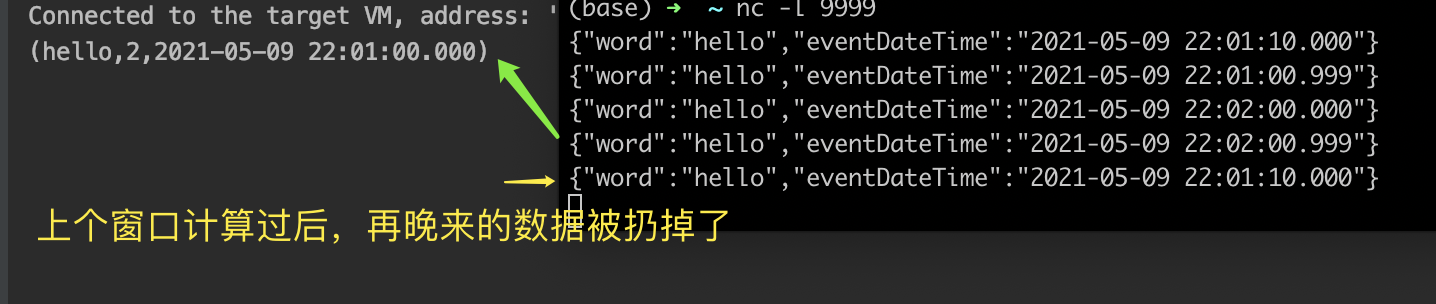
可以看到,当输入第3条数据时,虽然已经是22:02:00.000,到了第2分钟,但是并没有触发前1个时间窗口的计算输出,而是在第4条数据输入,也就是22:02.00.999时才触发22:01 窗口的计算,以此之后,哪怕再有01分窗口的数据上报,将被扔掉。
二、时间窗口延时设置
在刚才示例中,如果某个窗口计算过了(也就是窗口关闭了),后面哪怕还有该窗口内的数据上报,默认也会被丢失。这好比:公司组织团建,约好第2天早上8点发车(即:时间窗口的截止时间为8点),然后考虑到可能有人会迟到(即: 数据延时上报),会让司机多等5分钟(即:watermark的延时),但是过了08:05,如果还有人没来,就不管了,这个好象有点不厚道。怎么办?通常公司会说,现在我们先点下人数(即:窗口先计算1次),如果还有人没到,我们最后再多等10分钟(即:这10分钟内,如果还有人再来,每来1个人,再清点1次,看看人有没有到齐,如果到了08:15还没到齐,就只能发车了,不让让全公司的人等个别懒虫)。
这就是flink的第2种处理延时机制,窗口延时计算,只要加一行allowLateness就好。
.timeWindow(Time.minutes(1))
.allowedLateness(Time.seconds(10))
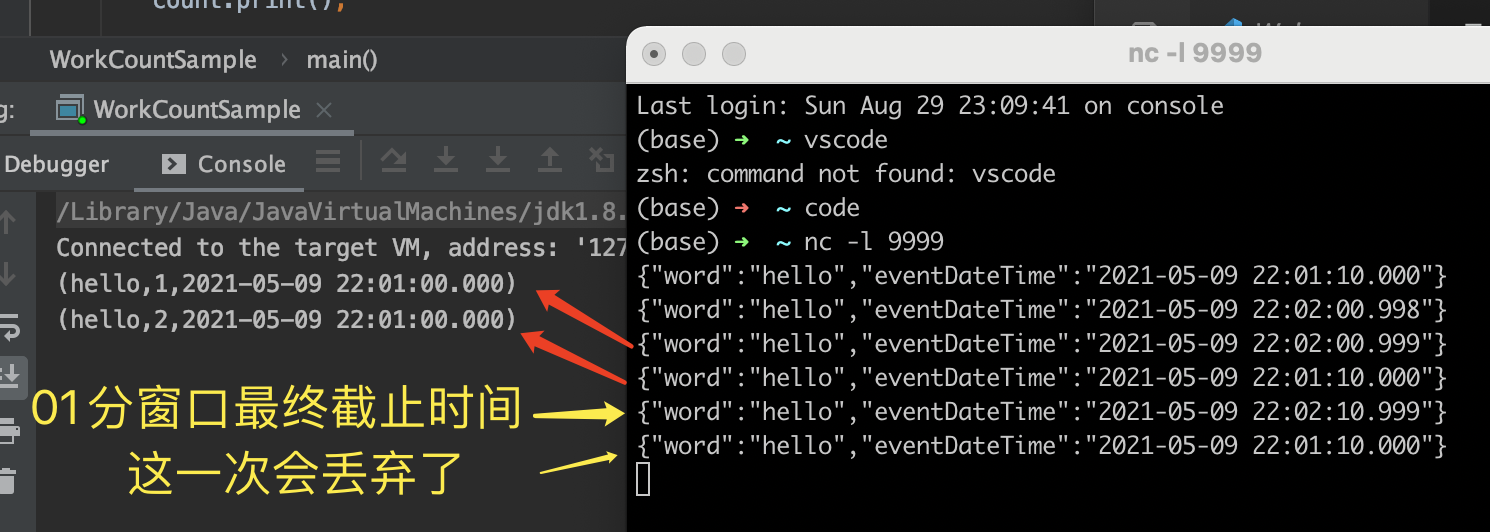
观察上面的运行结果 ,第3次输入时,触发了窗口的第1次计算,紧接着第4条输入,仍然是01分窗口的数据(相当于迟到赶来的人),又触发了1次计算,但是到了第5条,也就是第1个黄色箭头的数据到达时,已经到了最后截止时间,窗口彻底关闭(即:发车了),后面再有数据过来,也不管了。
三、迟到数据的侧输出流
还是以上面的公司团建发车为例,如果有些人真的有事情,来不及,但是又想去团建怎么办?(即:肯定是迟到了,但是数据不能丢)一般的做法,我们是让他自行打车,单独前往。这在Flink里,叫做所谓“侧输出流”,把迟到的数据单独放在一个Stream里收集起来,然后单独处理。
package com.cnblogs.yjmyzz.flink.demo; import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.api.java.typeutils.TupleTypeInfo;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.OutputTag; import java.text.SimpleDateFormat;
import java.util.Date; public class WorkCountSample { public static void main(String[] args) throws Exception { SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS"); // 1 设置环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment
.getExecutionEnvironment()
