探秘 MySQL 索引底层原理,解锁数据库优化的关键密码(下)
上两篇文章《探秘MySQL索引底层原理,解锁数据库优化的关键密码(上)》和《探秘 MySQL 索引底层原理,解锁数据库优化的关键密码(中)》主要讲了MySQL索引的底层原理,且对比了B+Tree作为索引底层数据结构相对于其他数据结构(二叉树、红黑树、B树)的优势,最后还通过图示的方式描述了索引的存储结构。
但之前都是基于单值索引,由于文章篇幅原因也只是在文末略提了一下联合索引,并没有大篇幅的展开讨论,所以这篇文章就单独去讲一下联合索引在B+树上的存储结构。
本文主要讲解的内容有:
- 联合索引在B+树上的存储结构
- 联合索引的查找方式
- 为什么会有最左前缀匹配原则?
- 实战
在分享这篇文章之前,我在网上查了关于MySQL联合索引在B+树上的存储结构这个问题,翻阅了很多博客和技术文章,其中有几篇讲述的与事实相悖。庆幸的是看到搜索引擎列出的有一条是来自思否社区的问答,有答主回答了这个问题,贴出一篇文章和一张图以及一句简单的描述。PS:贴出的文章链接已经打不开了。
所以在这样的条件下这篇文章就诞生了。
联合索引的存储结构
下面就引用思否社区的这个问答来展开我们今天要讨论的联合索引的存储结构的问题。
来自思否的提问,联合索引的存储结构(https://segmentfault.com/q/1010000017579884)有码友回答如下:
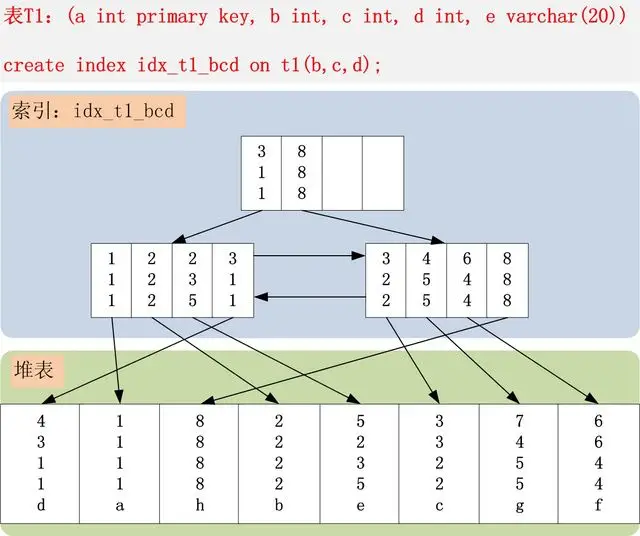
联合索引 bcd , 在索引树中的样子如图 , 在比较的过程中 ,先判断 b 再判断 c 然后是 d
由于回答只有一张图一句话,可能会让你有点看不懂,所以我们就借助前人的肩膀用这个例子来更加细致的讲探寻一下联合索引在B+树上的存储结构吧。
首先,表T1有字段a,b,c,d,e,其中a是主键,除e为varchar其余为int类型,并创建了一个联合索引idx_t1_bcd(b,c,d)。上图树高只有两层不容易理解,下面是假设的表数据以及我对其联合索引在B+树上的结构图的改进。PS:基于InnoDB存储引擎。
假设T1表有如下数据:
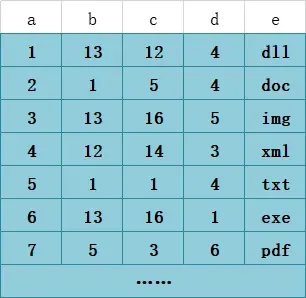
T1表
那么基于联合索引(b、c、d)构建的B+树大致如下图所示(拿根节点的第一个来说,1 1 4即是b=1,c=1,d=4)
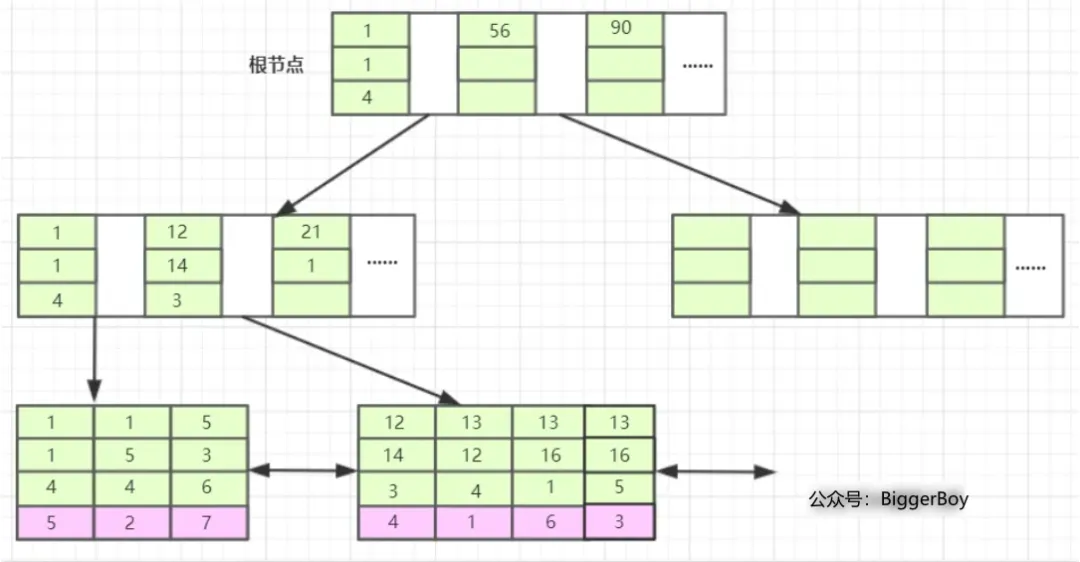
bcd联合索引在B+树上的结构图
通过这两张图我们脑海里对联合索引在B+树上的存储结构应该就有了个大概的认识。
