谷歌为何落后于OpenAI?AWS的这条管理原则预言了结局
2012 年我大学毕业,作为一名初入职场的软件工程师开始了职业生涯。
那时,AWS 正逐步进入日本市场,很多 IT 公司开始从本地部署迁移到云端。我的第一个项目是在日立公司基于 AWS 构建基础设施。
那时候的 UI 控制台还很简陋,我们团队通过 API 和 SDK 编写了大量自动化代码,例如负载均衡和自动扩容等功能。而如今,大多数操作都可以轻松通过 UI 控制台完成。
自 AWS 推出以来,它的市场份额一直居于领先地位。
AWS 以极快的节奏不断推出新服务,GCP(Google Cloud Platform)和 Microsoft Azure 虽然一直在追赶,但始终未能撼动其主导地位。
那么问题来了:为什么亚马逊如此具备创新力?
答案在我偶然看到了一段创始人贝索斯的采访视频后浮出水面,他讲解了亚马逊组织团队和开会的方式——也就是著名的「两个披萨原则」。
这个原则的核心是:团队或会议的规模不能超过两块披萨所能喂饱的人数——通常是 6 到 8 人。
作为一名敏捷教练,我学习过大量关于软件组织管理的理论、最佳实践与反模式,并亲历了成功与失败的项目。我可以负责任地说,一些原则确实决定了项目的成败,而「两个披萨原则」正是那些经过科学验证的成功实践之一。
本文将结合我自身经验和深入研究,解释为什么贝索斯提出的“两个披萨原则”是一种优秀的组织管理方式。
虽然我会以软件开发为背景进行讲解,但这些原则其实适用于所有行业。
读完本文,你会找到提升企业管理和项目效率的切实方法。
原则一:让团队变小
贝索斯认为,小团队的生产效率和表现普遍优于大团队。
亚马逊遵循「两个披萨原则」,即每个团队大约 6 到 8 人。即使是他在 2000 年创办蓝色起源(Blue Origin)时,也选择从一个非常小的团队开始。
软件工程领域里有一本被誉为“圣经”的书叫《人月神话》(The Mythical Man-Month),作者是 IBM 的项目经理 Frederick Brooks。
他在书中提到,他曾因错误估算人力而导致操作系统项目延期,并基于自身经验提出了著名的布鲁克斯法则(Brooks's Law):
- 往落后的项目里加人只会让它更落后。
