FP树(附)
Apriori算法和FPTree算法都是数据挖掘中的关联规则挖掘算法,处理的都是最简单的单层单维布尔关联规则。
转自http://blog.csdn.net/sealyao/article/details/6460578
Apriori算法
Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法。是基于这样的事实:算法使用频繁项集性质的先验知识。Apriori使用一种称作逐层搜索的迭代方法,k-项集用于探索(k+1)-项集。首先,找出频繁1-项集的集合。该集合记作L1。L1用于找频繁2-项集的集合L2,而L2用于找L3,如此下去,直到不能找到频繁k-项集。找每个Lk需要一次数据库扫描。
这个算法的思路,简单的说就是如果集合I不是频繁项集,那么所有包含集合I的更大的集合也不可能是频繁项集。
|
TID |
List of item_ID’s |
|
T100 T200 T300 T400 T500 T600 T700 T800 T900 |
I1,I2,I5 I2,I4 I2,I3 I1,I2,I4 I1,I3 I2,I3 I1,I3 I1,I2,I3,I5 I1,I2,I3 |
算法的基本过程如下图:
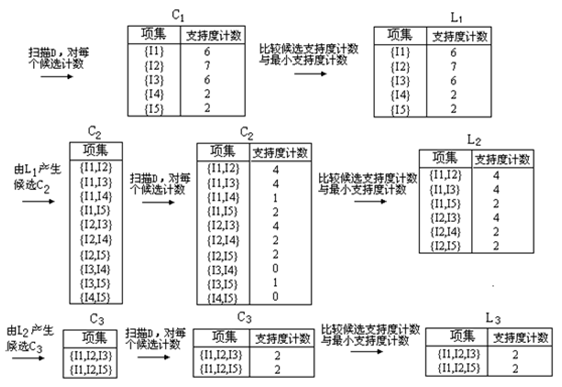
首先扫描所有事务,得到1-项集C1,根据支持度要求滤去不满足条件项集,得到频繁1-项集。
下面进行递归运算:
已知频繁k-项集(频繁1-项集已知),根据频繁k-项集中的项,连接得到所有可能的K+1_项,并进行剪枝(如果该k+1_项集的所有k项子集不都能满足支持度条件,那么该k+1_项集被剪掉),得到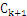 项集,然后滤去该
项集,然后滤去该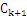 项集中不满足支持度条件的项得到频繁k+1-项集。如果得到的
项集中不满足支持度条件的项得到频繁k+1-项集。如果得到的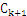 项集为空,则算法结束。
项集为空,则算法结束。
连接的方法:假设 项集中的所有项都是按照相同的顺序排列的,那么如果
项集中的所有项都是按照相同的顺序排列的,那么如果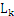 [i]和
[i]和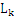 [j]中的前k-1项都是完全相同的,而第k项不同,则
[j]中的前k-1项都是完全相同的,而第k项不同,则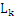 [i]和
[i]和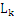 [j]是可连接的。比如
[j]是可连接的。比如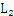 中的{I1,I2}和{I1,I3}就是可连接的,连接之后得到{I1,I2,I3},但是{I1,I2}和{I2,I3}是不可连接的,否则将导致项集中出现重复项。
中的{I1,I2}和{I1,I3}就是可连接的,连接之后得到{I1,I2,I3},但是{I1,I2}和{I2,I3}是不可连接的,否则将导致项集中出现重复项。
关于剪枝再举例说明一下,如在由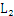 生成
生成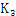 的过程中,列举得到的3_项集包括{I1,I2,I3},{I1,I3,I5},{I2,I3,I4},{I2,I3,I5},{I2,I4,I5},但是由于{I3,I4}和{I4,I5}没有出现在
的过程中,列举得到的3_项集包括{I1,I2,I3},{I1,I3,I5},{I2,I3,I4},{I2,I3,I5},{I2,I4,I5},但是由于{I3,I4}和{I4,I5}没有出现在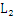 中,所以{I2,I3,I4},{I2,I3,I5},{I2,I4,I5}被剪枝掉了。
中,所以{I2,I3,I4},{I2,I3,I5},{I2,I4,I5}被剪枝掉了。
海量数据下,Apriori算法的时空复杂度都不容忽视。
空间复杂度:如果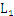 数量达到
数量达到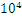 的量级,那么
的量级,那么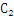 中的候选项将达到
中的候选项将达到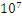 的量级。
的量级。
时间复杂度:每计算一次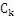 就需要扫描一遍数据库。
就需要扫描一遍数据库。
FP-Tree算法
FPTree算法:在不生成候选项的情况下,完成Apriori算法的功能。
FPTree算法的基本数据结构,包含一个一棵FP树和一个项头表,每个项通过一个结点链指向它在树中出现的位置。基本结构如下所示。需要注意的是项头表需要按照支持度递减排序,在FPTree中高支持度的节点只能是低支持度节点的祖先节点。
另外还要交代一下FPTree算法中几个基本的概念:
