随着平台业务的发展,依赖于Portal(Web)构建的服务架构已逐渐不能满足现有的一些复杂需求(如:使用Hive SQL无法完成计算逻辑),而且对于一些具备编程能力的程序员或数据分析师而言,能够自主控制任务的诉求越来越多,这就要求我们必须把平台的计算能力开放出去,主要涉及以下三个问题:
(1)用户可以通过前端机(Gateway)访问Hadoop线下集群(Offline Cluster)、Hadoop线上集群(Online Cluster),并在两者之间做切换;
(2)HDFS权限控制:用户仅仅可以访问或操作自己有权限的目录或文件;
(3)Yarn资源隔离:用户的任务仅仅能提交给特定的队列,且队列的资源配额、同时运行的任务数等需要受到严格控制;
以下逐一介绍我们是如何解决上述三个问题的。
1.前端机(Gateway)、线下集群(Hadoop Offline Cluster)、线上集群(Hadoop Online Cluster)
集群就是Hadoop集群,先介绍下三者的概念,
线下集群:测试环境中的Hadoop集群,规模很小,用于用户开发测试使用;
线上集群:生产环境中的Hadoop集群,用于用户部署正式应用;
前端机:集群入口,用户登录之后可以操作HDFS、提交MapReduce或Spark任务,可以简单理解为一个Hadoop Client;
其中,线下集群与线上集群的数据需要定时同步(考虑到线下集群存储资源有限,目前的策略是仅选取少量数据同步)。
前端机目前仅有一个实例,用户操作(HDFS、MapReduce、Spark)时需要支持可以在线下集群与线上集群之间作切换。
(1)HDFS
Hadoop集群(线下、线上)构建于版本hadoop-2.5.0-cdh5.3.2之上,前端机安装同版本的Hadoop Client,Hadoop Client连接的集群是依靠配置文件指定的,配置文件存储目录为“/etc/hadoop/conf”,默认指向Hadoop线下集群。
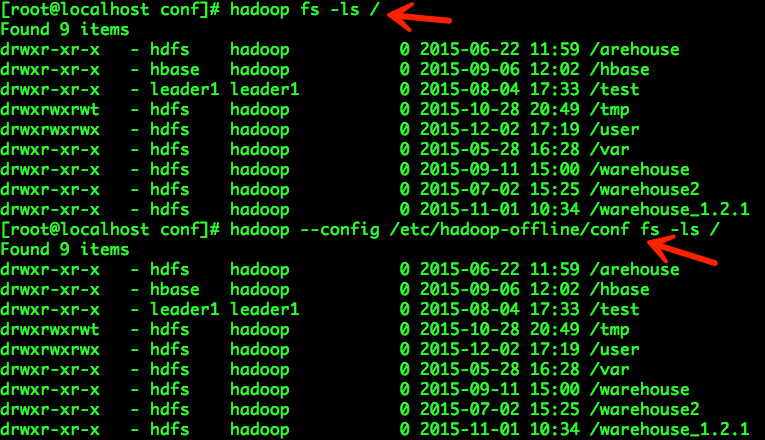
可以看出,访问HDFS需要通过“hadoop fs”,而hadoop命令选项“--config”支持指定配置文件目录,从而实现多个Hadoop HDFS集群之间的切换。我们的操作步骤如下:
a.建立Hadoop线上集群配置文件目录:mkdir -p /etc/hadoop-online/conf;
b.拷贝Hadoop线上集群配置文件至目录“/etc/hadoop-online/conf”;
c.建立Hadoop线下集群配置文件目录软链接,强化线下、线上属性:ln -s /etc/hadoop /etc/hadoop-offline;
访问Hadoop线下HDFS示例如下:
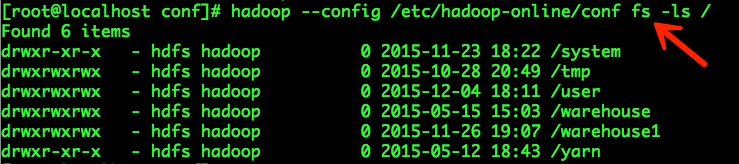
访问Hadoop线上HDFS示例如下:
总结:通过hadoop命令的选项“--config”可以指定不同的Hadoop集群配置文件,从而实现多个Hadoop集群之间的切换。
(2)MapReduce
用户提交MapReduce任务时,也可以通过指定配置文件目录的方式实现Hadoop线下集群与线上集群的切换,配置文件目录的建立方式与(1)同,不再赘述。
MapReduce任务的提交通常有以下两种方式,我们分别介绍。
a.使用hadoop jar的方式提交MapReduce任务;
提交MapReduce任务至Hadoop线下集群示例:
hadoop jar wordcount.jar --D mapreduce.job.name=wordcount_example_yurun -D mapreduce.job.queuename=hive -D mapreduce.job.reduces=3
hadoop --config /etc/hadoop-offline/conf jar wordcount.jar --D mapreduce.job.name=wordcount_example_yurun -D mapreduce.job.queuename=hive -D mapreduce.job.reduces=3
提交MapReduce任务至Hadoop线上集群示例:
hadoop --config /etc/hadoop-online/conf jar wordcount.jar --D mapreduce.job.name=wordcount_example_yurun -D mapreduce.job.queuename=hive -D mapreduce.job.reduces=3
b.使用java命令行的方式提交MapReduce任务;
提交MapReduce任务至Hadoop线下集群示例:
