技术 | LLaMA Factory微调记录重修版
之前投的那篇教程我自己回看一遍都不太搞得明白,从新梳理一遍
1. 云服务器准备
恒源云 (gpushare.com) 配置建议:
- GPU: RTX 3090 (24GB) 或 RTX 4090 (24GB)
- 系统: Ubuntu 20.04/22.04
- 存储: 至少 50GB 空间
2. 环境检查与初始化
# 检查GPU状态
nvidia-smi
# 检查系统信息
df -h # 查看磁盘空间
free -h # 查看内存
用home目录存储训练数据
因为网络不怎么友好,因此提前下载好LLaMA Factory的安装包,直接拖到home目录
3. LLaMA-Factory 安装与配置
# 进入home目录
cd /home
# 解压LLaMA-Factory(如果您已经上传zip文件)
unzip LLaMA-Factory-main.zip
# 进入目录
cd LLaMA-Factory-main
# 安装依赖(使用国内镜像加速)
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
# 安装为可编辑模式(创建CLI命令)
pip install -e .
输出地址会被映射到7860端口(类似 http://0.0.0.0:7860),AutoDL 需端口映射:
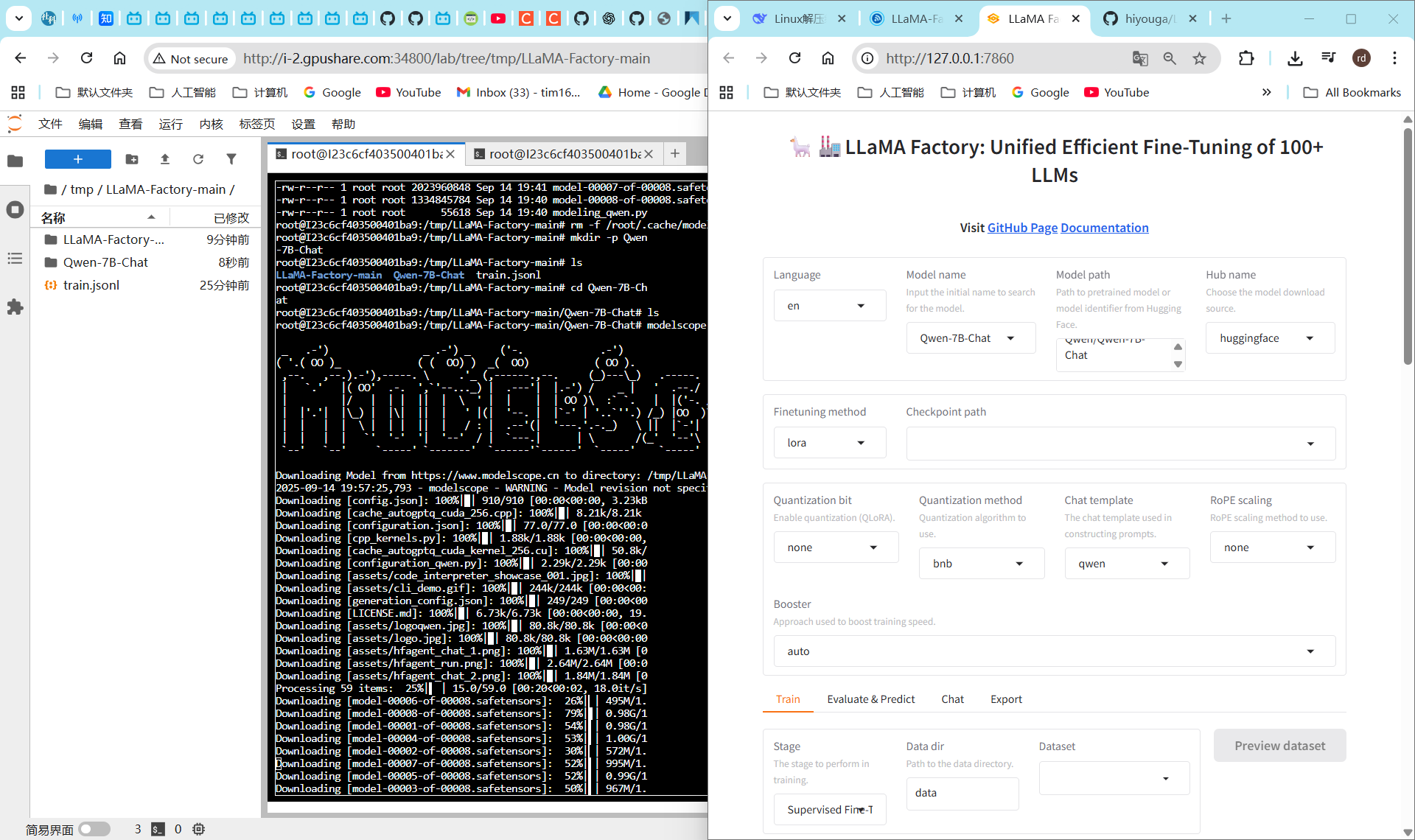
4. 下载预训练模型 Qwen-7B-Chat [4]
# 回到home目录
cd /home
# 创建模型目录并下载
mkdir Qwen-7B-Chat
cd Qwen-7B-Chat
# 使用ModelScope下载(国内推荐)
modelscope download Qwen/Qwen-7B-Chat --local_dir ./
# 或者使用HuggingFace Hub(需要魔法)
# huggingface-cli download Qwen/Qwen-7B-Chat --local-dir . --resume-download
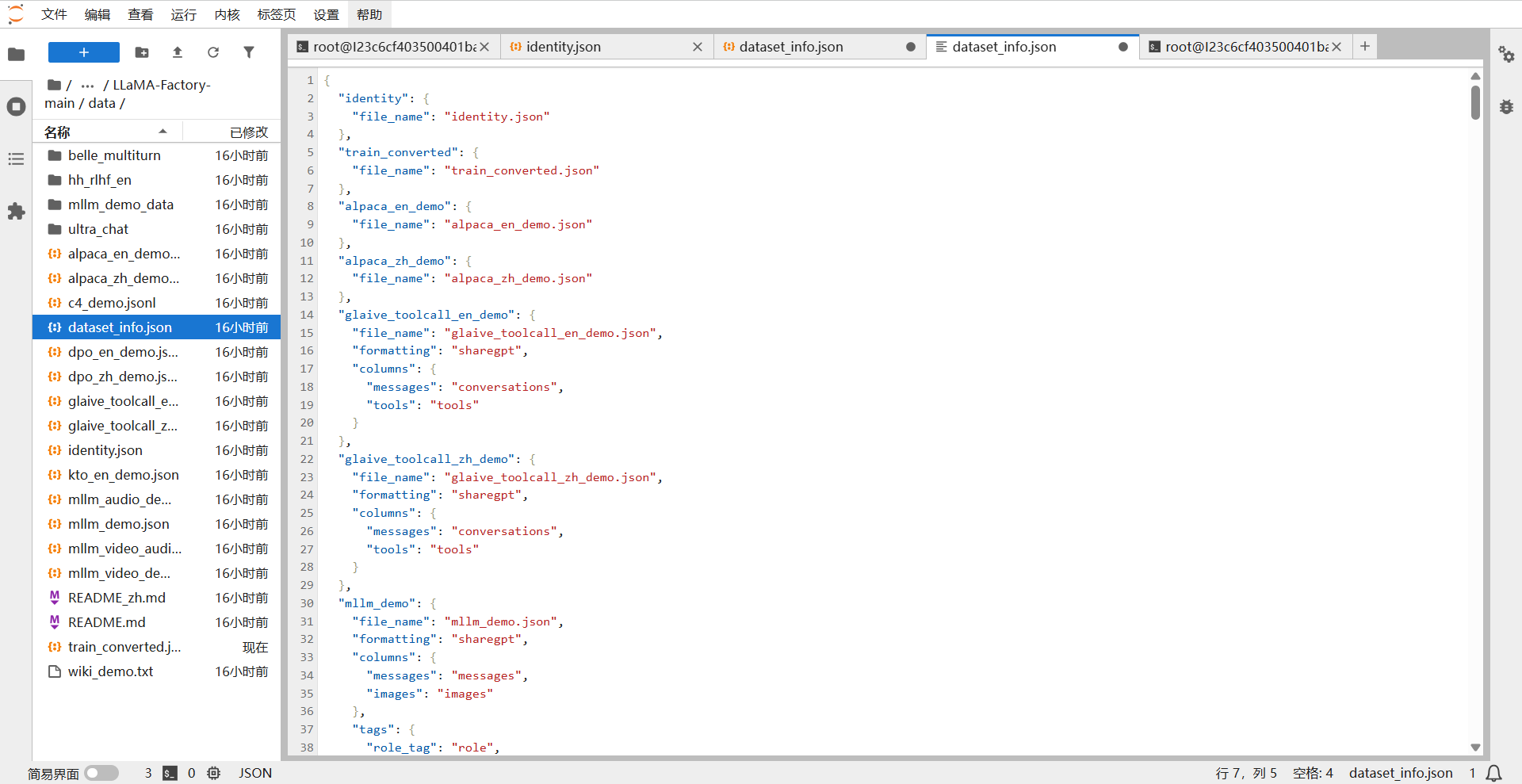
下载 [3] 训练集文件,进入data/identity.json查看默认训练格式,将训练文件格式替换成标准格式
并在 dataset_info.json文件中添加训练集
5. 准备训练数据
数据转换脚本 (data_conversion.py):
