Pydantic递归模型深度校验36计:从无限嵌套到亿级数据的优化法则
title: Pydantic递归模型深度校验36计:从无限嵌套到亿级数据的优化法则
date: 2025/3/26
updated: 2025/3/26
author: cmdragon
excerpt:
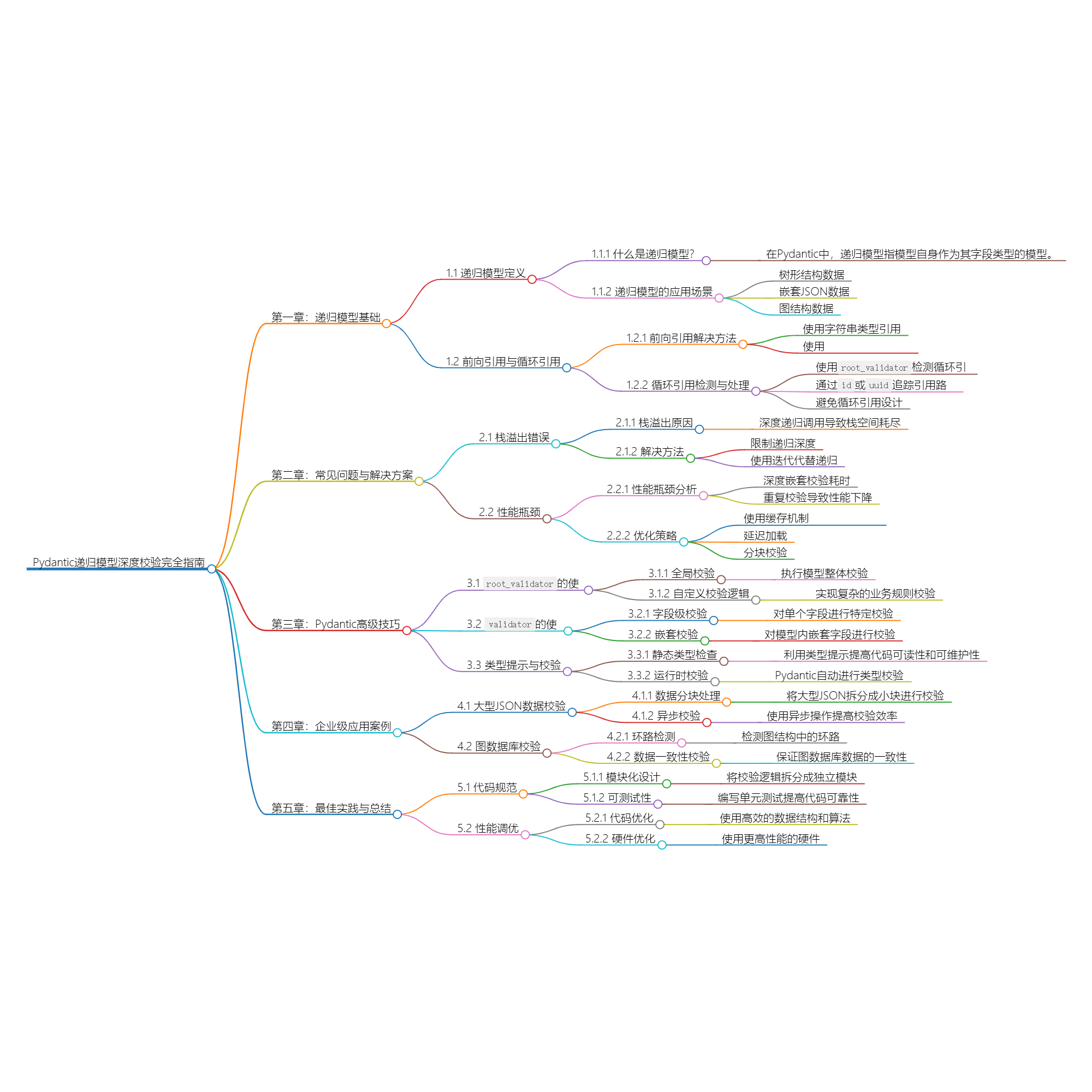
递归模型通过前向引用支持无限层级嵌套结构,自动处理类型自洽验证。图结构校验器实现环检测算法,管理关系验证防止交叉引用循环。性能优化采用延迟加载与分块校验策略,分别处理大型数据解析与内存占用问题。分布式管道验证确保节点间schema一致性,内存优化通过不可变数据类型转换实现。生成式校验分析模板变量依赖关系,增量校验应用版本差异比对。错误处理需区分递归深度异常与循环引用,采用路径跟踪和迭代转换替代深层递归。架构设计遵循有限深度原则,结合访问者模式与缓存机制提升校验效率。
categories:
- 后端开发
- FastAPI
tags:
- Pydantic递归模型
- 深度嵌套验证
- 循环引用处理
- 校验性能优化
- 大规模数据验证
- 图结构校验
- 内存管理策略

扫描二维码关注或者微信搜一搜:编程智域 前端至全栈交流与成长
{kind=link}
第一章:递归模型基础
1.1 自引用模型实现
from pydantic import BaseModel
from typing import List, Optional
class TreeNode(BaseModel):
name: str
children: List['TreeNode'] = [] # 前向引用
# 创建7层深度树结构
root = TreeNode(name="root", children=[
TreeNode(name="L1", children=[
TreeNode(name="L2", children=[
TreeNode(name="L3")
])
])
])
递归模型特性:
- 支持无限层级嵌套
- 自动处理前向引用
- 内置深度控制机制
- 类型系统自洽验证
第二章:复杂结构验证
2.1 图结构环检测
class GraphNode(BaseModel):
id: str
edges: List['GraphNode'] = []
@validator('edges')
def check_cycles(cls, v, values):
visited = set()
def traverse(node, path):
if node.id in path:
raise ValueError(f"环状路径检测: {'->'.join(path)}->{node.id}")
if node.id not in visited:
visited.add(node.id)
for edge in node.edges:
traverse(edge, path + [node.id])
traverse(values['self'], [])
return v
2.2 交叉引用验证
from pydantic import Field
class User(BaseModel):
id: int
friends: List['User'] = Field(default_factory=list)
manager: Optional['User'] = None
@root_validator
def validate_relationships(cls, values):
def check_hierarchy(user: User, seen=None):
seen = seen or set()
if user.id in seen:
raise ValueError("管理关系循环")
seen.add(user.id)
if user.manager:
check_hierarchy(user.manager, seen)
check_hierarchy(values['self'])
return values
第三章:性能优化策略
3.1 延迟加载验证
class LazyValidator(BaseModel):
data: str
_parsed: dict = None