- 团队应保持小型(5~7 人,最多不超过 9 人),因为沟通成本会随人数指数级上升。
- 像软件开发这样复杂的任务是不可拆分的。
他强调,大团队效率低下的主要原因是沟通成本高。
当团队变大后,每个人都很难知道别人正在做什么,信息同步变得困难。Brooks 曾说:“所有人都在做同一个任务时,需要彼此保持同步,而人数越多,大家花在‘搞清楚别人干嘛’上的时间就越多。”
这在数学上也能解释。如果团队里有 5 个人,总共只有 10 条沟通通道;但如果变成 10 个人,沟通通道就暴涨至 45 条。加几个人,沟通路径却会成倍增长,效率急剧下降。
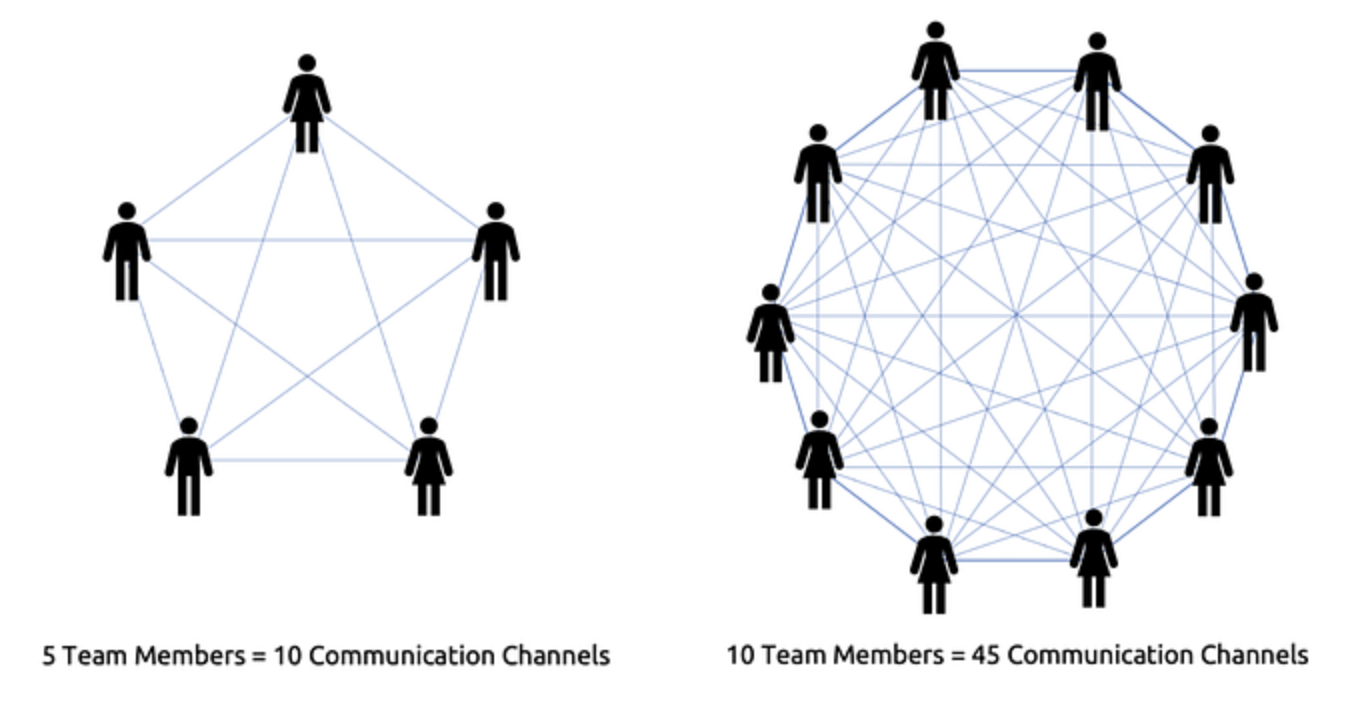
Agile 与 Scrum 团队的最佳团队规模
上世纪 90 年代中期,软件生命周期管理(Software Lifecycle Management)之父 Lawrence Putnam 研究了 491 个中型项目后发现:一旦团队人数超过 8,交付周期会明显拉长。
进一步分析表明,37 人的小团队完成同样任务所需的努力,仅为 920 人大团队的 25% 。性能差距高达 4 倍(400%),这个数据与亚马逊的两个披萨原则和布鲁克斯法则不谋而合。
原则二:让团队独立
「两个披萨原则」的另一个关键是独立性——也就是团队可以自主完成任务,不依赖其他团队。
软件开发中,团队的组织方式大致分两种:按技能划分的“组件团队”和按业务目标划分的“特性团队”(也称跨职能团队)。
组件团队按职能拆分,例如前端组、后端组、设计组等,而特性团队按产品目标组建,成员技能互补,具备完整交付能力。
美国计算机科学家 Melvin Conway 提出过著名的康威定律(Conway's Law):
“软件组件及其架构反映了背后的组织结构”
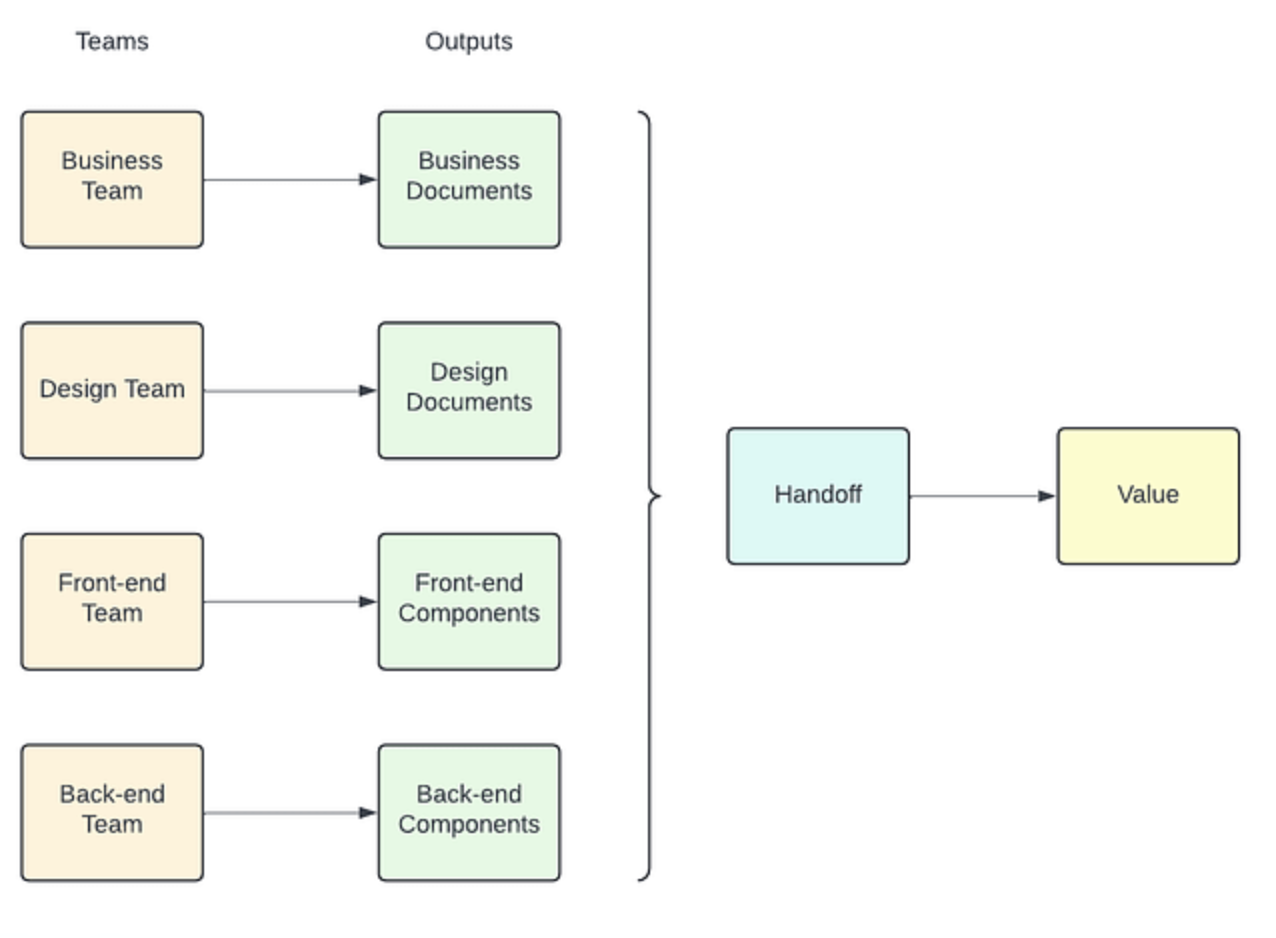
换句话说,如果你把团队拆成“前端/后端/设计/业务”这些组件团队,那么最后产出的是前端、后端模块以及业务和设计文档,这意味着需要在团队之间进行沟通和交接。
而交接意味着:等待、反复开会、信息丢失、容易误解甚至引发冲突。它是软件行业里最常见也最顽固的反模式之一。