import json
def convert_jsonl_to_json(input_file, output_file):
"""
将JSONL格式转换为LLaMA-Factory需要的JSON格式
"""
data = []
with open(input_file, 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
if not line:
continue
try:
obj = json.loads(line)
# 根据您的数据结构调整
for conv in obj.get("conversation", []):
data.append({
"instruction": conv.get("human", ""),
"input": "",
"output": conv.get("assistant", "")
})
except json.JSONDecodeError as e:
print(f"解析错误: {e}, 行内容: {line}")
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=2)
print(f"转换完成!共 {len(data)} 条数据,已保存到 {output_file}")
# 使用示例
if __name__ == "__main__":
convert_jsonl_to_json("train.jsonl", "train_converted.json")
运行转换:
# 将训练数据放到data目录
cd /home/LLaMA-Factory-main/data
# 运行转换脚本
python /path/to/data_conversion.py
# 检查转换后的文件
head -n 5 train_converted.json
配置数据集信息:
编辑 dataset_info.json 文件:
{
"train_converted": {
"file_name": "train_converted.json",
"file_sha1": "自动生成或留空"
}
}
转换好后放到data目录下,添加训练集文件train_converted.json
输出地址会被映射到7860端口(类似 http://0.0.0.0:7860),AutoDL 需端口映射:

Vscode连接至远程服务器,复制ssh和密码,将端口映射到本地
6. 启动WebUI界面