@validator('data', pre=True)
def lazy_parse(cls, v):
# 延迟解析直到首次访问
instance = cls()
instance._parsed = json.loads(v)
return v
@root_validator
def validate_content(cls, values):
if values['_parsed'] is None:
values['_parsed'] = json.loads(values['data'])
# 执行深度校验逻辑
validate_nested(values['_parsed'], depth=10)
return values
3.2 分块校验模式
from pydantic import validator, parse_obj_as
class ChunkedData(BaseModel):
chunks: List[str]
@validator('chunks', pre=True)
def split_data(cls, v):
if isinstance(v, str):
return [v[i:i + 1024] for i in range(0, len(v), 1024)]
return v
@root_validator
def validate_chunks(cls, values):
buffer = []
for chunk in values['chunks']:
buffer.append(parse_obj_as(DataChunk, chunk))
if len(buffer) % 100 == 0:
validate_buffer(buffer)
buffer.clear()
return values
第四章:企业级应用
4.1 分布式数据管道
class PipelineNode(BaseModel):
input_schema: dict
output_schema: dict
next_nodes: List['PipelineNode'] = []
@root_validator
def validate_pipeline(cls, values):
visited = set()
def check_node(node):
if id(node) in visited:
return
visited.add(id(node))
if node.output_schema != node.next_nodes[0].input_schema:
raise ValueError("节点schema不匹配")
for n in node.next_nodes:
check_node(n)
check_node(values['self'])
return values
4.2 内存优化模式
class CompactModel(BaseModel):
class Config:
arbitrary_types_allowed = True
copy_on_model_validation = 'none'
@root_validator
def optimize_memory(cls, values):
for field in cls.__fields__:
if isinstance(values[field], list):
values[field] = tuple(values[field])
elif isinstance(values[field], dict):
values[field] = frozenset(values[field].items())
return values
第五章:高级校验模式
5.1 生成式校验
class GenerativeValidator(BaseModel):
template: str
dependencies: List['GenerativeValidator'] = []
@root_validator
def check_templates(cls, values):
from jinja2 import Template, meta
parsed = Template(values['template'])