我们先看T1表,它的主键a我们暂且将它设为整型自增的(PS:至于为什么是整型自增上两篇文章有详细介绍这里不再赘述),InnoDB会使用主键索引在B+树维护索引和数据文件,然后我们创建了一个联合索引(b,c,d)也会生成一个索引树,同样也是B+树的结构,只不过它的叶子节点data部分存储的是联合索引所在行的主键值(上图叶子节点紫色背景部分),至于为什么辅助索引data部分存储主键值上篇文章也有介绍,感兴趣或还没看的可以去看一下。
好了大致情况都介绍完了,下面我们结合这两张图来解释一下。
与单列索引相比,联合索引只不过比其多了几列,而且这些索引列全部都出现在索引树上。对于联合索引,存储引擎首先会根据第一个索引列排序,如上图我们可以看B+树的最后一层,单看第一个索引列,即叶子节点的第一行1、1、5、12、13、13、13显然是趋势递增的。即:如果第一列相等则再根据第二列排序,依此类推就构成了上图的索引树。
另外,我们看,第二行和第三行,即联合索引的c列和d列,分别是1、5、3、14、12、16、16和4、4、6、3、4、1、5,这里就又没有了趋势递增。而在b列相同时,c列才会趋势递增,如b=1时的1、5,b=13时的12、16、16,同理c列相同时,d列才会趋势递增。这也就是为什么要遵循最左前缀原则。
小结
基于B+树的多列键值组织
联合索引将多个字段组合成一个键值,按照字段定义的顺序构建B+树。例如,联合索引(b, c, d)的每个节点中,键值按b→c→d的顺序排列:
- 非叶子节点:存储所有字段的键值(如b, c, d的组合)及指向子节点的指针。
- 叶子节点:存储完整的联合索引键值(b, c, d)和对应的主键值(用于回表查询)。
排序规则
- 全局有序性:所有节点按第一列(最左列)排序,若第一列值相同,则按第二列排序,依此类推。例如,(b=1, c=2)会排在(b=1, c=3)之前
- 局部有序性:同一层级内,每个节点存储的键值按顺序排列,支持快速范围查询。
物理存储优化
- B+树的非叶子节点不存储实际数据,仅存储键值和指针,单个磁盘页(如16KB)可容纳更多键值,减少树的高度(通常3-4层即可支持千万级数据)。
- 叶子节点通过双向链表连接,便于范围遍历。
联合索引的查找方式
精确匹配查询
- 最左前缀匹配原则:查询条件必须从联合索引的最左列开始。例如,索引
(b, c, d)的查询: - 有效条件:
WHERE b=1、WHERE b=1 AND c=2、WHERE b=1 AND c=2 AND d=3。 - 失效条件:
WHERE c=2、WHERE d=3(因无法利用全局有序性。 - 查询优化器调整:即使条件顺序与索引不同(如
WHERE c=2 AND b=1),优化器会自动调整为b=1 AND c=2以匹配索引 。
范围查询
- 范围查询(如 b>10 )会利用索引,但后续字段无法继续匹配。例如,