# 进入LLaMA-Factory目录
cd /home/LLaMA-Factory-main
# 启动WebUI(推荐使用screen或tmux保持会话)
screen -S llama-webui
python src/webui.py
# 或者后台运行
nohup python src/webui.py > webui.log 2>&1 &

7. 端口映射与访问
自动跳转到WebUI界面,配置好Qwen-7B-Chat模型后,点击chat配置加载模型进行生成测试
- 如果后面模型加载不出来,就把Qwen-7B-Chat这个文件拖到LLaMA-Factory-main,模型路径改成Qwen-7B-Chat
访问: http://localhost:7860
8. WebUI配置指南
模型加载配置:
- 模型路径:
/home/Qwen-7B-Chat(或相对路径../Qwen-7B-Chat) - 模板:
qwen - 推理后端:
hf(HuggingFace Transformers)
训练参数建议(RTX 3090):
微调方法: LoRA
学习率: 2e-4
批大小: 4
梯度累积: 4
训练轮数: 10-20
LoRA Rank: 64
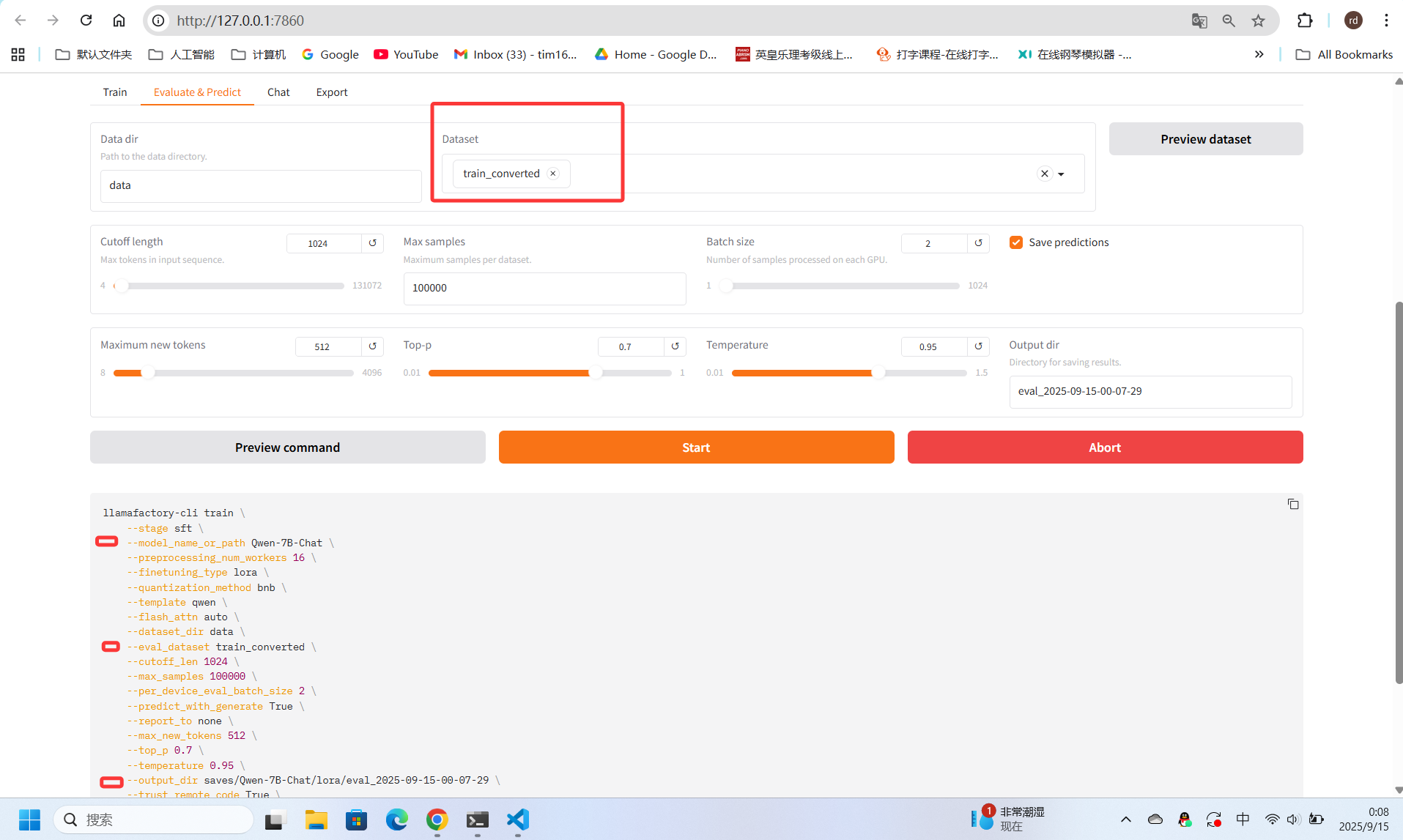
然后在微调界面查看配置的训练集文件train_converted.json,查看没有问题后进行训练(开启训练时显示)(超参数的配置的这方面我不太记得住可以看 [2] 的相关介绍)
3090 24B 跑50轮大概要半个小时左右,训练好的模型可以在评估界面进行测试,同时也可以选择不同时段的训练模型
训练好的模型文件可以下载到本地,并且通过在OpenWebUI的配置可以实现api接口的输出
9. 训练与评估
开始训练:
- 在"训练"标签页配置参数
- 选择数据集:
train_converted - 点击"开始训练"
监控训练进度:
# 查看训练日志
tail -f saves/Qwen-7B-Chat/lora/trainer_log.jsonl
# 查看GPU使用情况
watch -n 1 nvidia-smi
模型测试:
- 训练完成后在"评估"标签页测试
- 选择不同checkpoint进行比较
- 使用"聊天"标签页进行交互测试
10. 模型导出与部署
导出模型:
# 使用LLaMA-Factory CLI导出
llamafactory-cli export \