required_vars = meta.find_undeclared_variables(parsed)
def collect_deps(node: 'GenerativeValidator', seen=None):
seen = seen or set()
if id(node) in seen:
return set()
seen.add(id(node))
vars = meta.find_undeclared_variables(Template(node.template))
for dep in node.dependencies:
vars |= collect_deps(dep, seen)
return vars
available_vars = collect_deps(values['self'])
if not required_vars.issubset(available_vars):
missing = required_vars - available_vars
raise ValueError(f"缺失模板变量: {missing}")
return values
5.2 增量校验
class DeltaValidator(BaseModel):
base_version: int
delta: dict
_full_data: dict = None
@root_validator
def apply_deltas(cls, values):
base = load_from_db(values['base_version'])
values['_full_data'] = apply_delta(base, values['delta'])
try:
FullDataModel(**values['_full_data'])
except ValidationError as e:
raise ValueError(f"增量应用失败: {str(e)}")
return values
课后Quiz
Q1:处理循环引用的最佳方法是?
A) 使用weakref
B) 路径跟踪校验
C) 禁用验证
Q2:优化深层递归校验应使用?
- 尾递归优化
- 迭代转换
- 增加栈深度
Q3:内存优化的关键策略是?
- 使用不可变数据类型
- 频繁深拷贝数据
- 启用所有缓存
错误解决方案速查表
| 错误信息 | 原因分析 | 解决方案 |
|---|---|---|
| RecursionError: 超过最大深度 | 未控制递归层级 | 使用迭代代替递归 |
| ValidationError: 循环引用 | 对象间相互引用 | 实现路径跟踪校验 |
| MemoryError: 内存溢出 | 未优化大型嵌套结构 | 应用分块校验策略 |
| KeyError: 字段缺失 | 前向引用未正确定义 | 使用ForwardRef包裹类型 |
| TypeError: 不可哈希类型 | 在集合中使用可变类型 | 转换为元组或冻结集合 |
架构原则:递归模型应遵循"有限深度"设计原则,对超过10层的嵌套结构自动启用分块校验机制。建议使用访问者模式解耦校验逻辑,通过备忘录模式缓存中间结果,实现校验性能指数级提升。
余下文章内容请点击跳转至 个人博客页面 或者 扫码关注或者微信搜一搜:编程智域 前端至全栈交流与成长,阅读完整的文章:Pydantic递归模型深度校验36计:从无限嵌套到亿级数据的优化法则 | cmdragon's Blog
往期文章归档:
- Pydantic异步校验器深:构建高并发验证系统 | cmdragon's Blog
- Pydantic根校验器:构建跨字段验证系统 | cmdragon's Blog
- Pydantic配置继承抽象基类模式 | cmdragon's Blog
- Pydantic多态模型:用鉴别器构建类型安全的API接口 | cmdragon's Blog
- FastAPI性能优化指南:参数解析与惰性加载 | cmdragon's Blog
- FastAPI依赖注入:参数共享与逻辑复用 | cmdragon's Blog
- FastAPI安全防护指南:构建坚不可摧的参数处理体系 | cmdragon's Blog