java -cp ./wordcount.jar:/etc/hadoop-offline/conf:/usr/lib/hadoop/lib/*:/usr/lib/hadoop/.//*:/usr/lib/hadoop-hdfs/./:/usr/lib/hadoop-hdfs/lib/*:/usr/lib/hadoop-hdfs/.//*:/usr/lib/hadoop-yarn/lib/*:/usr/lib/hadoop-yarn/.//*:/usr/lib/hadoop-mapreduce/lib/*:/usr/lib/hadoop-mapreduce/.//* com.weibo.dip.mr.WordCountExampleMain --D mapreduce.job.name=wordcount_example_yurun -D mapreduce.job.queuename=hive -D mapreduce.job.reduces=3
提交MapReduce任务至Hadoop线上集群示例:
java -cp ./wordcount.jar:/etc/hadoop-online/conf:/usr/lib/hadoop/lib/*:/usr/lib/hadoop/.//*:/usr/lib/hadoop-hdfs/./:/usr/lib/hadoop-hdfs/lib/*:/usr/lib/hadoop-hdfs/.//*:/usr/lib/hadoop-yarn/lib/*:/usr/lib/hadoop-yarn/.//*:/usr/lib/hadoop-mapreduce/lib/*:/usr/lib/hadoop-mapreduce/.//* com.weibo.dip.mr.WordCountExampleMain --D mapreduce.job.name=wordcount_example_yurun -D mapreduce.job.queuename=hive -D mapreduce.job.reduces=3
注意:提交MapReduce任务时需要将相关代码及依赖编译打包为一个Jar(Java,Hadoop相关依赖除外),为了避免可能出现的异常情况,不要在Jar中包含Hadoop相关的任何配置文件。
(3)Spark
Hadoop集群目前支持的Spark版本有两个:spark-1.2.0-cdh5.3.2、spark-1.5.1,均需要支持Hadoop集群线上环境与线下环境的切换。
Spark任务(这里仅讨论离线任务或批处理任务)的提交是通过“spark-submit”进行的,提交过程涉及到两个重要的环境变量:HADOOP_CONF_DIR、SPARK_CONF_DIR,分别用于指定Hadoop配置文件目录和Spark配置文件目录,实际上我们也是通过变更这两个环境变量的值实现Hadoop(Spark)集群之间的切换的。
因为spark-1.2.0-cdh5.3.2与spark-1.5.1之间的安装部署方式不同,两者集群之间的切换操作也略有不同。
spark-1.2.0-cdh5.3.2操作步骤如下:
注:spark-1.2.0-cdh5.3.2默认安装时的配置文件目录(SPARK_CONF_DIR)为“/etc/spark/conf”。
a.建立Spark线上环境配置文件目录:mkdir -p /etc/spark-online/conf;
b.拷贝Spark线上环境配置文件至目录:/etc/spark-online/conf;
c.建立/usr/bin/spark-submit软链接:ln -s /usr/bin/spark-submit /usr/bin/spark-1.2.0-offline-submit;
d.拷贝/usr/bin/spark-submit:cp /usr/bin/spark-submit /usr/bin/spark-1.2.0-online-submit;
e.修改/usr/bin/spark-1.2.0-online-submit,如下:
. /usr/lib/bigtop-utils/bigtop-detect-javahome
export HADOOP_CONF_DIR=/etc/hadoop-online/conf
export SPARK_CONF_DIR=/etc/spark-online/conf
exec /usr/lib/spark/bin/spark-submit "$@"
总结:spark-1.2.0-cdh5.3.2安装时已经将其指向Hadoop线下集群,这里仅仅需要为其建立一个软链接“/usr/bin/spark-1.2.0-offline-submit”,强化一下线下属性即可;/usr/bin/spark-1.2.0-online-submit则需要显示设置环境变量:HADOOP_CONF_DIR、SPARK_CONF_DIR,其中HADOOP_CONF_DIR指向Hadoop线上集群配置文件目录,SPARK_CONF_DIR指向Spark线上集群配置文件目录。