WHERE b>10 AND c=2中,只有 b>10 走索引, c=2 需在结果集中过滤 。 - 范围查询后的字段索引失效(如
WHERE b=1 AND c>2 AND d=3, d 无法使用索引)。
覆盖索引与回表
- 覆盖索引:若查询字段全部在联合索引中(如
SELECT a, b FROM T1),无需回表,直接从叶子节点获取数据。 - 回表查询:若需获取非索引字段(如
SELECT *),需通过叶子节点的主键值回聚簇索引获取完整数据
下面咱们一起来详细看一下精确匹配查询过程。
当我们的SQL可以应用到索引的时候,比如 select * from T1 where b = 12 and c = 14 and d = 3 也就是T1表中a列为4的这条记录。
存储引擎首先从根节点(一般常驻内存)开始查找,第一个索引的第一个索引列为1,由于12大于1,第二个索引的第一个索引列为56,又因12小于56,所以从这俩索引的中间读到下一个节点的磁盘文件地址,从磁盘上加载这个节点,通常伴随一次磁盘IO,然后在内存里去查找。当加载叶子节点的第二个节点时又是一次磁盘IO,从该节点的第一个元素开始匹配,b=12,c=14,d=3完全符合。由于咱们Select *,所以还需要拿到该索引下的data元素即ID值,再从主键索引树上找到最终数据(回表)。
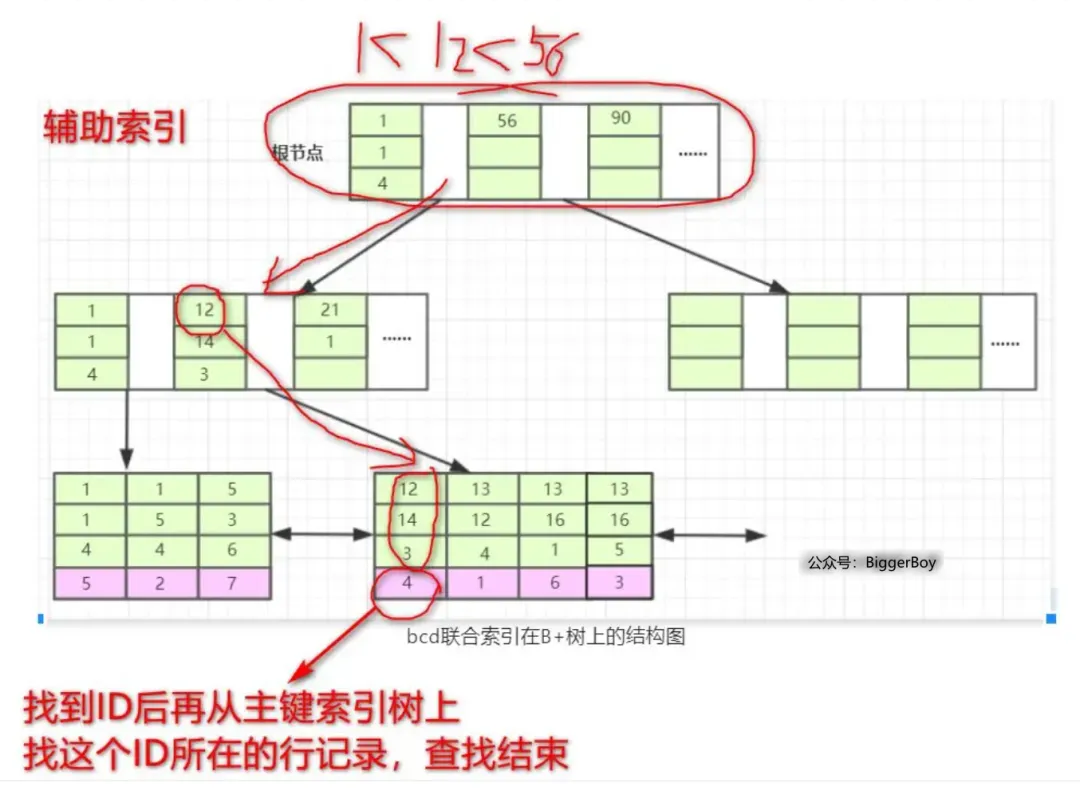
而如果Select后只有a,那么要查询的列就都存在于这颗联合索引的B+树上,此时无需回表,这即是覆盖索引。
最左前缀匹配原则
之所以会有最左前缀匹配原则,其实和联合索引的索引构建方式及存储结构是密不可分的。
首先我们创建的idx_t1_bcd(b,c,d)索引,相当于创建了(b)、(b、c)、(b、c、d)三个索引,下面将会详细解析。
联合索引将多个字段组合成一个键值,按照字段定义的顺序构建B+树。
上面idx_t1_bcd(b,c,d)的例子就是优先使用b列构建,当b列值相等时再以c列排序,若c列的值也相等则以d列排序。我们可以取出索引树的叶子节点看一下。

索引的第一列也就是b列是从左到右趋势递增的,但我们看第二行c列和第三行d列并没有这个特性。仔细观察发现c列只能在b列值相等的情况下小范围内递增,如第一叶子节点的第1、2个元素和第二个叶子节点的后三个元素。d列亦是如此,它只能在c列值相等时递增。
由于联合索引是上述那样的索引构建方式及存储结构,所以联合索引只能从多列索引的第一列开始查找。所以如果你的查找条件不包含b列如(c,d)、(c)、(d)是无法应用索引的,以及跨列也是无法完全用到索引,如(b,d),只会用到b列索引。