.setParallelism(1); //指定使用eventTime作为时间标准
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); OutputTag<Tuple3<String, Integer, String>> lateTag = new OutputTag<>("late", ((TypeInformation) TupleTypeInfo.getBasicTupleTypeInfo(String.class, Integer.class, String.class))); SingleOutputStreamOperator<Tuple3<String, Integer, String>> count = env
.socketTextStream("127.0.0.1", 9999)
.map((MapFunction<String, WordCount>) value -> {
//将接收到的json转换成WordCount对象
WordCount wordCount = GsonUtils.INSTANCE.gson().fromJson(value, WordCount.class);
return wordCount;
})
//这里先不指定任何水印延时
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<WordCount>(Time.milliseconds(1000)) {
@Override
public long extractTimestamp(WordCount element) {
//指定事件时间的字段
return element.getEventDateTime().getTime();
}
})
.flatMap((FlatMapFunction<WordCount, Tuple3<String, Integer, String>>) (value, out) -> {
String word = value.getWord();
//辅助输出窗口信息,方便调试
String windowTime = sdf.format(new Date(TimeWindow.getWindowStartWithOffset(value.getEventDateTime().getTime(), 0, 60 * 1000)));
if (word != null && word.trim().length() > 0) {
out.collect(new Tuple3<>(word.trim(), 1, windowTime));
}
})
.returns(((TypeInformation) TupleTypeInfo.getBasicTupleTypeInfo(String.class, Integer.class, String.class)))
.keyBy(0)
//按每分钟开窗
.timeWindow(Time.minutes(1))
.allowedLateness(Time.seconds(10))
//定义迟到数据的侧输出流
.sideOutputLateData(lateTag)
.sum(1); count.print(); //迟到的数据,这时只是简单的打印出来