- FastAPI复杂查询终极指南:告别if-else的现代化过滤架构 | cmdragon's Blog
- FastAPI 核心机制:分页参数的实现与最佳实践 | cmdragon's Blog
- FastAPI 错误处理与自定义错误消息完全指南:构建健壮的 API 应用 ️ | cmdragon's Blog
- FastAPI 自定义参数验证器完全指南:从基础到高级实战 | cmdragon's Blog
- FastAPI 参数别名与自动文档生成完全指南:从基础到高级实战 | cmdragon's Blog
- FastAPI Cookie 和 Header 参数完全指南:从基础到高级实战 | cmdragon's Blog
- FastAPI 表单参数与文件上传完全指南:从基础到高级实战 | cmdragon's Blog
- FastAPI 请求体参数与 Pydantic 模型完全指南:从基础到嵌套模型实战 | cmdragon's Blog
- FastAPI 查询参数完全指南:从基础到高级用法 | cmdragon's Blog
- FastAPI 路径参数完全指南:从基础到高级校验实战 | cmdragon's Blog
- FastAPI路由专家课:微服务架构下的路由艺术与工程实践 | cmdragon's Blog
- FastAPI路由与请求处理进阶指南:解锁企业级API开发黑科技 | cmdragon's Blog
- FastAPI路由与请求处理全解:手把手打造用户管理系统 | cmdragon's Blog
- FastAPI极速入门:15分钟搭建你的首个智能API(附自动文档生成) | cmdragon's Blog
- HTTP协议与RESTful API实战手册(终章):构建企业级API的九大秘籍 | cmdragon's Blog
- HTTP协议与RESTful API实战手册(二):用披萨店故事说透API设计奥秘 | cmdragon's Blog
- 从零构建你的第一个RESTful API:HTTP协议与API设计超图解指南 | cmdragon's Blog
- Python异步编程进阶指南:破解高并发系统的七重封印 | cmdragon's Blog
- Python异步编程终极指南:用协程与事件循环重构你的高并发系统 | cmdragon's Blog
- Python类型提示完全指南:用类型安全重构你的代码,提升10倍开发效率 | cmdragon's Blog
- 三大平台云数据库生态服务对决 | cmdragon's Blog
- 分布式数据库解析 | cmdragon's Blog
- 深入解析NoSQL数据库:从文档存储到图数据库的全场景实践 | cmdragon's Blog
- 数据库审计与智能监控:从日志分析到异常检测 | cmdragon's Blog
- 数据库加密全解析:从传输到存储的安全实践 | cmdragon's Blog
Pydantic递归模型深度校验36计:从无限嵌套到亿级数据的优化法则的更多相关文章
- python手动设置递归调用深度
python超出递归深度时会出现异常: RuntimeError: maximum recursion depth exceeded python默认的递归深度是很有限的,大概是900当递归深度超过这 ...
- 写给程序员的机器学习入门 (五) - 递归模型 RNN,LSTM 与 GRU
递归模型的应用场景 在前面的文章中我们看到的多层线性模型能处理的输入数量是固定的,如果一个模型能接收两个输入那么你就不能给它传一个或者三个.而有时候我们需要根据数量不一定的输入来预测输出,例如文本就是 ...
- 写给程序员的机器学习入门 (七) - 双向递归模型 (BRNN) - 根据上下文补全单词
这一篇将会介绍什么是双向递归模型和如何使用双向递归模型实现根据上下文补全句子中的单词. 双向递归模型 到这里为止我们看到的例子都是按原有顺序把输入传给递归模型的,例如传递第一天股价会返回根据第一天股价 ...
- python基础(补充):递归的深度
我们在正经人谁用递归呀一节中,简单的讨论了python中的递归 相信用过python递归的朋友可能都碰到过: RecursionError: maximum recursion depth excee ...