独立的团队 = 跨职能的团队
著名科技咨询公司 ThoughtWorks 的 LeRoy 和 Matt Simons 提出了“逆康威定律(Inverse Conway Maneuver)”:
先确定要交付的软件结构,然后反过来组建与之匹配的团队。
比如要开发一个类似 WordPress 的 CMS 系统,可以先根据功能模块划分为“博客发布”、“电商”、“用户管理”等子系统,然后分别组建跨职能小团队。
每个团队中都有业务人员、设计师、开发者和测试人员,整个流程在团队内部就可以完成,无需跨团队协作。
大量研究表明,跨职能团队的效率和表现远高于组件团队。因此,Agile、Scrum 和 DevOps 一致强烈推荐特性团队作为最佳实践。
Agile Accelerate 的 Jim Elvidge 曾在一篇博文中分享了他亲身经历的一个案例:他曾经加入一家采用组件团队模式的大型软件公司后,发现一个简单的小功能竟然要 12 周才能上线,而其中大部分时间都浪费在了等待与不同团队之间的协作和沟通上。
后来,他尝试组建几个特性团队进行对照实验,效果立竿见影——平均交付周期缩短了 5 倍,也就是说,特性团队可以在一周内交付一个功能,而组件团队则需要 5 周才能完成同样的工作。
更令人惊喜的是,随着 Sprint 的推进,这些特性团队的表现还在持续提升。他用实际数据证明了:特性团队在效率和表现上,远远优于组件团队。
原则三:让团队自主
最后,「两个披萨原则」强调的另一个重点是:自治。也就是说,亚马逊的团队有权决定做什么、怎么做,无需高层批准。
在大型组织中,决策流程往往是限制敏捷性的最大瓶颈之一。
举个例子,如果每个团队在开发产品新功能前都必须向 CEO 请示,那信息流最终只会把 CEO 淹没,决策自然变慢,很多传统企业就是这样被“流程”拖垮的。
为了保持敏捷,组织需要建立一种机制,让团队拥有对自身工作的决策权。贝索斯很早就意识到“授权”的重要性,并在亚马逊内部推动了一种强调自治的文化。
麦肯锡的这张图清晰展示了传统层级组织与敏捷组织之间的区别:
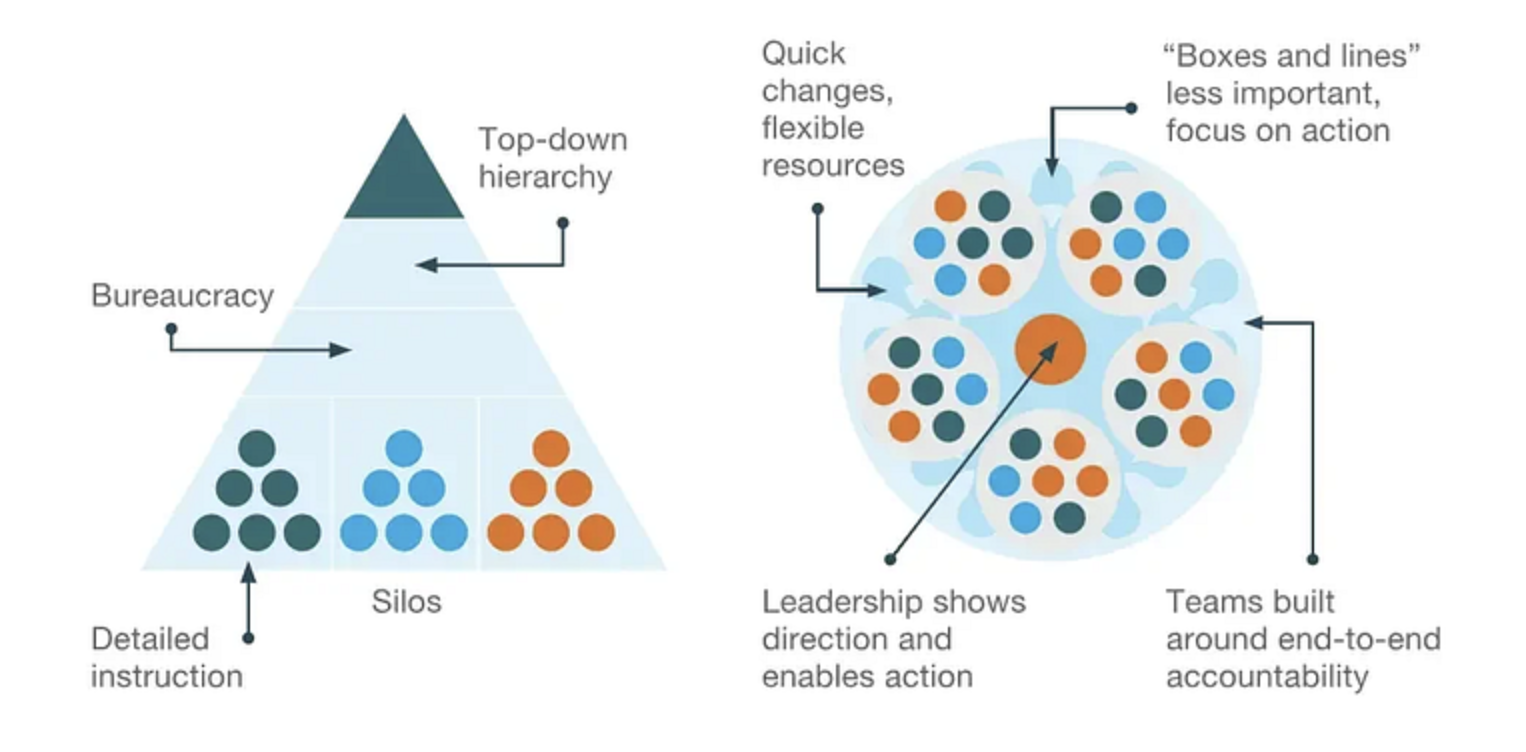