spark-1.2.0-cdh5.3.2提交任务至Hadoop线下集群示例:
spark-submit --master yarn-client --num-executors 3 --executor-memory 2g --driver-memory 1G --queue spark.app /usr/home/yurun/workspace/pyspark/1.2.0/examples/app/spark_app_min.py
spark-1.2.0-offline-submit --master yarn-client --num-executors 3 --executor-memory 2g --driver-memory 1G --queue spark.app /usr/home/yurun/workspace/pyspark/1.2.0/examples/app/spark_app_min.py
spark-1.2.0-cdh5.3.2提交任务至Hadoop线上集群示例:
spark-1.2.0-online-submit --master yarn-client --num-executors 3 --executor-memory 2g --driver-memory 1G --queue spark.app /usr/home/yurun/workspace/pyspark/1.2.0/examples/app/spark_app_min.py
spark-1.5.1操作步骤如下:
注:spark-1.5.1默认安装时的配置文件目录(SPARK_CONF_DIR)为“/usr/lib/spark-1.5.1-bin-2.5.0-cdh5.3.2/conf”。
a.建立/usr/lib/spark-1.5.1-bin-2.5.0-cdh5.3.2/bin/spark-submit的软链接:ln -s /usr/lib/spark-1.5.1-bin-2.5.0-cdh5.3.2/bin/spark-submit /usr/lib/spark-1.5.1-bin-2.5.0-cdh5.3.2/bin/spark-1.5.1-offline-submit;
b.修改/usr/lib/spark-1.5.1-bin-2.5.0-cdh5.3.2/bin/spark-submit,如下:
SPARK_HOME=/usr/lib/spark-1.5.1-bin-2.5.0-cdh5.3.2
# disable randomized hash for string in Python 3.3+
export PYTHONHASHSEED=0
exec "$SPARK_HOME"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"
c.建立/usr/lib/spark-1.5.1-bin-2.5.0-cdh5.3.2/bin/spark-1.5.1-offline-submit的软链接:ln -s /usr/lib/spark-1.5.1-bin-2.5.0-cdh5.3.2/bin/spark-1.5.1-offline-submit /usr/bin/spark-1.5.1-offline-submit;
d.建立Spark线上环境目录:mkdir -p /usr/lib/spark-1.5.1-bin-2.5.0-cdh5.3.2/online-conf/;
e.拷贝Spark线上环境配置文件至目录:/usr/lib/spark-1.5.1-bin-2.5.0-cdh5.3.2/online-conf/;
f.拷贝/usr/lib/spark-1.5.1-bin-2.5.0-cdh5.3.2/bin/spark-submit:cp /usr/lib/spark-1.5.1-bin-2.5.0-cdh5.3.2/bin/spark-submit /usr/lib/spark-1.5.1-bin-2.5.0-cdh5.3.2/bin/spark-1.5.1-online-submit
g.修改/usr/lib/spark-1.5.1-bin-2.5.0-cdh5.3.2/bin/spark-1.5.1-online-submit,如下:
SPARK_HOME=/usr/lib/spark-1.5.1-bin-2.5.0-cdh5.3.2
export HADOOP_CONF_DIR=/etc/hadoop-online/conf