--model_name_or_path /home/Qwen-7B-Chat \
--adapter_name_or_path saves/Qwen-7B-Chat/lora \
--template qwen \
--finetuning_type lora \
--export_dir /home/Qwen-7B-Chat-finetuned
创建API服务:
# 简单的FastAPI示例
from fastapi import FastAPI
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
app = FastAPI()
# 加载模型
model_path = "/home/Qwen-7B-Chat-finetuned"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True).cuda()
@app.post("/chat")
async def chat_endpoint(message: str):
inputs = tokenizer(message, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=100)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return {"response": response}
常见问题解决
1. 模型加载失败:
# 检查模型路径
ls -la /home/Qwen-7B-Chat/
# 确保有这些文件: config.json, model.safetensors, tokenizer.json
2. 内存不足:
- 减少批大小
- 使用梯度累积
- 启用4bit量化:
--load_in_4bit
3. 训练速度慢:
- 启用Flash Attention
- 使用DeepSpeed优化
4. 端口无法访问:
- 检查防火墙设置
- 确认端口映射正确
训练时间预估(RTX 3090)
- 数据量: 1000条对话
- 训练轮数: 20轮
- 预计时间: 30-60分钟
- GPU内存占用: 18-22GB
[1] 官方文档 数据处理 https://llamafactory.readthedocs.io/zh-cn/latest/getting_started/data_preparation.html
[2] 【DeepSeek+LoRA+FastAPI】开发人员如何微调大模型并暴露接口给后端调用