不过,要真正培养团队的自治能力,需要满足三个条件。自治并不容易,因为它依赖于责任感、成熟度以及正确的组织文化。
1. 公司愿景清晰且人人理解
比如,亚马逊的企业愿景是:
“成为地球上最以客户为中心的公司,打造一个让人们能够在线发现和购买他们想要的任何商品的平台。”
这个愿景清楚地表达了客户是亚马逊最核心的价值导向。所有团队在做决策时,都应以“是否对客户有利”为准则。这种清晰的愿景就像一颗北极星,为决策提供方向和标准。
如果一个公司的愿景模糊不清,团队很容易根据自身的方便做决策,缺乏统一标准,最终形成混乱。
2. 具备主人翁意识(Ownership)
自治并不是“想做什么就做什么”,而是“你对你做的每个决定负责”。
这不仅需要正确的心态,还需要具备相应的技能、经验和判断力。
企业若想拥有这样的人才,需要有一套严格的招聘流程、完善的培训体系和支持成长的企业文化,来吸引、培养并留住这些真正负责任的员工。
3. 营造安全的试错环境
即使团队具备了责任心和能力,也不可能不犯错。而要培养决策能力,最有效的方式之一就是“多做多错多成长”。练得多、错得多,判断力才会更强。
贝索斯曾说:“虽然我当然会收集并分析信息,但大多数正确的决策,其实是基于我的直觉。”
这里的“直觉”并不是拍脑袋的决定,而是长期的经验在潜意识中的沉淀。也正因为如此,企业应该提供一个安全的环境,让员工有机会去实践、去犯错,并在过程中逐渐成长。
如果组织不能容错,员工就会因为害怕而不敢承担责任,更不敢独立做决策。贝索斯一再强调,企业应该鼓励员工犯错,并支持他们大胆决策。
总 结
「两个披萨原则」的核心有三个方面:
1. 团队要小(6–8人)
大量研究已证实,小团队的绩效优于大型“单体”团队,因为在小团队中沟通成本低,协作效率高。要实现高效产出,团队规模最好控制在 9 人以内,这样每个成员都能清楚了解彼此在做什么。
2. 团队要独立
亚马逊的团队高度独立,通常是跨职能团队,成员拥有多样化技能,能够自主完成任务,无需依赖其他团队。
康威定律和逆康威定律等研究也都证明:独立的特性团队比传统的按职能拆分的组件团队在效率和协作上表现更好。 Agile Accelerate 的案例甚至显示,功能团队的交付周期比组件团队快 5 倍。
3. 团队要自治