export SPARK_CONF_DIR=/usr/lib/spark-1.5.1-bin-2.5.0-cdh5.3.2/online-conf
# disable randomized hash for string in Python 3.3+
export PYTHONHASHSEED=0
exec "$SPARK_HOME"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"
h.建立/usr/lib/spark-1.5.1-bin-2.5.0-cdh5.3.2/bin/spark-1.5.1-online-submit的软链接:ln -s /usr/lib/spark-1.5.1-bin-2.5.0-cdh5.3.2/bin/spark-1.5.1-online-submit /usr/bin/spark-1.5.1-online-submit。
spark-1.5.1提交任务至Hadoop线下集群示例:
spark-1.5.1-offline-submit --master yarn-client --num-executors 3 --executor-memory 2g --driver-memory 1G --queue spark.app /usr/home/yurun/workspace/pyspark/1.2.0/examples/app/spark_app_min.py
spark-1.5.1提交任务至Hadoop线上集群示例:
spark-1.5.1-online-submit --master yarn-client --num-executors 3 --executor-memory 2g --driver-memory 1G --queue hive /usr/home/yurun/workspace/pyspark/1.2.0/examples/app/spark_app_min.py
总结:spark-1.5.1实现集群环境之间的切换是通过设置三个环境变量实现的:SPARK_HOME、HADOOP_CONF_DIR、SPARK_CONF_DIR。
2.HDFS权限控制;
HDFS权限控制类似于Linux文件系统的权限控制,也是通过用户、用户组实现的。
用户需要以团队(组)为单位申请前端机的登录权限,如:
用户组:dip
用户名:yurun、tongwei
权限申请通过之后,需要执行以下三步:
(1)需要由管理员在前端机为其建立用户组,并将上述用户添加至该用户组,如:
sudo -s
groupadd dip;
usermod -a -G dip yurun;
usermod -a -G dip tongwei;
(2)需要由管理员在Hadoop线下集群与线上集群的Namenode、ResourceManager节点添加用户账号,如:
groupadd dip;
useradd yurun -s /sbin/nologin;
useradd tongwei -s /sbin/nologin;
usermod -a -G dip yurun;
usermod -a -G dip tongwei;
(3)需要由管理员在Hadoop(HDFS)线下集群与线上集群中以用户组为单位建立工作目录,如:
su hdfs
hadoop fs -mkdir /user/dip
hadoop fs -chown -R yurun:dip /user/dip
hadoop fs -chmod -R 770 /user/dip
通过上述三步,用户(组)拥有一个独立的工作目录(/user/dip),用户(组)可自行管理目录中的内容。
3.YARN资源隔离;
YARN资源隔离是通过YARN Scheduler Queue实现的,以用户组为单位创建队列,并设置该队列允许提交任务的用户、最大资源使用量、最多同时运行的任务数等。
我们在Hadoop集群资源中开辟队列“thirdparty”用于开放计算,然后以用户组为单位建立相应的子队列,如用户组topweibo、datacubic的子队列分别为thirdparty.topweibo、thirdparty.datacubic,分别为这两个子队列设置最小资源、最大资源、允许同时运行的任务数、允许提交应用的用户(组)、允许管理应用的用户(组)等,如下:
<queue name="thirdparty">
<minResources>2080768 mb, 1166 vcores</minResources>
<maxResources>2080768 mb, 1166 vcores</maxResources>
<minSharePreemptionTimeout>60</minSharePreemptionTimeout>
<weight>10.0</weight>