这就像我们的电话本一样,有名和姓以及电话,名和姓就是联合索引。首先以姓的首字母排序,姓的首字母相同的情况下,再以名的首字母排序。
如:
M
毛 不易 178********
马 化腾 183********
马 云 188********
Z
张 杰 189********
张 靓颖 138********
张 艺兴 176******** 我们知道名和姓是很快就能够从姓的首字母索引定位到姓,然后定位到名,进而找到电话号码,因为所有的姓从上到下按照既定的规则(首字母排序)是有序的,而名是在姓的首字母一定的条件下也是按照名的首字母排序的,但是整体来看,所有的名放在一起是无序的,所以如果只知道名查找起来就比较慢,因为无法用已排好的结构快速查找。
到这里大家是否明白了为啥会有最左前缀匹配原则了吧。
设计优化建议
- 列顺序选择
- 高频查询条件列放在最左,区分度高的列优先 。例如,若 WHERE a=1 AND b=2 更常见,则索引应为 (a, b) 而非 (b, a) 。
- 避免冗余列
- 联合索引的字段应精简,避免包含低区分度或重复功能的列 。
- 索引下推(Index Condition Pushdown)
- MySQL 5.6+支持将WHERE条件中可通过索引过滤的部分下推到存储引擎层,减少回表次数。
关于索引设计优化之前的文章有更详细的介绍,请看文末文章链接。
实践
如下列举一些SQL的索引使用情况
select * from T1 where b =12 and c =14 and d =3;-- 全值索引匹配 三列都用到
select * from T1 where b =12 and c =14 and e ='xml';-- 应用到两列索引
select * from T1 where b =12 and e ='xml';-- 应用到一列索引
select * from T1 where b =12 and c >=14 and e ='xml';-- 应用到一列索引及索引条件下推优化
select * from T1 where b =12 and d =3;-- 应用到一列索引 因为不能跨列使用索引 没有c列 连不上
select * from T1 where c =14 and d =3;-- 无法应用索引,违背最左匹配原则
后记
到这里MySQL索引的联合索引的存储结构及查找方式就讲完了,本人能力有限,也是站着前人的肩膀上创作的此文,因为看到搜索引擎的搜索结果前几个技术文章中有存在讲述不清或讲述有误的地方,所以自己才总结出这篇文章分享给大家,如有不对的地方一定要指正哦,谢谢了。
这篇文章断断续续利用工作之余画图加写作用了两三天,主要内容就是上面这些了。不可否认,这篇文章在一定程度上有纸上谈兵之嫌,因为我本人对MySQL的使用,有一些数据库调优的经验,在这里就当是我个人的一篇学习笔记。