count.getSideOutput(lateTag).print(); env.execute("wordCount"); }
}
33行,先定义一个OutputTag
64行,通过sideOutputLateData(lateTag)指定侧输出流,将迟到的数据收集于此
71行,将收集到的测输出流,打印出来(实际业务中,可以存到mysql等一些存储体系中)
运行效果:
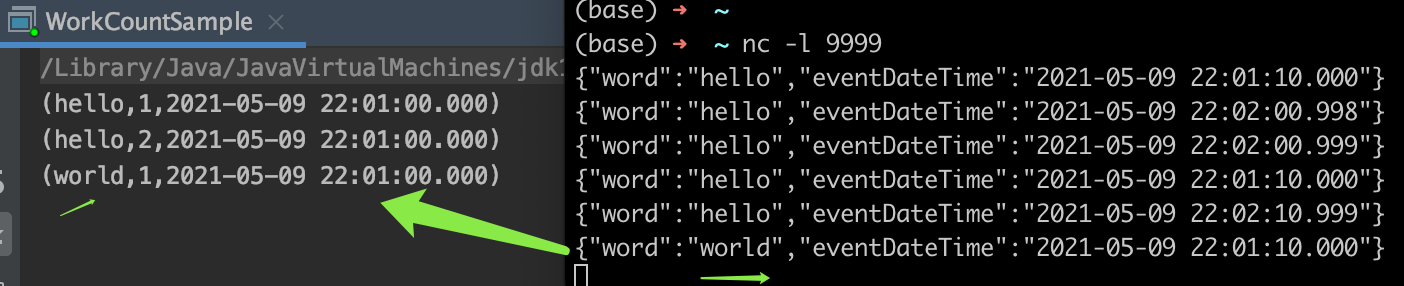
注:
右侧倒数第2条{"word":"hello","eventDateTime":"2021-05-09 22:02:10.999"}发送完毕后,01分的窗口已关闭。
再发送最后1条{"word":"world","eventDateTime":"2021-05-09 22:01:10.000"}时,这条就是迟到数据了,从左侧输出来看,已正确输出,被侧输出流处理了。
小结一下:
1、Watermark水印在窗口计算触发前延时;
2、allowedLateness则是只要窗口计算时机被触发了,把现有数据先算一把,后面如果还有该窗口的数据过来,可以继续再算(前提是在允许的延时阈值范围内)
3、如果上述2种延时都满足不了,在窗口彻底关闭了后,还有迟到数据进来,可以放到侧输出流,单独处理。
flink 1.11.2 学习笔记(5)-处理消息延时/乱序的三种机制的更多相关文章
- C语言学习笔记 (006) - 二维数组传参的三种表现形式
# include <stdio.h> # include <stdlib.h> # define M # define N int getdate(int (*sp)[M]) ...
- Swift 学习笔记 (解决Swift闭包中循环引用的三种方法)
话不多说 直接上代码 class SmartAirConditioner { var temperature:Int = //类引用了函数 var temperatureChange:((Int)-& ...
- 学习笔记 - 快速傅里叶变换 / 大数A * B的另一种解法
转: 学习笔记 - 快速傅里叶变换 / 大数A * B的另一种解法 文章目录 前言 ~~Fast Fast TLE~~ 一.FFT是什么? 二.FFT可以干什么? 1.多项式乘法 2.大数乘法 三.F ...
- ios网络学习------4 UIWebView的加载本地数据的三种方式
ios网络学习------4 UIWebView的加载本地数据的三种方式 分类: IOS2014-06-27 12:56 959人阅读 评论(0) 收藏 举报 UIWebView是IOS内置的浏览器, ...
- Linux(10.5-10.11)学习笔记
3.2程序编码 unix> gcc -01 -o p p1.c p2.c -o用于指定输出(out)文件名. -01,-02 告诉编译器使用第一级或第二级优化 3.2.1机器级代码 机器级编程两 ...
- 1-1 maven 学习笔记(1-6章)
一.基础概念 1.Maven作为Apache组织中颇为成功的开源项目,主要服务于基于Java平台的项目构建,依赖管理和项目信息管理.从清理,编译,测试到生成报告,到打包部署,自动化构建过程. 还可以跨 ...