自治意味着团队可以在无需上级批准的情况下,自主决定做什么以及如何完成工作。而在许多大型企业中,决策缓慢是常见的组织瓶颈。
要实现真正的自治,组织必须做到三点:
- 清晰传达企业愿景,成为团队决策的指南针;
- 培养团队的主人翁意识,赋予其权责;
- 营造允许试错的安全环境,鼓励团队在实践中不断提升判断力。
这些原则共同构成了亚马逊快速创新和持续成长的核心管理哲学。更重要的是,它们都是可以被学习、被借鉴、被实践的。无论你是软件公司、制造企业,还是创业团队,都可以从中找到适合自己的高效组织之道。
谷歌为何落后于OpenAI?AWS的这条管理原则预言了结局的更多相关文章
- Kafka副本同步机制
引用自:http://blog.csdn.net/lizhitao/article/details/51718185 Kafka副本 Kafka中主题的每个Partition有一个预写式日志文件,每个 ...
- 图文了解 Kafka 的副本复制机制
让分布式系统的操作变得简单,在某种程度上是一种艺术,通常这种实现都是从大量的实践中总结得到的.Apache Kafka 的受欢迎程度在很大程度上归功于其设计和操作简单性.随着社区添加更多功能,开发者们 ...
- GCP 谷歌云平台申请教程
最近为了学个国外的课程,想要用谷歌云平台的GPU,谷歌云平台,新注册,赠送300美金,免费用一年.注册的时候发现,必须要有国外的信用卡,网上搜索,并试了几个解决方案. 1.不用信用卡,能不能申请成功? ...
- Google谷歌在根据流量统计分析当年的2008年汶川大地震
这是一张2008年的老图,Google当时的博文说道:"当我们依照惯例整理和分析谷歌搜索引擎的流量数据时,一条从未见过的曲线出现在我们面前.当意识到发生了什么事情时,我们的眼睛湿润了.&qu ...
- 从 MySQL+MMM 到 MariaDB+Galera Cluster : 一个高可用性系统改造
很少有事情比推出高可用性(HA)系统之后便经常看到的系统崩溃更糟糕.对于我们这个Rails运行机的团队来说,这个失效的HA系统是MySQL多主复制管理器(MMM). 我们已经找寻MMM的替代品有一段时 ...