另外,MySQL索引及知识非常广泛,本文只是涉及到其中一部分。如与排序(ORDER BY)相关的索引优化及覆盖索引(Covering index)的话题本文并未涉及,同时除B+Tree索引外MySQL还根据不同引擎支持的哈希索引、全文索引等等本文也并未涉及。如果有机会,希望再对本文未涉及的部分进行补充吧。
创作不易,如果对你有帮助,请点赞 关注 转发,这是我创作的源泉~
-----
系列文章:
3.MySQL笔记 | 事务与隔离级别:从“转账”到“数据安全”的奇幻之旅
4.深入理解 MySQL 事务隔离级别:从“读未提交”到“串行化”的全面解析
6.MySQL 索引底层数据结构:从 B+ 树到数据存储的奥秘
7.MySQL锁机制详解:从原理到实战,Java开发者必知的高并发基石
8.Java开发者必备:深度剖析MySQL锁机制与实战避坑指南
9.阿里P8面试官连环逼问MySQL索引:从原理到死锁,答完我后背全湿了探秘
10.MySQL索引底层原理,解锁数据库优化的关键密码(上)
11.探秘 MySQL 索引底层原理,解锁数据库优化的关键密码(中)
探秘 MySQL 索引底层原理,解锁数据库优化的关键密码(下)的更多相关文章
- MySql索引底层原理(01)
目的:通过mysql获取数据,检索数据的原理来理解索引,以及如何利用好索引. 由于篇幅问题,可能会连载几篇文章. 从mysql获取一条数据说起: 我们知道,电脑的系统在获取数据的时候会旋转磁盘,然后移 ...
- 深入理解 MySQL 索引底层原理
https://mp.weixin.qq.com/s/qHJiTjpvDikFcdl9SRL97Q
- Lucene底层原理和优化经验分享(1)-Lucene简介和索引原理
Lucene底层原理和优化经验分享(1)-Lucene简介和索引原理 2017年01月04日 08:52:12 阅读数:18366 基于Lucene检索引擎我们开发了自己的全文检索系统,承担起后台PB ...
- MYSQL索引结构原理、性能分析与优化
[转]MYSQL索引结构原理.性能分析与优化 第一部分:基础知识 索引 官方介绍索引是帮助MySQL高效获取数据的数据结构.笔者理解索引相当于一本书的目录,通过目录就知道要的资料在哪里, 不用一页一页 ...
- 【转】由浅入深探究mysql索引结构原理、性能分析与优化
摘要: 第一部分:基础知识 第二部分:MYISAM和INNODB索引结构 1.简单介绍B-tree B+ tree树 2.MyisAM索引结构 3.Annode索引结构 4.MyisAM索引与Inno ...