- c++11多线程学习笔记之一 thread基础使用
没啥好讲的 c++11 thread类的基本使用 #include "stdafx.h" #include <iostream> #include <thre ...
- mybatis学习笔记(四)-- 为实体类定义别名两种方法(基于xml映射)
下面示例在mybatis学习笔记(二)-- 使用mybatisUtil工具类体验基于xml和注解实现 Demo的基础上进行优化 以新增一个用户为例子,原UserMapper.xml配置如下: < ...
- AMQ学习笔记 - 06. 可靠消息传送
概述 本文介绍JMS中可能发生消息故障的3个隐患阶段,以及确保消息安全的3种保障机制. 故障分析 在介绍可靠传送的确保机制之前,先分析消息在传送的过程中可能在哪个阶段出现问题. 1.两个跃点 跃点的含 ...
- Flink 实践教程-进阶(5):排序(乱序调整)
作者:腾讯云流计算 Oceanus 团队 流计算 Oceanus 简介 流计算 Oceanus 是大数据产品生态体系的实时化分析利器,是基于 Apache Flink 构建的具备一站开发.无缝连接.亚 ...
随机推荐
- toRefs 与 toRef 的详解
一.引言在 Vue 3 的响应式系统里,toRefs 和 toRef 是两个实用的工具函数,它们在处理响应式数据时发挥着重要作用.合理运用这两个函数,可以让我们在操作响应式对象和数组时更加灵活,避免一 ...
- Spring中的依赖注入DI
目录 Spring中的依赖注入DI Spring中的依赖注入DI 依赖注入的简单理解就是给对象设置变量值. Spring配置文件 <?xml version="1.0" en ...
- IDEA问题之“接口路径查询插件【RestfulToolkit】”
一.场景 只查询Java代码中的路径,这样就可以快速的找到对应的接口 快捷键:Ctrl + \ 二.安装步骤
- 在 .NET 中使用 Sqids 快速的为数字 ID 披上神秘短串,轻松隐藏敏感数字!
前言 在当今数字化时代,数据的安全性和隐私性至关重要.随着网络应用的不断发展,数字 ID 作为数据标识和访问控制的关键元素,其保护显得尤为重要.然而,传统的数字 ID 往往直接暴露了一些敏感信息,如顺 ...
- vue3 基础-Pinia 可能替代 Vuex 的全局数据状态管理
Pinia 初体验 Pinia.js是由Vue.js团队核心成员开发的新一代状态管理器,使用Composition Api进行重新设计的,也被视为下一代Vuex. Pinia是一个Vue的状态管理库, ...
- C# Environment.CurrentDirectory和AppDomain.CurrentDomain.BaseDirectory的区别
Environment.CurrentDirectory 和 AppDomain.CurrentDomain.BaseDirectory 都是C#中用于获取当前应用程序的目录路径的方法,但是它们的用途 ...
- GLSL的预处理器都有哪些规定?
GLSL的预处理器都有哪些规定? 下面的内容,英文版取自GLSLangSpec.4.60.pdf,中文版是我的翻译,只求意译准确易懂,不求直译严格匹配. 3.3. Preprocessor There ...
- Java catch多重异常捕获
摘要:Java中多重异常捕获机制可以更加简洁.有效地处理多个异常,提高了程序的鲁棒性,是编写高质量代码的重要技巧之一. 小编在<浅谈Java异常处理机制>中梳理了异常处理机制,在< ...
- Visio画图心得
关于Visio画图时的心得 1.关于对齐 我之前常常是在visio中视图里打开网格,然后根据网格来对齐框框,但是其实网格旁边的参考线用于对齐更好用. 首先,打开在视图选项卡里勾上参考线. 然后因为要根 ...
- 由MySQL的Explain 看闭环 看交付
今天在业务上有一个列表页的需求,列表页需要进行统计记录的求和情况,也就是需要用到sum语句.如: 自己在date_time 上面加了索引,那么我们对a字段求和的时候是否会使用到索引呢? select ...