<schedulingPolicy>fair</schedulingPolicy>
<queue name="topweibo">
<minResources>416153 mb, 233 vcores</minResources>
<maxResources>416153 mb, 233 vcores</maxResources>
<maxRunningApps>50</maxRunningApps>
<aclSubmitApps> topweibo</aclSubmitApps>
<aclAdministerApps>hdfs topweibo</aclAdministerApps>
</queue>
<queue name="datacubic">
<minResources>1248460 mb, 699 vcores</minResources>
<maxResources>1248460 mb, 699 vcores</maxResources>
<maxRunningApps>50</maxRunningApps>
<aclSubmitApps>xinqi datacubic</aclSubmitApps>
<aclAdministerApps>hdfs datacubic</aclAdministerApps>
</queue>
</queue>
经过上述配置之后,用户提交应用(MapReduce、Spark)时均需要指定提交的队列,如:
hadoop --config /etc/hadoop-offline/conf jar wordcount.jar --D mapreduce.job.name=wordcount_example_yurun -D mapreduce.job.queuename=thirdparty.topweibo -D mapreduce.job.reduces=3
java -cp ./wordcount.jar:/etc/hadoop-online/conf:/usr/lib/hadoop/lib/*:/usr/lib/hadoop/.//*:/usr/lib/hadoop-hdfs/./:/usr/lib/hadoop-hdfs/lib/*:/usr/lib/hadoop-hdfs/.//*:/usr/lib/hadoop-yarn/lib/*:/usr/lib/hadoop-yarn/.//*:/usr/lib/hadoop-mapreduce/lib/*:/usr/lib/hadoop-mapreduce/.//* com.weibo.dip.mr.WordCountExampleMain --D mapreduce.job.name=wordcount_example_yurun -D mapreduce.job.queuename=hive -D mapreduce.job.reduces=3
spark-1.5.1-offline-submit --master yarn-client --num-executors 3 --executor-memory 2g --driver-memory 1G --queue thirdparty.topweibo /usr/home/yurun/workspace/pyspark/1.2.0/examples/app/spark_app_min.py
解决这三个问题之后,可以认为已基本满足开放计算的基本条件,目前已经开始投入实际环境中使用,后续会根据业务场景不断完善。
- 开放计算平台——数据仓库(Hive)权限控制
平台数据仓库使用Hive进行构建,通过调研决定使用“SQL Standards Based Authorization in HiveServer2”对用户提交的SQL进行权限控制,也可根据实际情况选 ...
- KubeEdge v0.2发布,全球首个K8S原生的边缘计算平台开放云端代码
KubeEdge开源背景 KubeEdge在18年11月24日的上海KubeCon上宣布开源,技术圈曾掀起一阵讨论边缘计算的风潮,从此翻开了边缘计算和云计算联动的新篇章. KubeEdge即Kube+ ...
- 手把手教您将 libreoffice 移植到函数计算平台
LibreOffice 是由文档基金会开发的自由及开放源代码的办公室套件.LibreOffice 套件包含文字处理器.电子表格.演示文稿程序.矢量图形编辑器和图表工具.数据库管理程序及创建和编辑数学公 ...
- 基于olami开放语义平台的微信小程序遥知之源码实现
概述 实现一个智能生活信息查询的小秘书功能,支持查天气.新闻.日历.汇率.笑话.故事.百科.诗词.邮编.区号.菜谱.股票.节目预告,还支持闲聊.算24点.数学计算.单位换算.购物.搜索等功能. 使用方 ...