FP-Tree:就是上面的那棵树,是把事务数据表中的各个事务数据项按照支持度排序后,把每个事务中的数据项按降序依次插入到一棵以NULL为根结点的树中,同时在每个结点处记录该结点出现的支持度。
条件模式基:包含FP-Tree中与后缀模式一起出现的前缀路径的集合。也就是同一个频繁项在PF树中的所有节点的祖先路径的集合。比如I3在FP树中一共出现了3次,其祖先路径分别是{I2,I1:2(频度为2)},{I2:2}和{I1:2}。这3个祖先路径的集合就是频繁项I3的条件模式基。
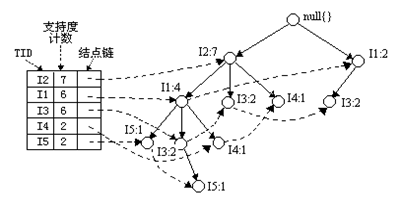
条件树:将条件模式基按照FP-Tree的构造原则形成的一个新的FP-Tree。比如上图中I3的条件树就是:
1、 构造项头表:扫描数据库一遍,得到频繁项的集合F和每个频繁项的支持度。把F按支持度递降排序,记为L。
2、 构造原始FPTree:把数据库中每个事物的频繁项按照L中的顺序进行重排。并按照重排之后的顺序把每个事物的每个频繁项插入以null为根的FPTree中。如果插入时频繁项节点已经存在了,则把该频繁项节点支持度加1;如果该节点不存在,则创建支持度为1的节点,并把该节点链接到项头表中。
3、 调用FP-growth(Tree,null)开始进行挖掘。伪代码如下:
procedure FP_growth(Tree, a)
if Tree 含单个路径P then{
for 路径P中结点的每个组合(记作b)
产生模式b U a,其支持度support = b 中结点的最小支持度;
} else {
for each a i 在Tree的头部(按照支持度由低到高顺序进行扫描){
产生一个模式b = a i U a,其支持度support = a i .support;
构造b的条件模式基,然后构造b的条件FP-树Treeb;
if Treeb 不为空 then
调用 FP_growth (Treeb, b);
}
}
FP-growth是整个算法的核心,再多啰嗦几句。
FP-growth函数的输入:tree是指原始的FPTree或者是某个模式的条件FPTree,a是指模式的后缀(在第一次调用时a=NULL,在之后的递归调用中a是模式后缀)
FP-growth函数的输出:在递归调用过程中输出所有的模式及其支持度(比如{I1,I2,I3}的支持度为2)。每一次调用FP_growth输出结果的模式中一定包含FP_growth函数输入的模式后缀。
我们来模拟一下FP-growth的执行过程。
1、 在FP-growth递归调用的第一层,模式前后a=NULL,得到的其实就是频繁1-项集。
2、 对每一个频繁1-项,进行递归调用FP-growth()获得多元频繁项集。
下面举两个例子说明FP-growth的执行过程。
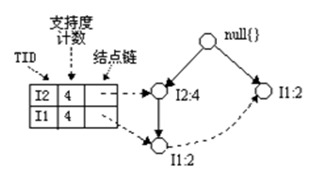
1、I5的条件模式基是(I2 I1:1), (I2 I1 I3:1),I5构造得到的条件FP-树如下。然后递归调用FP-growth,模式后缀为I5。这个条件FP-树是单路径的,在FP_growth中直接列举{I2:2,I1:2,I3:1}的所有组合,之后和模式后缀I5取并集得到支持度>2的所有模式:{ I2 I5:2, I1 I5:2, I2 I1 I5:2}。
2、I5的情况是比较简单的,因为I5对应的条件FP-树是单路径的,我们再来看一下稍微复杂一点的情况I3。I3的条件模式基是(I2 I1:2), (I2:2), (I1:2),生成的条件FP-树如左下图,然后递归调用FP-growth,模式前缀为I3。I3的条件FP-树仍然是一个多路径树,首先把模式后缀I3和条件FP-树中的项头表中的每一项取并集,得到一组模式{I2 I3:4, I1 I3:4},但是这一组模式不是后缀为I3的所有模式。还需要递归调用FP-growth,模式后缀为{I1,I3},{I1,I3}的条件模式基为{I2:2},其生成的条件FP-树如右下图所示。这是一个单路径的条件FP-树,在FP_growth中把I2和模式后缀{I1,I3}取并得到模式{I1 I2 I3:2}。理论上还应该计算一下模式后缀为{I2,I3}的模式集,但是{I2,I3}的条件模式基为空,递归调用结束。最终模式后缀I3的支持度>2的所有模式为:{ I2 I3:4, I1 I3:4, I1 I2 I3:2}
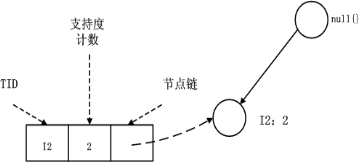
图1 图2
|
item |
条件模式基 |
条件FP-树 |
产生的频繁模式 |
|
I5 I4 I3 I1 |
{(I2 I1:1),(I2 I1 I3:1) {(I2 I1:1), (I2:1)} {(I2 I1:2), (I2:2), (I1:2)} {(I2:4)} |
<I2:2, I1:2> <I2:2> <I2:4, I1:2>, <I1:2> <I2:4> |
I2 I5:2, I1 I5:2, I2 I1 I5:2 I2 I4:2 I2 I3:4, I1 I3:4, I2 I1 I3:2 I2 I1:4 |
FP-growth算法比Apriori算法快一个数量级,在空间复杂度方面也比Apriori也有数量级级别的优化。但是对于海量数据,FP-growth的时空复杂度仍然很高,可以采用的改进方法包括数据库划分,数据采样等等。
FP树(附)的更多相关文章
- POJ 2104 K-th Number(主席树——附讲解)
Description You are working for Macrohard company in data structures department. After failing your ...