https://www.bilibili.com/video/BV1R6P7eVEtd/?spm_id_from=333.337.search-card.all.click&vd_source=d5f2b87dc23c8806dfc6d9550f24aaf2
[3] 魔塔社区,沐雪(中文)训练集 Moemuu/Muice-Dataset,https://www.modelscope.cn/datasets/Moemuu/Muice-Dataset/file/view/master/train.jsonl?id=11077&status=1
[4] 魔塔社区,通义千问-7B-Chat,Qwen/Qwen-7B-Chat,https://www.modelscope.cn/models/Qwen/Qwen-7B-Chat
技术 | LLaMA Factory微调记录重修版的更多相关文章
- Android开发技术周报176学习记录
Android开发技术周报176学习记录 教程 当 OkHttp 遇上 Http 2.0 http://fucknmb.com/2018/04/16/%E5%BD%93OkHttp%E9%81%87% ...
- Android开发技术周报182学习记录
Android开发技术周报182学习记录 教程 App安全二三事 记录 为什么要安全 App的移动安全主要包括下面几种: 密钥破解,导致本地加密数据被盗取. 通信密钥破解,导致接口数据被盗取. 伪造接 ...
- Android开发技术周报183学习记录
Android开发技术周报183学习记录 教程 Android性能优化来龙去脉总结 记录 一.性能问题常见 内存泄漏.频繁GC.耗电问题.OOM问题. 二.导致性能问题的原因 1.人为在ui线程中做了 ...
- 会话技术之cookie(记录当前时间、浏览记录的记录和清除)
cookie 会话技术: 当用户打开浏览器的时候,访问不同的资源,直到用户将浏览器关闭,可以认为这是一次会话. 作用: 因为http协议是一个无状态的协议,它不会记录上一次访问的内容.用户在访问过程中 ...
- CefSharp-基于C#的客户端开发框架技术栈开发全记录
CefSharp简介 源于Google官方 CefSharp用途 CefSharp开发示例 CefSharp应用--弹窗与右键 不弹出子窗体 禁用右键 CefSharp应用--High DPI问题 缩 ...