- 优酷、YouTube、Twitter及JustinTV视频网站架构设计笔记
本文是整理的关于优酷.YouTube.Twitter及JustinTV几个视频网站的架构或笔记,对于不管是视频网站.门户网站或者其它的网站,在架构上都有一定的参考意义,毕竟成功者的背后总有值得学习的地 ...
- 我所理解的 惠普云 (HP Cloud)
HP (惠普)于2014年5月27日宣布了它的新的云产品线 HP Helion,并宣布在接下来的两年时间内向该产品线投资10亿美金.应该说这是一笔很大的投入,充分显示了HP 在云这个领域的决心.本文试 ...
- 全球最受欢迎的十大Linux发行版(图)
帮助新的Linux用户在越来越多的Linux发行版中选择最合适的操作系统,是创建这个网页的原因.它列出了迄今为止最流行的10个Linux发行版(另外增加的是FreeBSD,到目前为止最为流行的BSD系 ...
- 优酷、YouTube、Twitter及JustinTV几个视频网站的架构
优酷视频网站架构 一.网站基本数据概览据2010年统计,优酷网日均独立访问人数(uv)达到了8900万,日均访问量(pv)更是达到了17亿,优酷凭借这一数据成为google榜单中国内视频网站排名最 ...
- 译:Dataiku 白皮书之《在银行和保险行业应用数据科学》
原文链接:Data Science For Banking & Insurance 如果不能正常访问,请点击备份获取. 在银行和保险行业应用数据科学 互联网巨头和金融技术创业时代的求生和发展 ...
随机推荐
- 题解:CF361B Levko and Permutation
前置芝士--最大公约数 - OI Wiki 题目其实很简单,我们可以知道一些最大公约数的性质: 有一个数 xxx,则: gcd(x,x−1)=1gcd(1,x)=1\gcd(x,x-1)=1 \\ ...
- DIY钢铁侠方舟反应堆第二期—第一代电路板展示
经历一个周的时间,终于把方舟反应堆的电路画了出来,简单画了一个USB口加LED灯的电路,先简单测试一下 原理图展示 PCB展示 实物如下 这里出了一点意外,LED被发错了,本来计划的是蓝灯,但是发来的 ...
- access vba实现OLE对象保存到本地
参考oletodisk的实现方法,更新为在64位office上野可以运行,函数模块代码如下: 1 Option Compare Database 2 Option Explicit 3 4 5 'DE ...
- TypeScript+Vue3
TypeScript Any 类型 和 unknown 顶级类型 1.没有强制限定哪种类型,随时切换类型都可以 我们可以对 any 进行任何操作,不需要检查类型 2.声明变量的时候没有指定任意类型默认 ...
- HTML5和CSS3基础
HTML元素 空元素 不是所有元素都拥有开始标签.内容和结束标签.一些元素只有一个标签,通常用来在此元素所在位置插入/嵌入一些东西.这些元素被称为空元素例如:元素 `` 是用来在页面插入一张指定的图片 ...
- 【代码】C语言|保留小数点后n位并四舍五入,便于处理运算和存储不善的浮点数
前言 有个人跟我说浮点数运算起来非常麻烦,总是算着算着丢失精度,导致计算结果取int的时候取不准.毕竟系统也没有自动根据这个数的精度四舍五入的功能. 比如int(2.999999999999999)= ...
- Python实验4 列表与字典应用
目的 :熟练操作组合数据类型. 试验任务: 基础:生日悖论分析.如果一个房间有23 人或以上,那么至少有两 个人的生日相同的概率大于50%.编写程序,输出在不同随机样本数 量下,23 个人中至少两个人 ...
- Vue知识沉淀
为什么组件my-item的props是listCount,但传入时候用:list-count传入,而 listCount与list-count不一致 <!DOCTYPE html> < ...
- C#之结构
结构是用户定义的数据类型,与类非常相似,它们有数据成员和函数成员,但与类最重要的区别是:类是引用类型,而结构是值类似,结构是隐式密封的,这意味这它们不能被派生,所以结构类型不能为null,两个结构变量 ...
- React-Native开发鸿蒙NEXT-video
React-Native开发鸿蒙NEXT-video 前几周的开发,基本把一个"只读型"社区开发的差不多了.帖子列表,详情,搜索都迁移实现了,但还差了一点------视频类型帖子的 ...