- FP-growth算法发现频繁项集(一)——构建FP树
常见的挖掘频繁项集算法有两类,一类是Apriori算法,另一类是FP-growth.Apriori通过不断的构造候选集.筛选候选集挖掘出频繁项集,需要多次扫描原始数据,当原始数据较大时,磁盘I/O次数 ...
- FP并行算法的几个相关方向
1 集群系统中的 FP-tree 并行算法(many for one一个任务 还是 云计算one for many多个任务?) 计算机集群系统利用网络把一组具有高性能的工作站或者 PC 机按一定的结构 ...
- FP - growth 发现频繁项集
FP - growth是一种比Apriori更高效的发现频繁项集的方法.FP是frequent pattern的简称,即常在一块儿出现的元素项的集合的模型.通过将数据集存储在一个特定的FP树上,然后发 ...
- ZOJ 2112 Dynamic Rankings(主席树の动态kth)
题目链接:http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=2112 The Company Dynamic Rankings ...
- Frequent Pattern 挖掘之二(FP Growth算法)(转)
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达到这样的效果,它采用了一种简洁的数据结 ...
- FP—Growth算法
FP_growth算法是韩家炜老师在2000年提出的关联分析算法,该算法和Apriori算法最大的不同有两点: 第一,不产生候选集,第二,只需要两次遍历数据库,大大提高了效率,用31646条测试记录, ...
- 关联规则算法之FP growth算法
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达到这样的效果,它采用了一种简洁的数据结 ...
- FP Tree算法原理总结
在Apriori算法原理总结中,我们对Apriori算法的原理做了总结.作为一个挖掘频繁项集的算法,Apriori算法需要多次扫描数据,I/O是很大的瓶颈.为了解决这个问题,FP Tree算法(也称F ...
随机推荐
- 解决使用 Composer 的时候提示输入 Token
Could not fetch https://api.github.com/repos/RobinHerbots/jquery.inputmask/contents/bower.json?ref=0 ...
- php 用户验证的简单示例
发布:thebaby 来源:net [大 中 小] 本文介绍下,在php中,进行用户登录验证的例子,这个是基于WWW-Authenticate登录验证的实例,有需要的朋友参考下吧. 大家是 ...
- m2e插件的新下载地址
今天在按照<Maven实战>这本书给eclipse配置maven的m2eclipse插件的时候发现,书中写的老的下载地址http://m2eclipse.sonatype.org/site ...
- Win2008 R2 IIS7.5+PHP5(FastCGI)+MySQL5环境搭建教程
现在很多朋友想尝试win2008 r2来跑web服务器,跟win2003相比界面差别有点大,有些人可能不太习惯,不过以后是趋势啊,这里简单分享下,方便需要的朋友 准备篇 一.环境说明: 操作系统:Wi ...
- python27读书笔记0.2
# -*- coding:utf-8 -*- ##s.partition(d)##Searches string s for the first occurrence of some delimite ...
- 换一换js
(function(){ var tit = $("#changes"), con = $("#wday>ul"), page = con.length, ...
- Linux 串行终端,虚拟终端,伪终端,控制终端,控制台终端的理解
转自Linux 串行终端,虚拟终端,伪终端,控制终端,控制台终端的理解 终端:输入和输出设备(键盘 + 显示器). 串行终端:与机器的串口对应,每一个串口对应一个串行终端,串口对应的是物理终端. 虚拟 ...
- 1182-IP地址转换
描述 给定一个点分十进制的IP地址,把这个IP地址转换为二进制形式. 输入 输入只有一行,一个点分十进制的IP地址 包括四个正整数,用三个.分开,形式为a.b.c.d 其中0<=a,b,c,d& ...
- explain 用法详解
explain显示了mysql如何使用索引来处理select语句以及连接表.可以帮助选择更好的索引和写出更优化的查询语句. 使用方法,在select语句前加上explain就可以了: 如: expla ...
- mysql通过frm+ibd文件还原data
此方法只适合innodb_file_per_table = 1 当误删除ibdata 该怎么办? 如下步骤即可恢复: 1.准备工作 1)准备一台纯洁的mysql环境[从启动到现在没有 ...