- 【uniapp 开发】uni-app 技术点的链接记录
优雅的H5下拉刷新.零依赖,高性能,多主题,易拓展 https://ask.dcloud.net.cn/article/12772 图像(头像)选择,截取,压缩,上传的分享 https://ask.d ...
- <转>技术团队新官上任之基层篇
发表于2013-09-04 17:17| 10455次阅读| 来源<程序员>| 35 条评论| 作者高博 <程序员>杂志2013年9月刊技术团队管理EMC高博CTO 摘要:从技 ...
- 【Java面试】什么是可重入,什么是可重入锁? 它用来解决什么问题?
一个工作了3年的粉丝,去一个互联网公司面试,结果被面试官怼了. 面试官说:"这么简单的问题你都不知道? 没法聊了,回去等通知吧". 这个问题是: "什么是可重入锁,以及它 ...
- Java Web编程技术学习要点及方向
学习编程技术要点及方向亮点: 传统学习编程技术落后,应跟著潮流,要对业务聚焦处理.要Jar, 不要War:以小为主,以简为宝,集堆而成.去繁取简 Spring Boot,明日之春(future of ...
- linux可重入、异步信号安全和线程安全
一 可重入函数 当一个被捕获的信号被一个进程处理时,进程执行的普通的指令序列会被一个信号处理器暂时地中断.它首先执行该信号处理程序中的指令.如果从信号处理程序返回(例如没有调用exit或longjmp ...
随机推荐
- POLIR-Society-Organization-Management:Transform Business Skills with Proven Simulation and Assessment Technology
Capsim Management Simulations, Inc. Privacy Policy Terms Accessibility Policy Transform Business Ski ...
- FreeSwitch: ESL Inbound内联模式下如何设置单腿变量
outbound外联模式下,可以参考我先前写的文章:freeswitch: ESL中如何自定义事件及自定义事件的监听,使用export导出变量.但是inbound模式下,ESL client并未封装e ...
- JAVA基础-4-.数据类型--九五小庞
练习代码: 1 public class Demo1 { 2 public static void main(String[] args) { 3 System.o ...
- 基于c8t6的平衡小车(CubeMX+MDK)(1)OLED的多级菜单显示
OLED的多级菜单显示 OLED控制之旋转编码器兼按键 按键 按键状态 想想按键有哪些状态呢,按下,断开?,这是最基本的KEYSTATUS,按键还可以有短按,长按,一直按,按多次,这都可以产生不同的按 ...
- Ctorch开发日志——矩阵乘法优化及数学原理
随着项目的推进,本作者遇到了目前最棘手的问题,即矩阵乘法的优化 但是有句话说得好 "你越棘手,我越兴奋" 那么,如下是本作者如何把\(O(MNK)\)(\(O(n^3)\))的朴素 ...
- 开源之夏 2022 重磅来袭!欢迎报名 Casbin社区项目!
01 活动简介 "开源之夏(英文简称 OSPP)" 是中科院软件所 "开源软件供应链点亮计划" 指导下的一项面向高校学生的暑期活动,由中国科学院软件研究所与 o ...
- 简单的博客页面客制化ver2
DIY博客的页面 去繁就简,去掉了一些不必要的功能. 针对新版本的特性做了更改,修正了一些bug. 自己水平不够,在默认博客模板的基础上做了样式修改,部分是套用现成的模板完成的. 具体定制的内容: 1 ...
- SQL Server 分组排序后取第N条数据(或前N条)
节选自 https://blog.csdn.net/cxu123321/article/details/92059001 分组取前N条数据SQL SELECT * FROM( SELECT ROW_N ...
- 还在置顶文件传输助手吗?元宝也可以置顶聊天了!快来试试AI助手吧!
文件传输助手?早该淘汰了! 还在用那个只会"收文件→发文件"的木头人工具?每天对着冷冰冰的"文件传输助手"传图.存链接,结果转头就忘?醒醒吧!微信里藏了个 「元 ...
- 同步动态加载远程JS
<html> <head> </head> <body> </body> </html> <script src=&quo ...