- Java内存模型深度解析:总结--转
原文地址:http://www.codeceo.com/article/java-memory-7.html 处理器内存模型 顺序一致性内存模型是一个理论参考模型,JMM和处理器内存模型在设计时通常会 ...
- NLP文本情感分类传统模型+深度学习(demo)
文本情感分类: 文本情感分类(一):传统模型 摘自:http://spaces.ac.cn/index.php/archives/3360/ 测试句子:工信处女干事每月经过下属科室都要亲口交代24口交 ...
- Goroutine并发调度模型深度解析之手撸一个协程池
golanggoroutine协程池Groutine Pool高并发 并发(并行),一直以来都是一个编程语言里的核心主题之一,也是被开发者关注最多的话题:Go语言作为一个出道以来就自带 『高并发』光环 ...
- java中身份证号和的银行卡的深度校验
一: 身份证号: package com.mobile.utils; import java.text.SimpleDateFormat; import java.util.Calendar; imp ...
- 集成学习-Boosting 模型深度串讲
首先强调一下,这篇文章适合有很好的基础的人 梯度下降 这里不系统讲,只介绍相关的点,便于理解后文 先放一个很早以前写的 梯度下降 实现 logistic regression 的代码 def tidu ...
- [NLP自然语言处理]谷歌BERT模型深度解析
我的机器学习教程「美团」算法工程师带你入门机器学习 已经开始更新了,欢迎大家订阅~ 任何关于算法.编程.AI行业知识或博客内容的问题,可以随时扫码关注公众号「图灵的猫」,加入”学习小组“,沙雕博主 ...
随机推荐
- 《计算机体系结构与SoC设计》(二)
1. 多指令流单数据流 多指令流单数据流(Multiple Instruction Stream, Single Data Stream,简称 MISD)是一种处理器设计概念,它允许处理器在单个时钟周 ...
- 解读ENS网络连接,面向多云多池网络的高效互联
本文分享自华为云社区<ENS网络连接,面向多云多池网络的高效互联>,作者:华为云Stack ENS研发团队. 1.ENS网络连接服务场景详细介绍 ENS网络连接通过统一建模和全局管控实现跨 ...
- 第一章 dubbo源码解析目录
重要的网址: dubbo的github:https://github.com/alibaba/dubbo dubbo官网:http://dubbo.io/ dubbo使用者手册:https://dub ...
- Docker网络:Docker0、容器互联技术--link、自定义网络、实战部署Redis集群
一.Docker网络 ● --理解Docker0 在干净的Linux环境上安装docker(将docker 的所有镜像.容器先删除,干干净净!)实验: 1.查看本地网络信息 ip addr 可见有三个 ...
- bat脚本判断windows服务,判断windows进程
bat脚本判断windows服务是否存在,方式一: sc query|findstr /i "ZhuDongFangYu" &&echo "存在" ...
- JavaBean、this:“当前对象的.”、
this:区分类的属性和形参
- C#客户端Json转DataTable
本文转自 https://blog.csdn.net/pinebud55/article/details/52240287 感谢pinebud55分享 之前我们有讨论过c#是如何处理json的,在我的 ...
- Linux VXLAN小实验
本文分享自天翼云开发者社区<Linux VXLAN小实验>,作者:李****一 前言 VXLAN在云网络中应用十分广泛.本文介绍一种方法在两台Linux主机之间建立简单的VXLAN隧道,以 ...
- DBeaver连接PostgreSQL后只有默认数据库“postgres”不显示其他数据库的问题解决办法
我们在使用DBeaver连接PostgreSQL后,发现数据库中只有"postgres"默认数据库,不显示我们自己创建的数据库. 1.问题描述 我们在使用DBeaver连接Post ...
- Excel中使用VLOOKUP对两个单元格关联
一.背景 exl中需要关联两个Excel,根据主键合并两个单元格数据 二.使用方法 1.表1---列包含在id.姓名.年龄 2.表2---列包含姓名.性别 3.期望根据[姓名]列为主键,关联两个表数据 ...