- 利用Azure Functions和k8s构建Serverless计算平台
题记:昨晚在一个技术社区直播分享了"利用Azure Functions和k8s构建Serverless计算平台"这一话题.整个分享分为4个部分:Serverless概念的介绍.Az ...
- 大数据和Hadoop平台介绍
大数据和Hadoop平台介绍 定义 大数据是指其大小和复杂性无法通过现有常用的工具软件,以合理的成本,在可接受的时限内对其进行捕获.管理和处理的数据集.这些困难包括数据的收入.存储.搜索.共享.分析和 ...
- ITTC数据挖掘平台介绍(七)强化的数据库, 虚拟化,脚本编辑器
一. 前言 好久没有更新博客了,最近一直在忙着找工作,目前差不多尘埃落定.特别期待而且准备的都很少能成功,反而是没怎么在意的最终反而能拿到,真是神一样的人生. 言归正传,一直以来,数据挖掘系统的数据类 ...
- 大数据计算平台Spark内核解读
1.Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目.随着 Spark在大数据计算领域的暂露头角,越来越多 ...
- PHP.2-LAMP平台介绍及网站的工作原理
LAMP平台介绍及网站的工作原理 1.HTTP协议 URL(UniformResourceLocator)统一资源定位符,就是网页地址的意思.[格式:协议://主机.端口.文件.附加资源] ##URL ...
随机推荐
- ASP.NET MVC 自我总结的便捷开发实例
前言 工作了这么久了,接触ASP.NET MVC已经很久了,一直都想总结一下它的一些实用的,经常使用的一些技巧,但是因为一直都很懒,也不想总结,所以一直都没有好好写出来,趁着现在有这种冲劲,那么就先把 ...
- Android手势解锁, 九宫格解锁
给大家介绍一个很好用的手势解锁控件ShapleLocker, 废话不多先上效果图: 这是一个第三方库, 可自己根据UI需求替换图标: 圆圈, 小箭头等等.. github地址: http://pane ...
- CSS之关于clearfix--清除浮动
一,什么是.clearfix 你只要到Google或者Baidu随便一搜"css清除浮动",就会发现很多网站都讲到"盒子清除内部浮动时可以用到.clearfix" ...
- css - a:hover变色问题
今天在帮我们学校做网站的时候,由于在css这里不是很擅长,过程中发现一个问题,a:hover的时候,字体的颜色不变.后来才发现将a和div的嵌套的问题, 我的css代码为: .left_box .lb ...
- Linked Server for SQL Server 2012(x64) to Oracle Database 12c(x64)
因为把两台数据库装了同一台机机器上,所以没有安装oracle Client的部分,Oracle部分使用netca创建的Net Service Name,使用tnsping以及登入方式的确认用户权限的以 ...
- 关于java中for和foreach循环
for循环中的循环条件中的变量只求一次值!具体看最后的图片 foreach语句是java5新增,在遍历数组.集合的时候,foreach拥有不错的性能. foreach是for语句的简化,但是forea ...
- Lost connection to MySQL server at ‘reading initial communication packet', system error: 0 mysql远程连接问题
在用Navicat for MySQL远程连接mysql的时候,出现了 Lost connection to MySQL server at ‘reading initial communicatio ...
- ubuntu1404下Apache2.4错误日志error.log路径位置
首先打开/etc/apache2路径下的apache2.conf文件,找到ErrorLog如下 ErrorLog ${APACHE_LOG_DIR}/error.log 这里{APACHE_LOG_D ...
- 对象序列化XML
/// <summary>/// 对象序列化XML/// </summary>/// <param name="type">类型</par ...
- oracle 自动增长
在SQLSERVER和MYSQL里面自动增长字段直接设置就可以.在ORACLE里面就复杂多了.特别是我这样的初学者,不过网络是最好的老师,看了很多相关介绍,本人使用的是使用触发器.具体如下: 首先要创 ...