- MySQL/MariaDB数据库的索引工作原理和优化
MySQL/MariaDB数据库的索引工作原理和优化 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 实际工作中索引这个技术是影响服务器性能一个非常重要的指标,因此我们得花时间去了 ...
- 重新学习MySQL数据库4:Mysql索引实现原理
重新学习Mysql数据库4:Mysql索引实现原理 MySQL索引类型 (https://www.cnblogs.com/luyucheng/p/6289714.html) 一.简介 MySQL目前主 ...
- MySQL索引的原理,B+树、聚集索引和二级索引
MySQL索引的原理,B+树.聚集索引和二级索引的结构分析 一.索引类型 1.1 B树 1.2 B+树 1.3 哈希索引 1.4 聚集索引(clusterd index) 1.5 二级索引(secon ...
- MySQL索引底层实现原理
优秀博文: MySQL索引背后的数据结构及算法原理 B树.B-树.B+树.B*树[转],mysql索引 MySQL 和 B 树的那些事 索引的本质 MySQL官方对索引的定义为:索引(Index)是帮 ...
- 007 --MySQL索引底层实现原理
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构.提取句子主干,就可以得到索引的本质:索引是数据结构. 我们知道,数据库查询是数据库的最主要功能之一.我们都希望查 ...
随机推荐
- [.NET] 使用客户端缓存提高API性能
使用客户端缓存提高API性能 摘要 在现代应用程序中,性能始终是一个关键的考虑因素.无论是提高响应速度,降低延迟,还是减轻服务器负载,开发者都在寻找各种方法来优化他们的API.在Web开发中,利用客户 ...
- 《C++并发编程实战》读书笔记(1):线程管控
1.线程的基本管控 包含头文件<thread>后,通过构建std::thread对象启动线程,任何可调用类型都适用于std::thread. void do_some_work(); st ...
- 如何发现漏洞之我的多功能武器BurpSuite与全能插件
知识点 1.插件类-武装BurpSuite-漏洞检测&分析辅助 2.插件类-武装谷歌浏览器-信息收集&情报辅助 一.演示案例-插件类-武装BurpSuite-漏洞检测&分析辅助 ...
- C#钩子(Hook) 捕获键盘鼠标所有事件 - 5分钟没有操作,自动关闭 Form 窗体
C# 钩子 捕获键盘鼠标所有事件,可用于:判断鼠标键盘无操作时,关闭 Winform 窗体 5分钟没有操作,自动关闭 Form 窗体 钩子(Hook)的作用主要体现在监视和拦截系统或进程中的各种事件消 ...
- Java虚拟机调优-垃圾回收算法-工具
背景: 垃圾回收的瓶颈 传统分代垃圾回收方式,已经在一定程度上把垃圾回收给应用带来的负担降到了最小,把应用的吞吐量推到了一个极限.但是他无法解决的一个问题,就是Full GC所带来的应用暂停.在一些对 ...
- Java常用的并发类-总结列表
一.java集合框架概述 java集合可分为Collection和Map两种体系,其中: 1.Collection接口:单列数据,定义了存取一组对象的方法的集合: List:元素有序.可重复的集合 S ...
- Kotlin:【Map集合】集合创建、集合遍历、元素增加
to本身是一个函数
- Jetbrains系列产品无限时间重置插件
概述Jetbrains家的产品有一个很良心的地方,他会允许你试用30天(这个数字写死在代码里了)以评估是否你真的需要为它而付费. 事实上有一款插件可以实现这个功能,你或许可以用它来重置一下试用时间.但 ...
- 3090 cuda环境配置杂记
实验室新配了3090的电脑,cuda环境配置上出了些问题,百度很久才找到解决方法,因此记录下来. 主要参考:(6条消息) 服务器Linux环境配置cuda(非管理员)_@@Lynn的博客-CSDN博客 ...
- java内部类与单例模式
java中不允许外部类使用 private,protected 修饰 所谓的外部类:就是在源码中直接声明的类 所谓的内部类: 就是类中声明的类,内部类可以使用 public, private, pro ...